Outliers Anomaly Detection
Machine Learning Outliers Anomaly Detection in TrackMe
TrackMe implements Machine Learning Outliers Anomaly detection in every component, from the feeds tracking to the monitoring of scheduled activity in Splunk, based on the following concepts:
TrackMe relies on the Splunk Machine Learning Toolkit and the Python Scientific Packages with its own custom logic and workflow which orchestrates the lifecycle of anomaly detection in the product
We use the
applyandfitcommands from the toolkit and orchestrate their usage when entities are discovered and maintained; thedensity functionis used for anomaly detection calculation purposesTrackMe orchestrates the Anomaly Detection workflow in two essential steps: the ML models generation and training (
mltrain), and the ML models rendering phase (mlmonitor) where TrackMe verifies the Anomaly detection status for a given entityDepending on the TrackMe
component, ML models are generated automatically using metrics that are relevant for the component activity. Models can be created, deleted, and customized easily to change the model behaviors if necessarySee the following white paper for a great use case around Machine Learning: Use TrackMe to detect abnormal events count drop in Splunk feeds
Hint
ML models learn over time from historical data
ML detection in TrackMe requires historical data and gets more accurate over time
Depending on the settings, this can require up to several weeks or months of historical data with the most granular parameters
Historical data translates to the metrics stored in TrackMe’s metric store indexes, not the raw data itself
Metrics start to get generated as soon as TrackMe discovers and starts to maintain an entity
While TrackMe learns about the data by training ML models, it applies various safeguards to avoid generating false positive alerts
Hint
ML confidence (new in TrackMe 2.0.72)
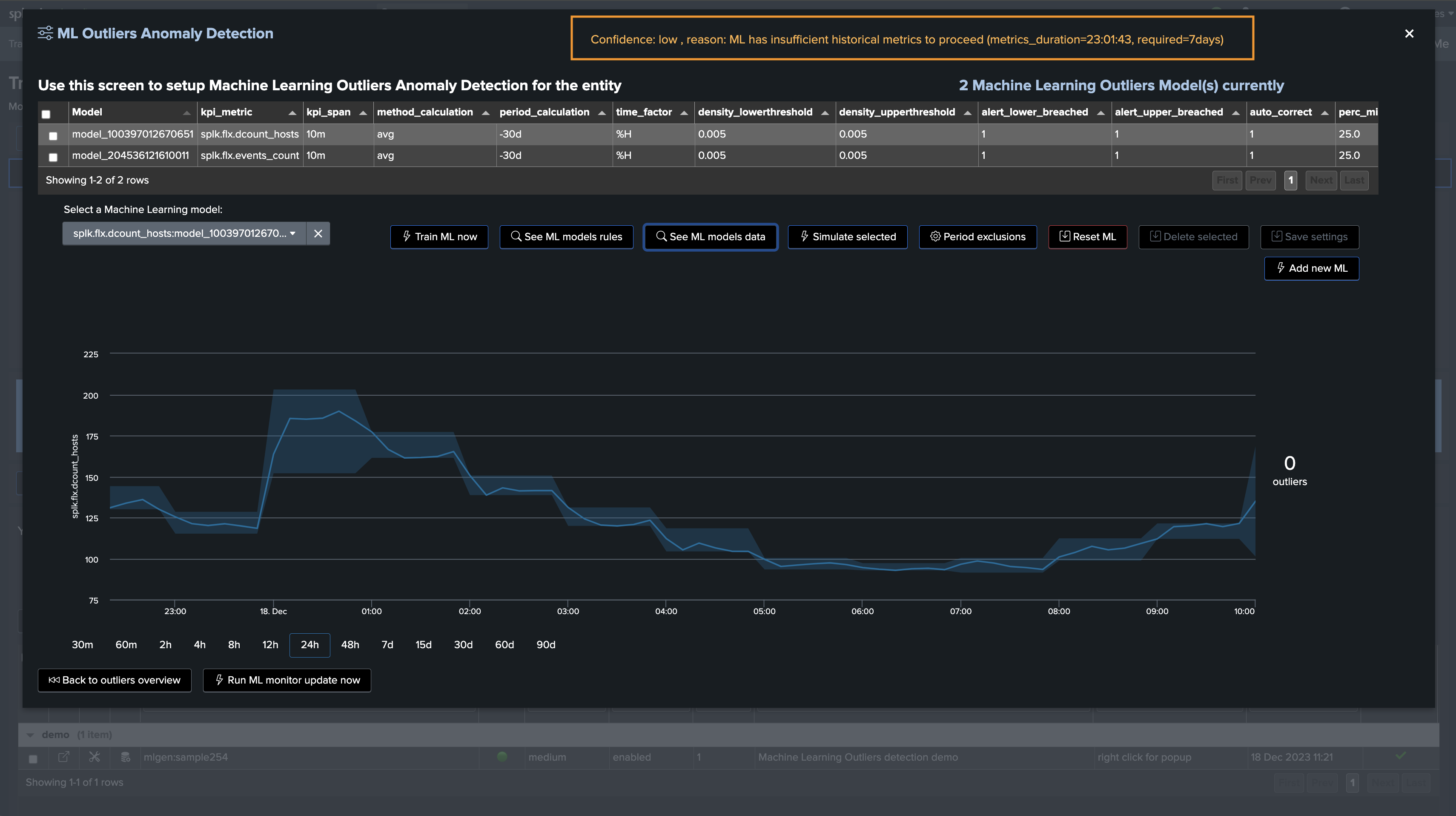
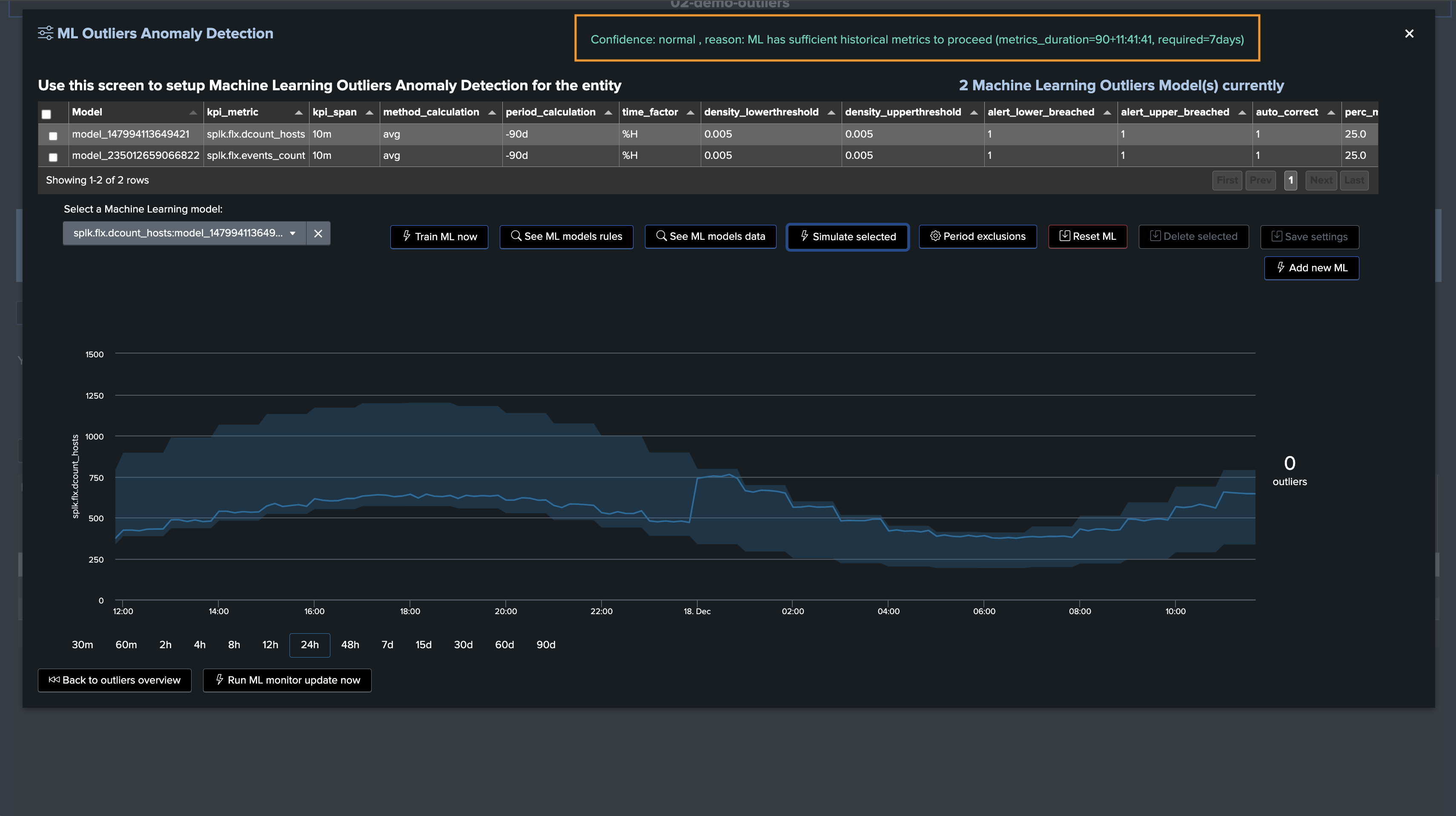
Since TrackMe 2.0.72, ML models have a confidence level which is calculated based on the number of days of historical data available for the models training
By default, TrackMe defines a minimal requirement of 7 days before the confidence level is set to
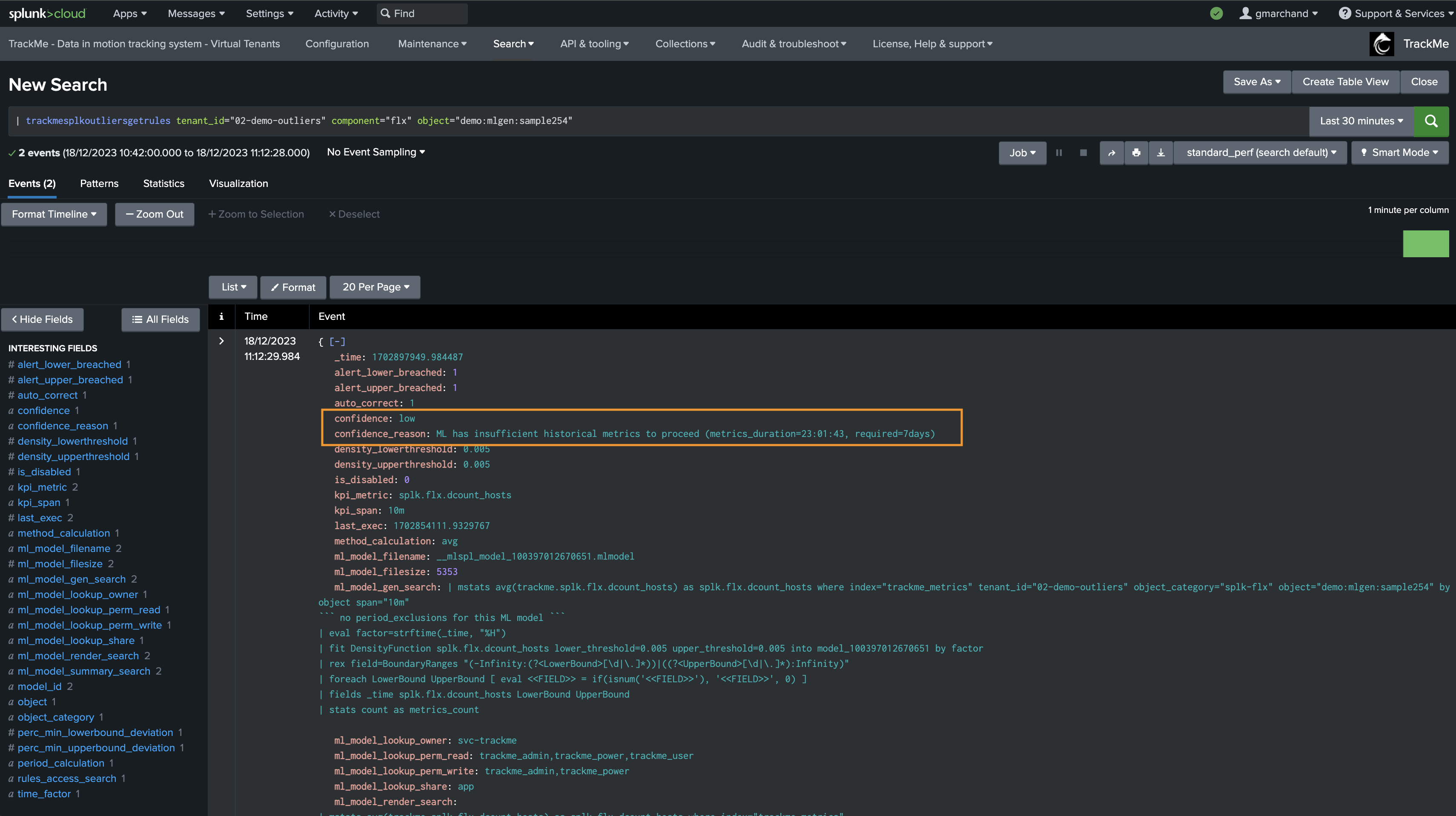
normal, otherwise it is set tolowThe confidence level and confidence_reason are stored in the rules KVstore collection, used while rendering models and also displayed in the Manage Outliers screen
The minimal number of days of historical metrics to define the confidence level to
normalis driven by a system-wide configuration option calledsplk_outliers_min_days_history
Hint
Time factor “none” for non-seasonality driven outliers (new in TrackMe 2.0.72)
Since TrackMe 2.0.72, ML models can be set with the
time_factordefined tononeThis enables TrackMe’s outlier calculations to exclude seasonal concepts; in some cases, this can better address KPIs which are not driven by seasonality
This can be set on a per-entity/model basis, or also chosen as the default model setting when TrackMe initiates ML models (option:
splk_outliers_detection_timefactor_default)
Hint
TrackMe 2.0.84 Outliers evolutions and enhancements
In TrackMe 2.0.84, we have released major enhancements to the Outliers engine; the following notes describe the most important changes
splunk-system-user and private ownership: ML Models are now owned by the splunk-system-user and private; this prevents having the models showing up in Splunk Web or the Splunk App for lookup editing, as well as increasing Splunk API response time when loading a large number of lookups
schema-upgrade: TrackMe via its schema upgrade process will automatically reassign existing ML models within 5 minutes of the upgrade
Improved Outliers endpoints and custom commands: TrackMe’s Outliers-related endpoints have been improved with better, more sophisticated, smarter, and more efficient code! Training and rendering Outliers TrackMe commands are notably improved with enhanced outputs and behaviors
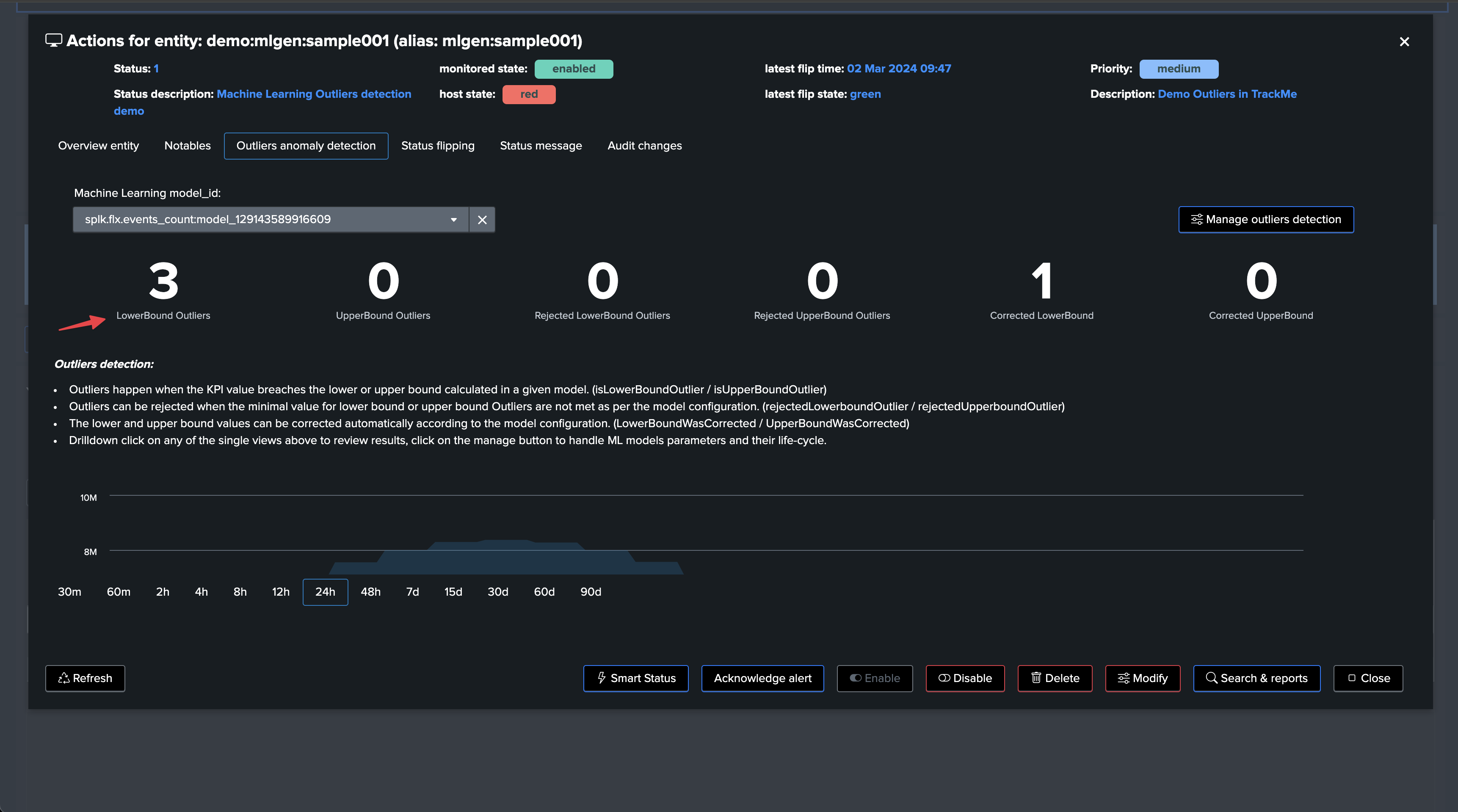
Minimal thresholds for LowerBound and UpperBound Outliers: You can now, on a per-model basis, define minimal threshold values for LowerBound and UpperBound outliers; values not respecting these thresholds are rejected automatically
Outliers investigations and management user interfaces: Outliers-related user interfaces have been improved to provide more visibility. This includes single views showing the distinction between LowerBound and UpperBound outliers, rejected Outliers, and corrected Outliers for each category
True context Simulation model training: TrackMe’s Outliers simulation now runs in
true context; this means that when you run a simulation, TrackMe trains a simulation model which 100% respects the live model behaviors. This provides a true context and prevents any deviation or inconsistency compared with results in the live Outliers viewAutomated ML training at the backend level when TrackMe calls rendering functions: TrackMe now automatically trains an ML model when it calls the rendering phase if it detects that the model is out of date and has not been recently updated. The maximum number of days since last training is controlled by a system-wide parameter
splk_outliers_max_days_since_last_train_default(15 days by default)Orphan ML records and ML models cleanup: TrackMe now automatically cleans up orphan ML records, as well as orphan ML models. This is controlled by a new health global tracker called
trackme_general_health_managerwhich runs daily. This job handles global health-related tasks for all TrackMe tenantsBulk actions: Various key actions for Outliers management can be performed in bulk via the user interface: reset Outliers status, enable/disable, run ML train, and ML monitor operations
Hint
TrackMe 2.0.89 Using custom algorithms, fit and apply extra parameters, additional selectable time periods and customizable boundaries extraction
In TrackMe 2.0.89, we have released various additional capabilities, notably for customers with advanced Machine Learning requirements or practice
Custom algorithms: You can define custom algorithms at the global configuration level (Configuration UI). These algorithms become available for selection when creating or updating ML models, and you can also define the default algorithm to use when TrackMe initiates ML models
boundaries extraction macro: TrackMe now refers to a Splunk macro for the extraction of the boundaries. To address any requirements, you can also add custom boundaries extraction macros and influence the default macro used when creating or updating ML models
fit extra parameters: You can define extra parameters for the
fitcommand, defined by default and/or modified per ML model. With this feature, you can define extra parameters allowed by the Splunk MLTK. For more information, see: https://docs.splunk.com/Documentation/MLApp/latest/User/Algorithms (An example of usage: you can define the extra parameters toexclude_dist="beta"to exclude the Beta distributions in the density function)apply extra parameters: Similarly, you can define extra parameters for the
applycommand, defined by default and/or modified per ML modeladditional time periods: More period options have been added, so you can extend the training of models for long time ranges beyond 90 days
Hint
TrackMe 2.1.10 Machine Learning Outliers selective enablement and UI charting fix
In TrackMe 2.1.10, we have released the capability to selectively enable or disable Machine Learning Outliers on a per-tenant AND component basis
This relies on the
mloutliersandmloutliers_allowlistparameters; the allowlist parameter permits restricting the list of components for which Machine Outliers enablement appliesAs well, we have fixed a remaining UI issue that was leading to charting not loading under some circumstances
Data Seasonality and Behaviors
In most cases, data have typical patterns which we can eventually recognize when running investigations.
The situation is, however, more complex when it comes to automating this recognition. Machine Learning and current major progress in AI are leading the way through new powerful ways to tackle these challenges.
Note
Generating samples for outliers detection
You can find, download and use with no restrictions the following content: https://github.com/trackme-limited/mlgen-python
We use this content to generate samples with seasonality concepts for the purposes of development, qualification, and documentation
Sample pattern over past 30 days, seasonality by weekdays with higher activity during working hours:
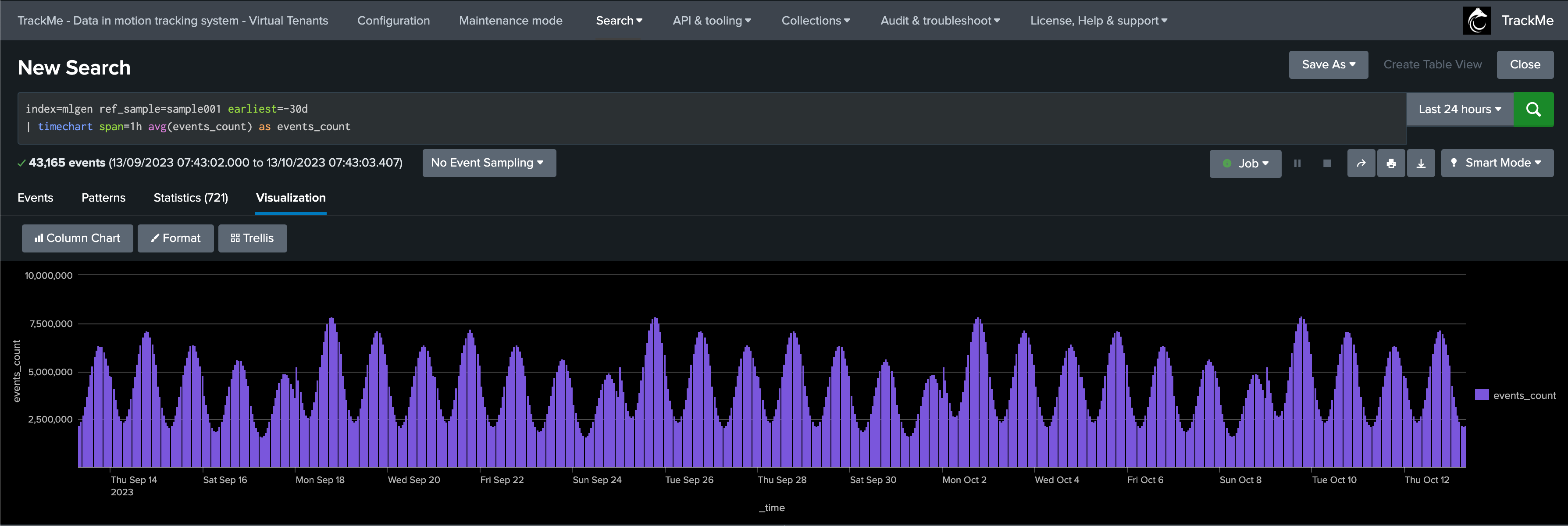
Data Not Driven by Seasonality
In some cases, applying seasonal concepts to the data may not be the best approach. KPIs with no variation depending on weekdays or hours are good examples.
Since TrackMe 2.0.72, ML models can be set with the time_factor defined to none; this enables TrackMe’s outlier calculations to exclude seasonal concepts:
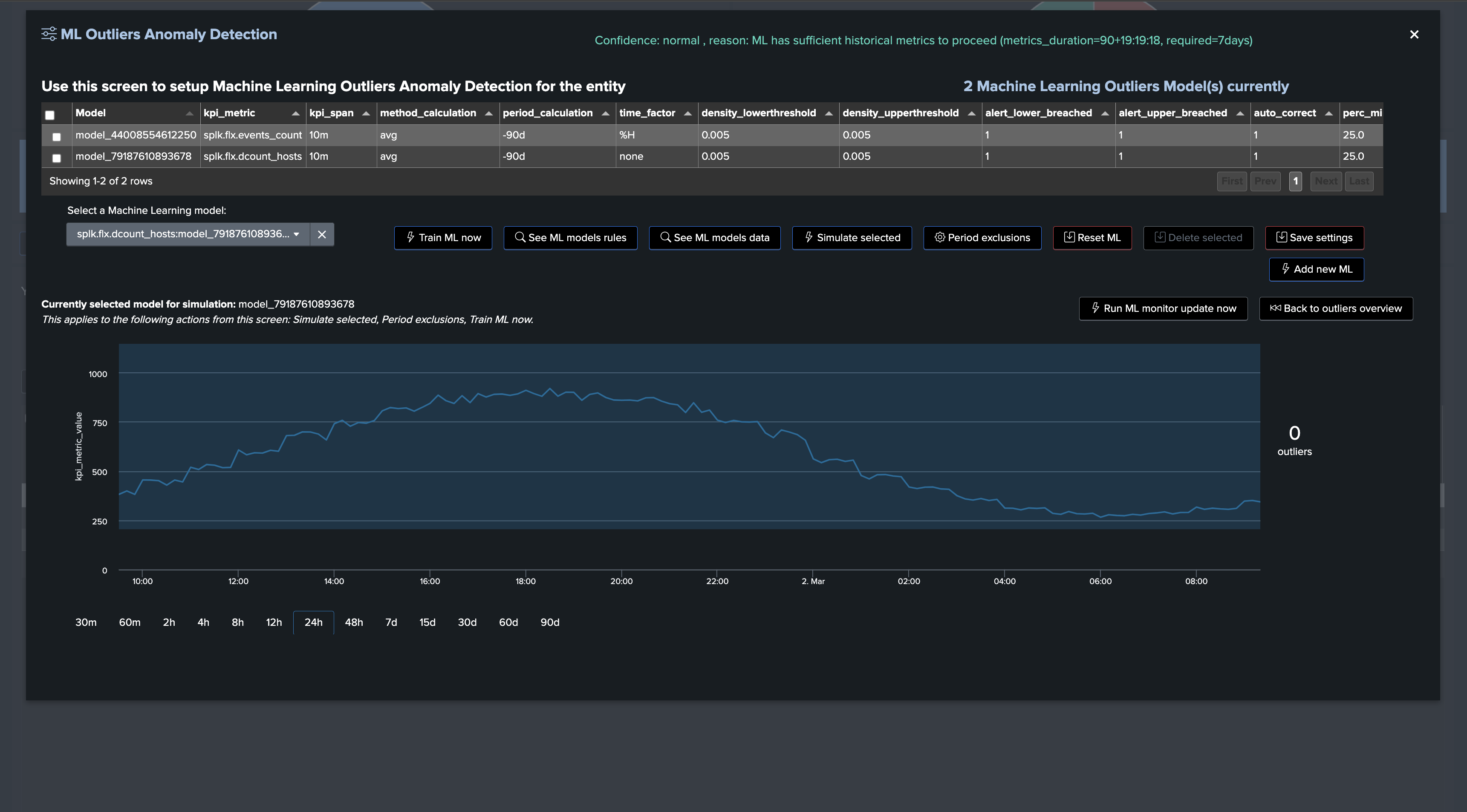
Confidence Level
Since TrackMe 2.0.72, TrackMe establishes a confidence level when training ML models; this confidence level can be:
low: TrackMe maintains ML Outliers for training and rendering purposes, but the Outliers status will not influence the entity statusnormal: TrackMe maintains ML Outliers for training and rendering purposes, and the Outliers status will influence the entity status
The value of confidence as well as confidence_reason are stored in the rules KVstore collection; it can be easily viewed in the Manage Outliers screen as well as by accessing the rules:
Minimal and Maximum Thresholds for LowerBound and UpperBound Outliers Breaches
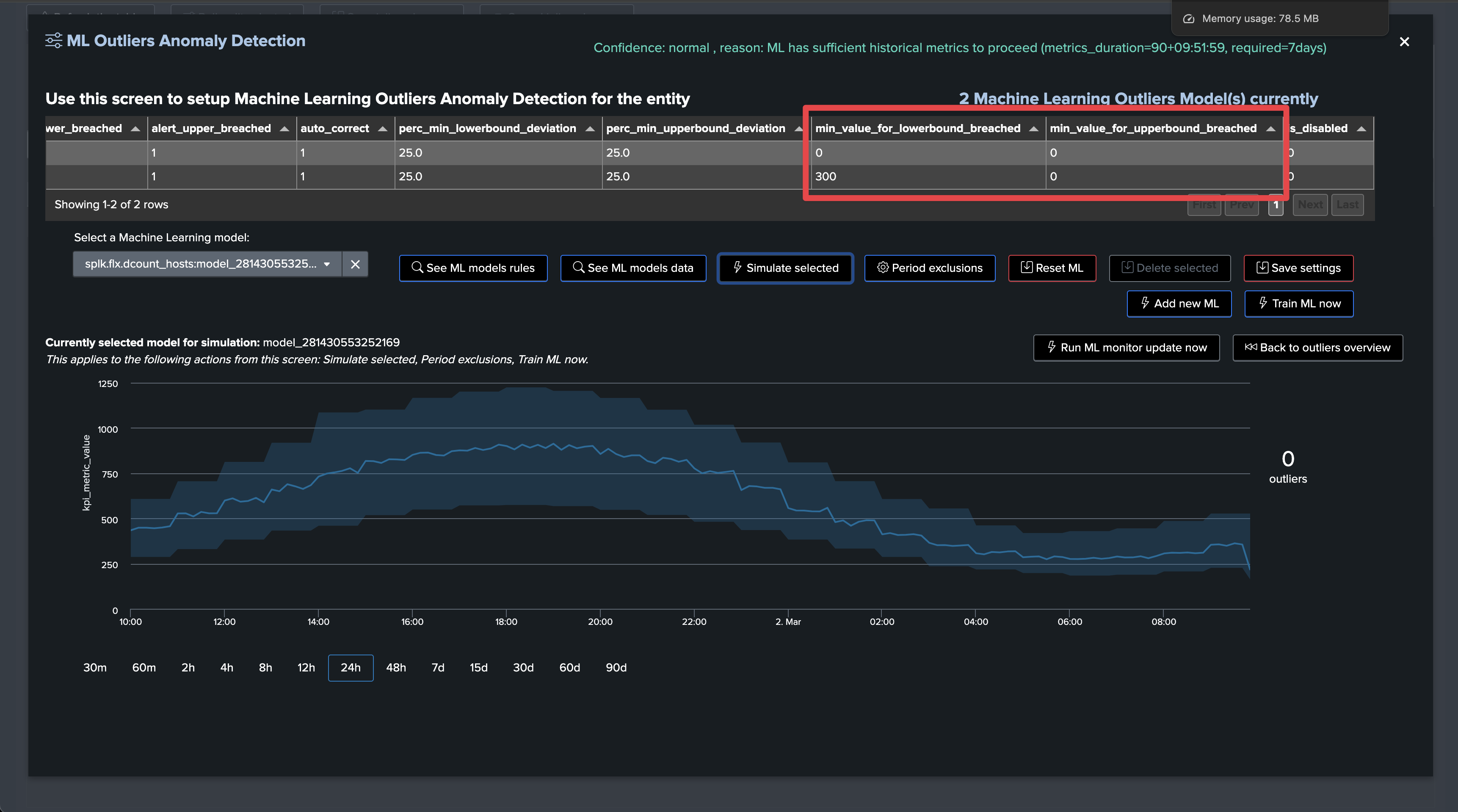
Since TrackMe 2.0.84, you can define minimal thresholds for LowerBound and UpperBound Outliers; values not respecting these thresholds are rejected automatically:
min_lower_bound_threshold: The minimal value for the LowerBound Outliers; values below this threshold are rejected (for LowerBound breaches)max_upper_bound_threshold: The maximal value for the UpperBound Outliers; values above this threshold are rejected (for UpperBound breaches)
When an Outlier is detected, TrackMe’s backend verifies if a min or max threshold has been defined (depending on the type of Outlier); if the value does not respect the threshold, the Outlier is rejected and not taken into account in the entity status.
True context Outliers simulation screen:
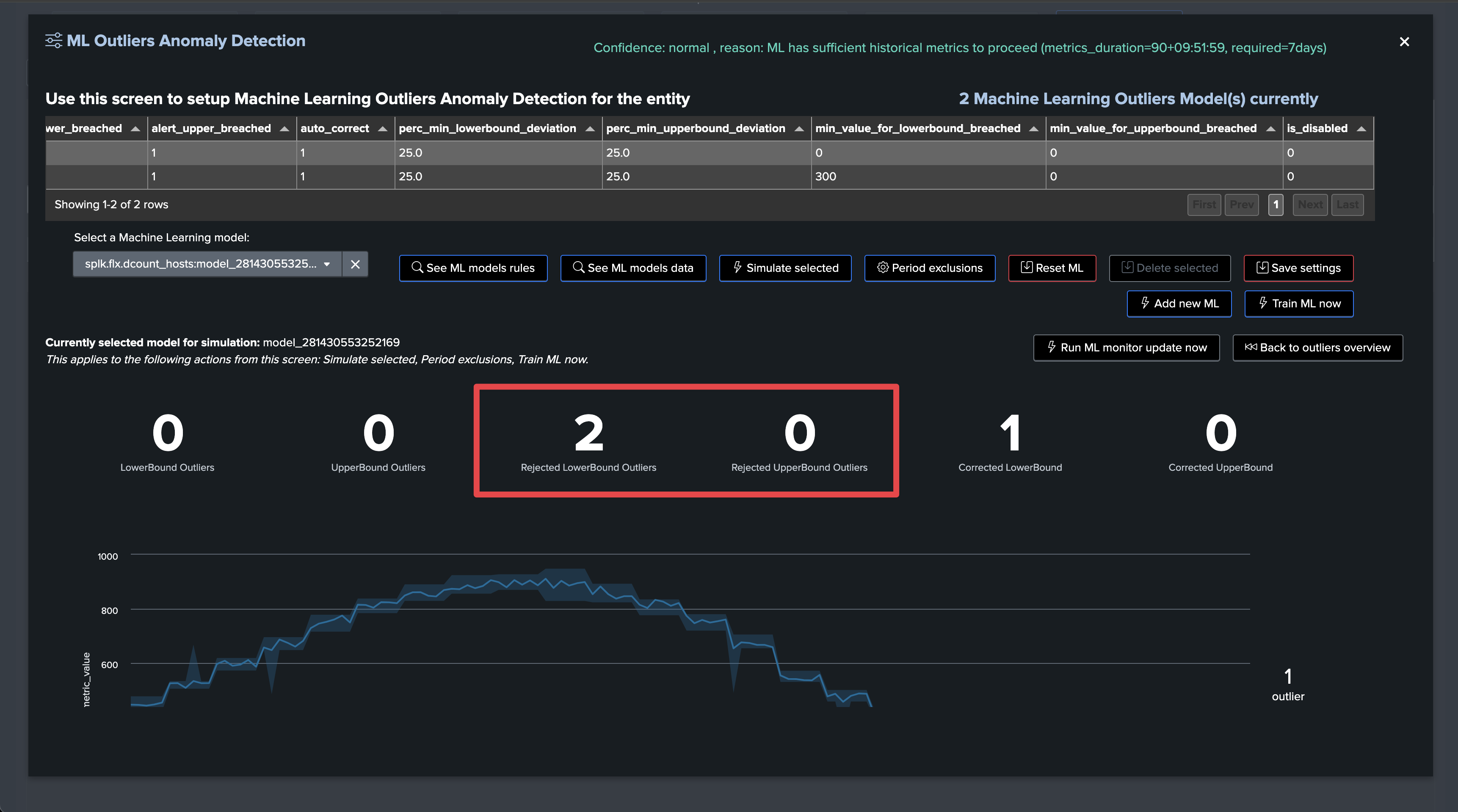
Live Outliers screen:
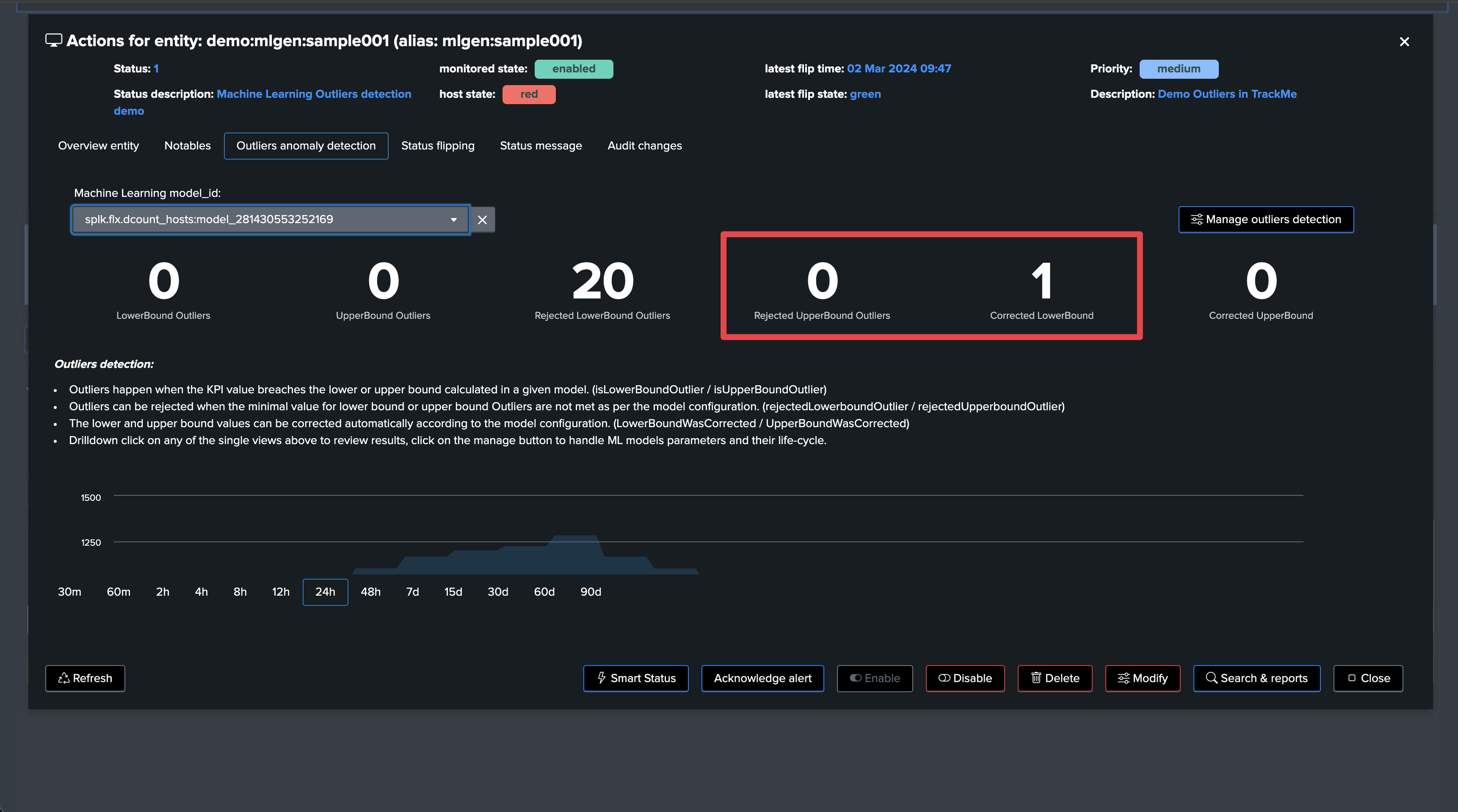
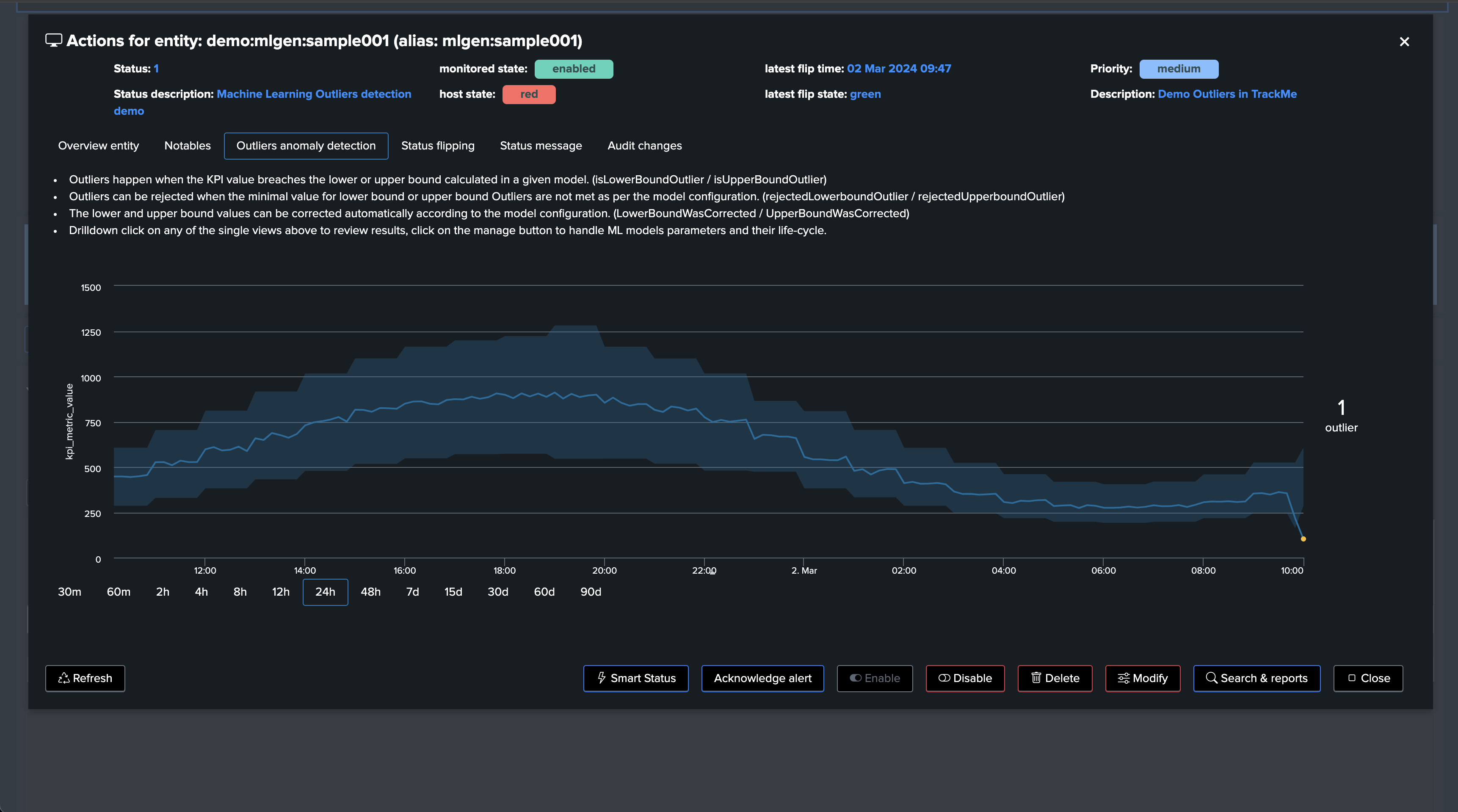
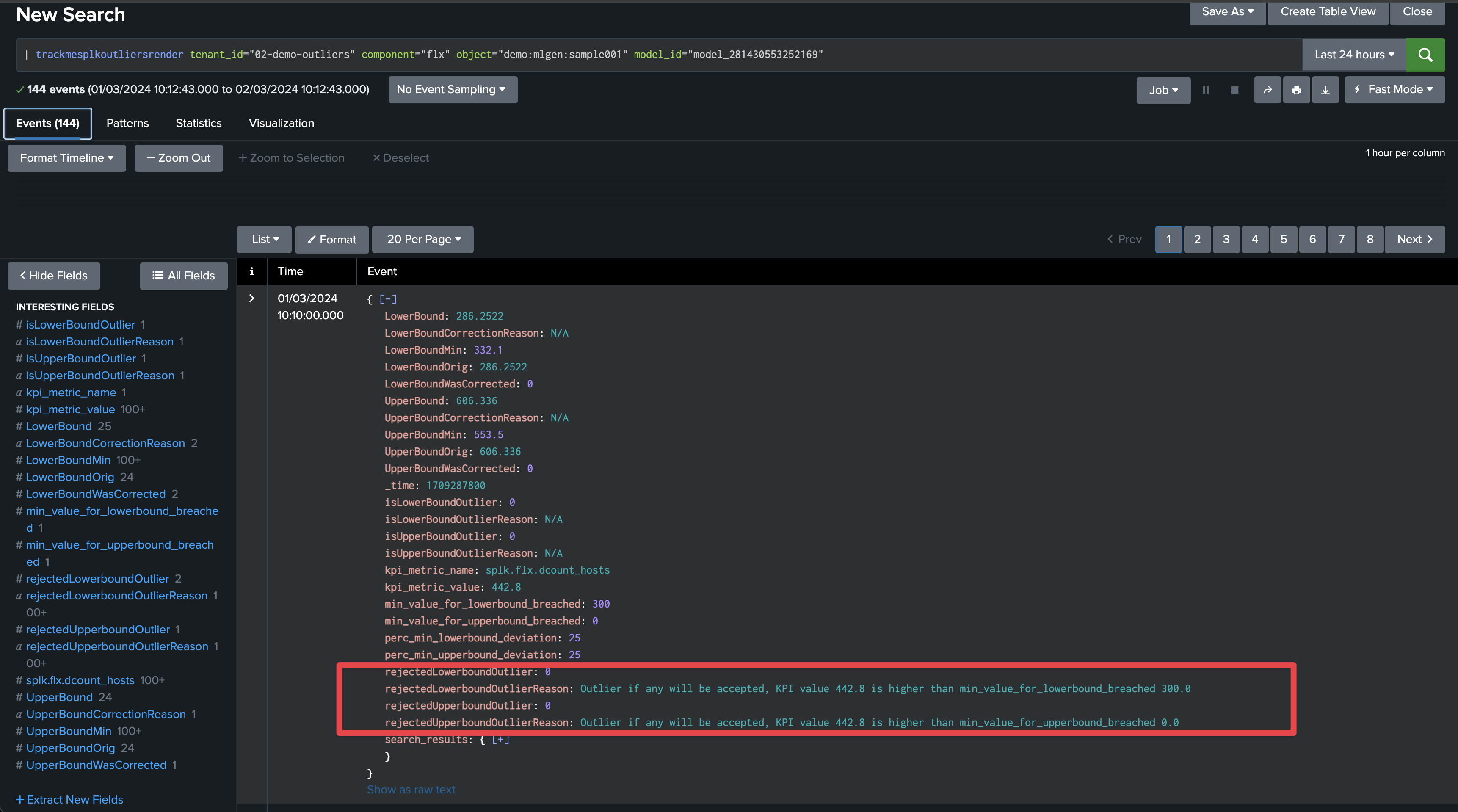
Rendering TrackMe’s commands also show rejected counters and reasons:
Demonstrating Machine Outliers Detection in TrackMe
How ML Outliers Works in TrackMe
In short:
All components are eligible for Machine Learning Outliers
Outliers rely on TrackMe-generated metrics only
This allows running fast and efficient training and rendering searches, with the minimal costs in terms of resources
For the purpose of this demonstration, we create a Flex Object TrackMe tenant which takes into account our ML generator:
For more information about TrackMe restricted Flex Objects component: splk-flx - Creating and managing Flex Trackers
Our Flex tracker:
Tracker name: “demo”
Runs every 5 minutes (earliest: -5m, latest: now)
index=mlgen ref_sample=*
| stats avg(dcount_hosts) as dcount_hosts, avg(events_count) as events_count by ref_sample
| eval group = "demo"
| eval object = "mlgen" . ":" . ref_sample, alias = ref_sample
| eval object_description = "Demo Outliers in TrackMe"
| eval metrics = "{'dcount_hosts': " . dcount_hosts . ", 'events_count': " . events_count . "}"
| eval outliers_metrics = "{'dcount_hosts': {'alert_lower_breached': 1, 'alert_upper_breached': 1}, 'events_count': {'alert_lower_breached': 1, 'alert_upper_breached': 1}}"
| eval status=1
| eval status_description="Machine Learning Outliers detection demo"
| table group, object, alias, object_description, metrics, outliers_metrics, status, status_description
``` default metric for the TrackMe UI to pick when opening the entity screen ```
| eval default_metric="events_count"
``` alert if inactive for more than 3600 sec```
| eval max_sec_inactive=3600
This Flex Tracker creates entities by monitoring the availability of data in our ML index; it also generates metrics and automates the definition of models which alert on both lower bound and upper bound outliers.
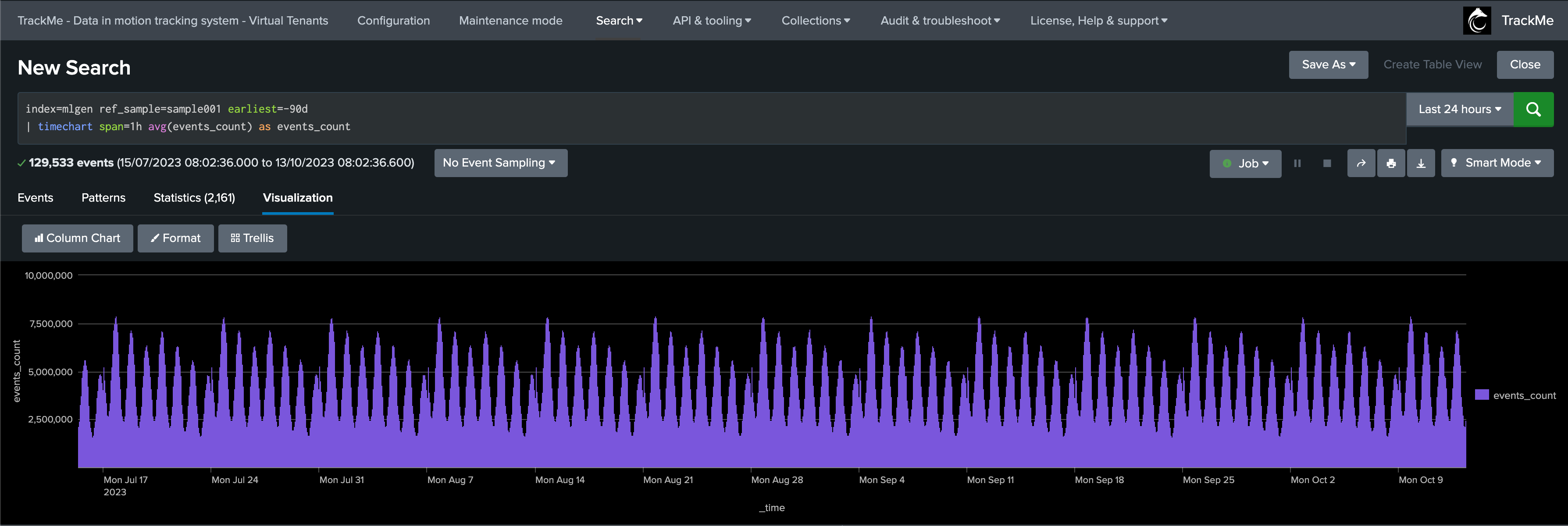
We have our ML generator running and having backfilled the past 90 days of data; it currently does not generate any outliers:
index=mlgen ref_sample=sample001 earliest=-90d
| timechart span=1h avg(events_count) as events_count
Our ML generator takes into account the weekdays; we can use the following search to compare the relative activity of the current weekdays against the past 4 previous same weekdays:
index=mlgen ref_sample=sample001 earliest=@d latest=+1d@d
| timechart span=5m avg(events_count) as events_count_today
| appendcols [
search index=mlgen ref_sample=sample001 earliest=-7d@d latest=-6d@d
| timechart span=5m avg(events_count) as events_count_ref
]
| appendcols [
search index=mlgen ref_sample=sample001 earliest=-14d@d latest=-13d@d
| timechart span=5m avg(events_count) as events_count_ref2
]
| appendcols [
search index=mlgen ref_sample=sample001 earliest=-21d@d latest=-20d@d
| timechart span=5m avg(events_count) as events_count_ref3
]
Results:

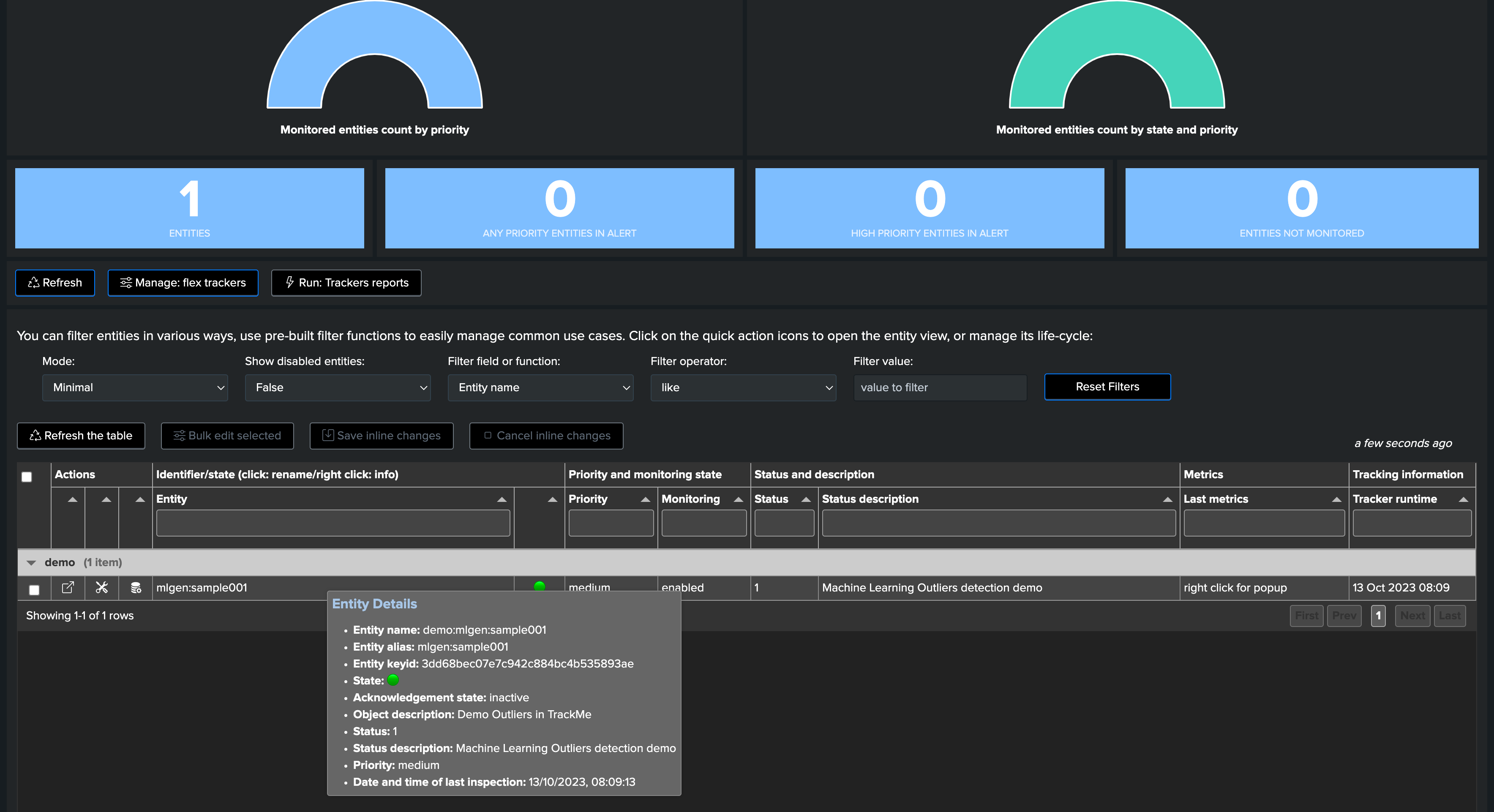
TrackMe automatically discovered the entity, let’s take note of its internal identifier which we will use to manually backfill TrackMe metrics, as if we had been monitoring this entity since the beginning:
We use mcollect to force backfilling metrics, pay attention to replace with the valid tenant_id value:
index=mlgen ref_sample=* earliest=-90d latest=-5m
| bucket _time span=5m
| stats avg(dcount_hosts) as trackme.splk.flx.dcount_hosts, avg(events_count) as trackme.splk.flx.events_count by _time, ref_sample
| eval alias=ref_sample
| lookup trackme_flx_tenant_demo-outliers alias OUTPUT tenant_id, _key as object_id, object, object_category
| where isnotnull(object_id)
| mcollect index=trackme_metrics split=t object, object_category, object_id, tenant_id
Opening the entity shows we have backfilled metrics now:
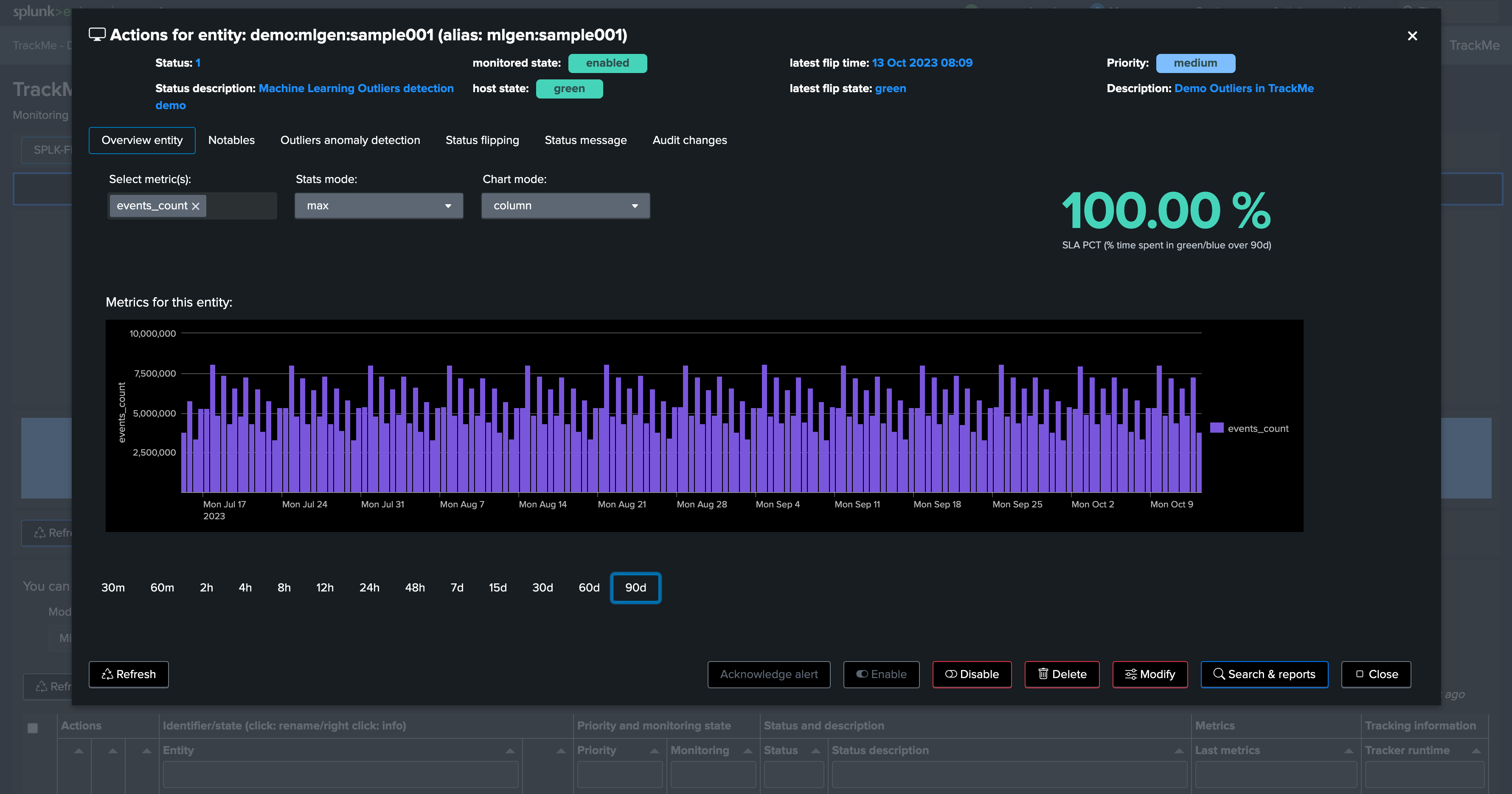
Depending on if TrackMe already ran or not the ML training job for the tenant, ML Outliers may not be ready yet:
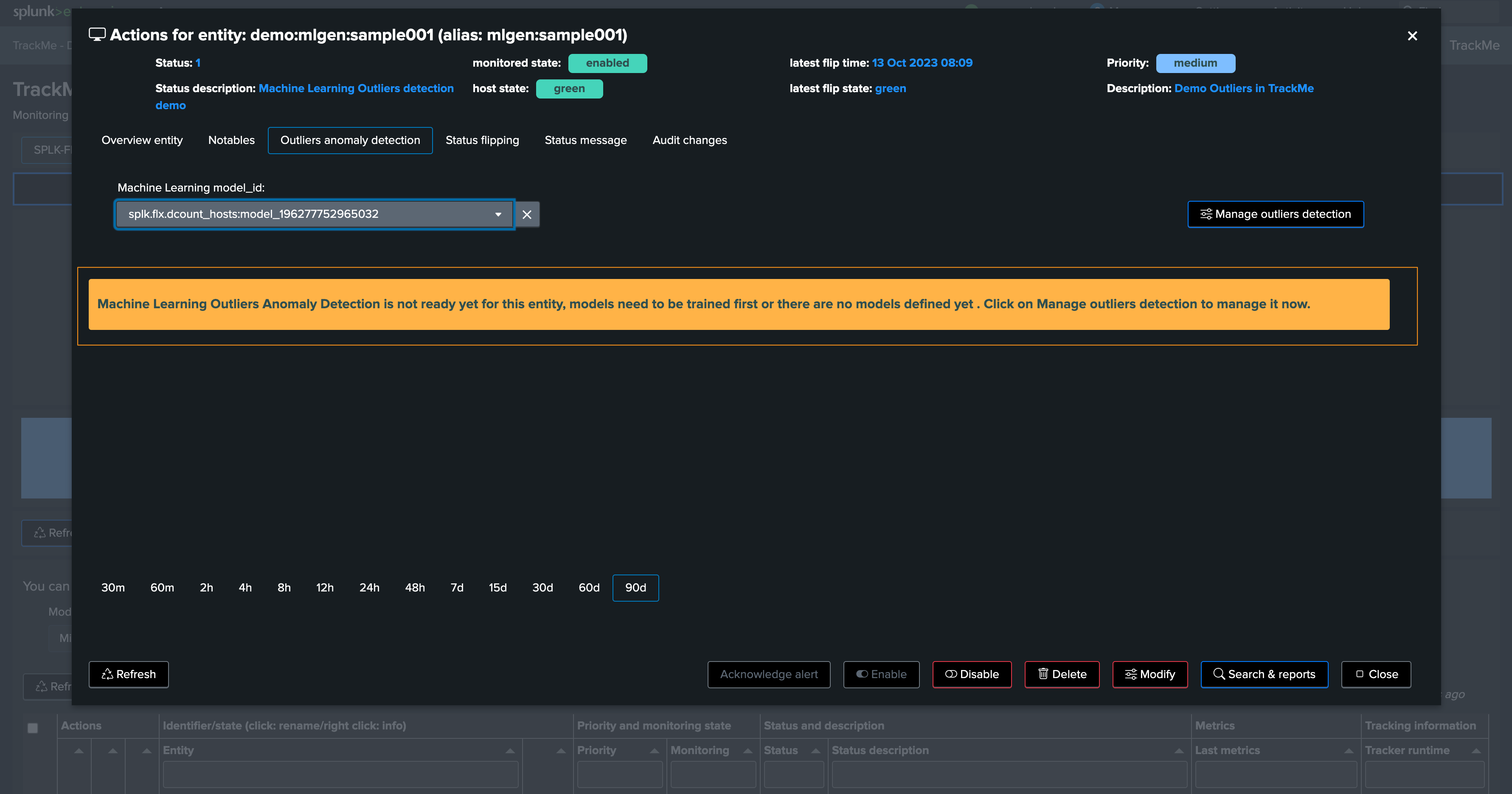
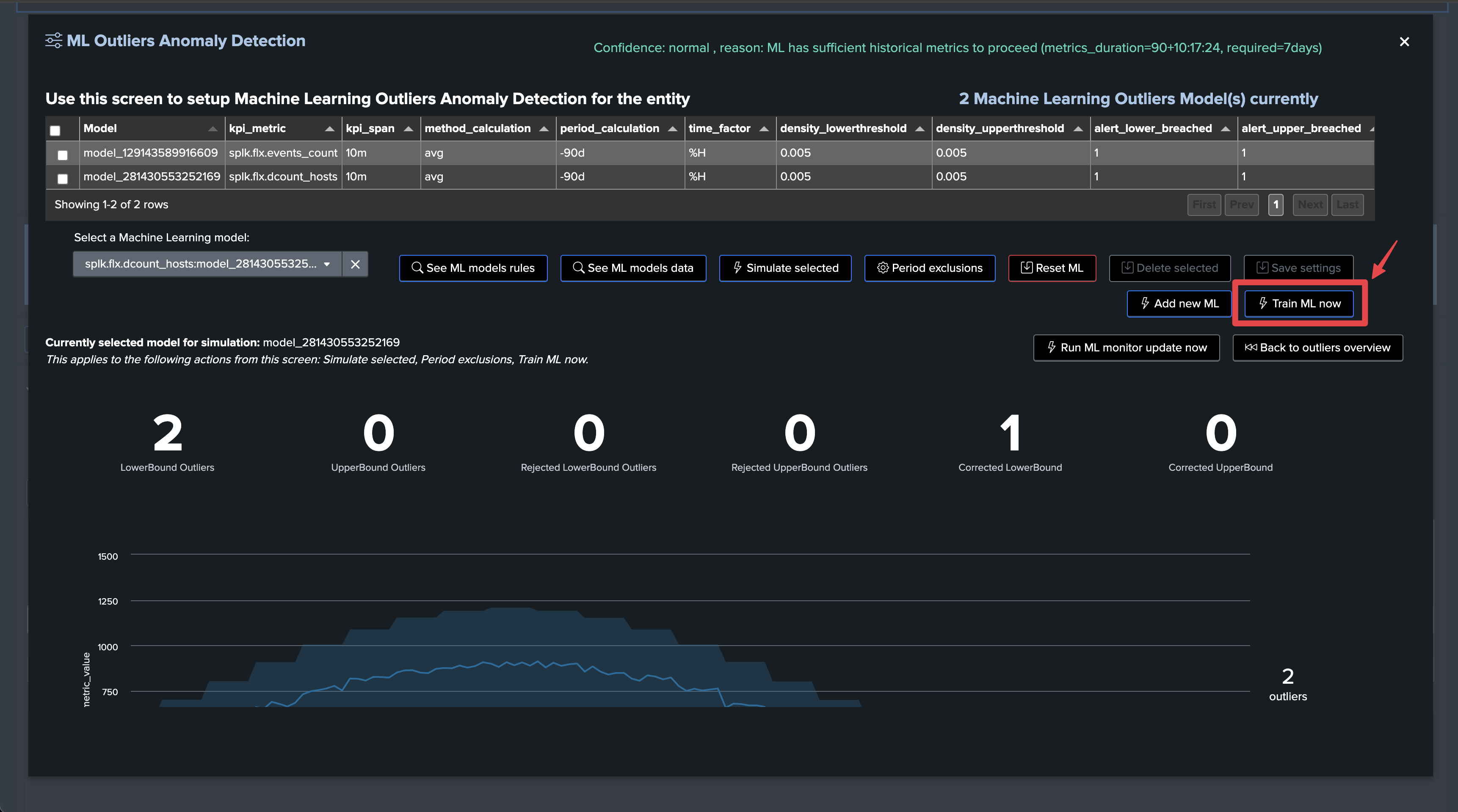
We can either run the mltrain job manually, or train the models via the UI:
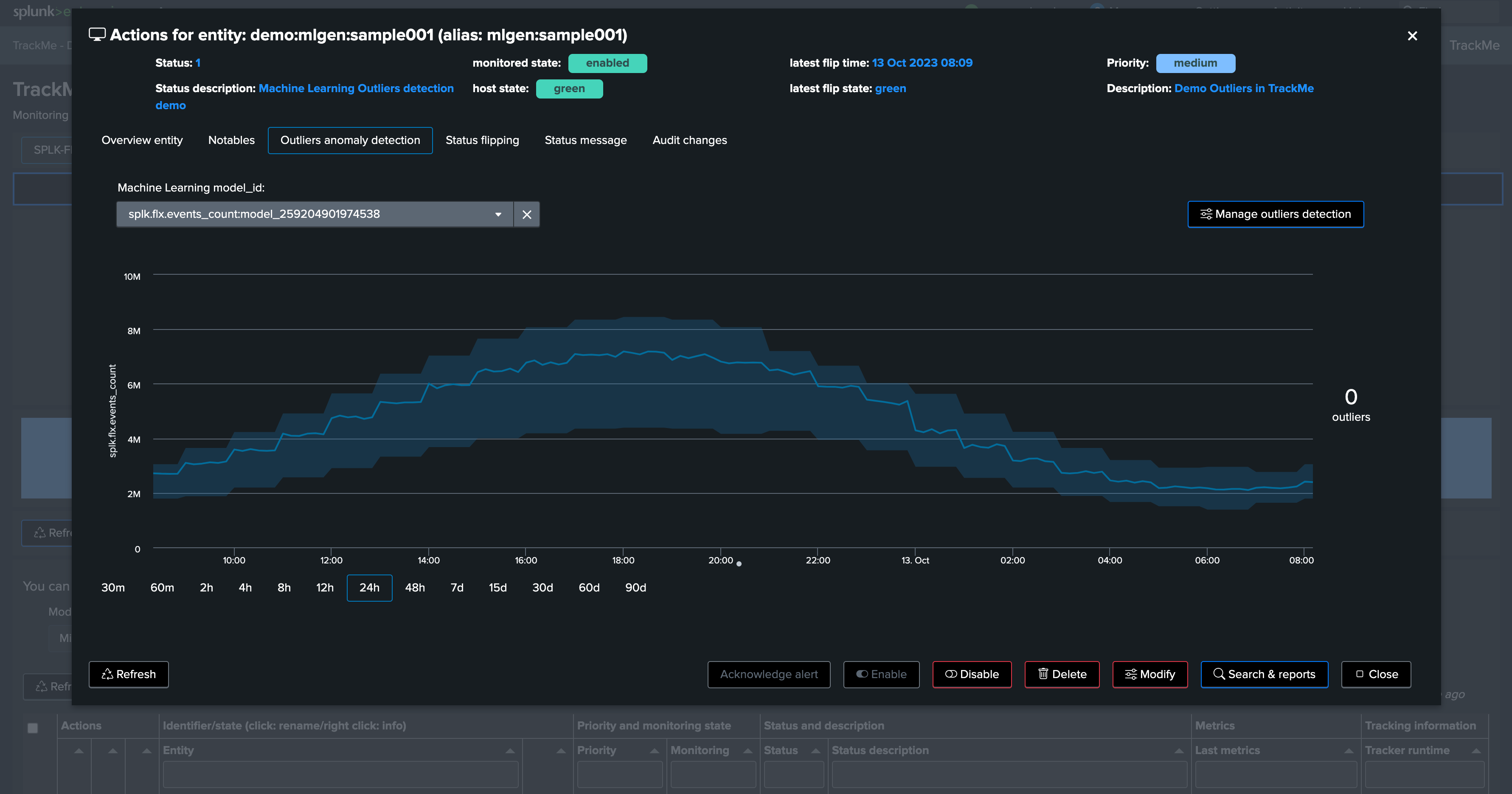
If we refresh TrackMe, we can now see ML is ready:
We have no outliers yet
TrackMe applied defaults settings for the ML definition (training over the past 30 days, time per hour)
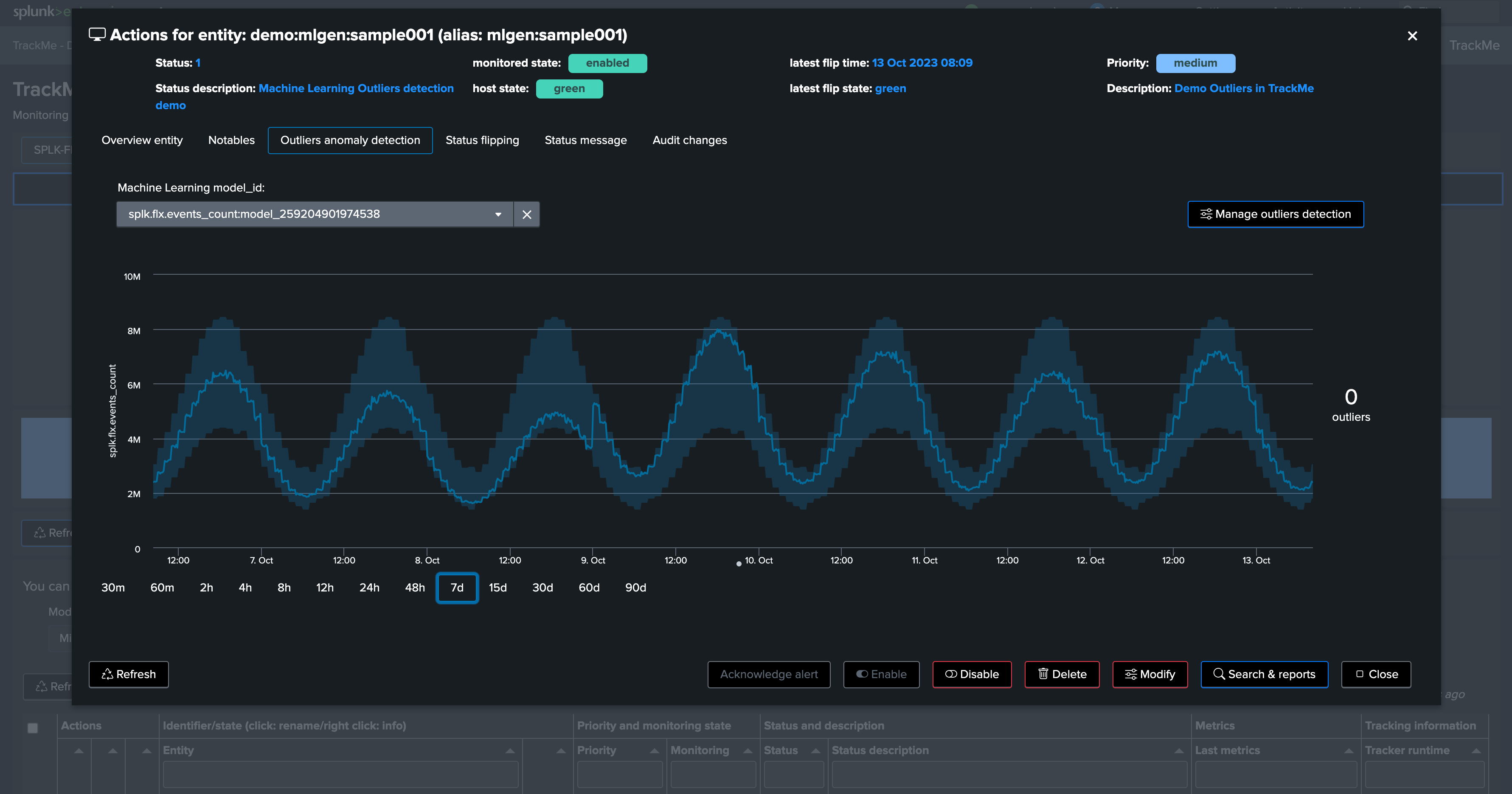
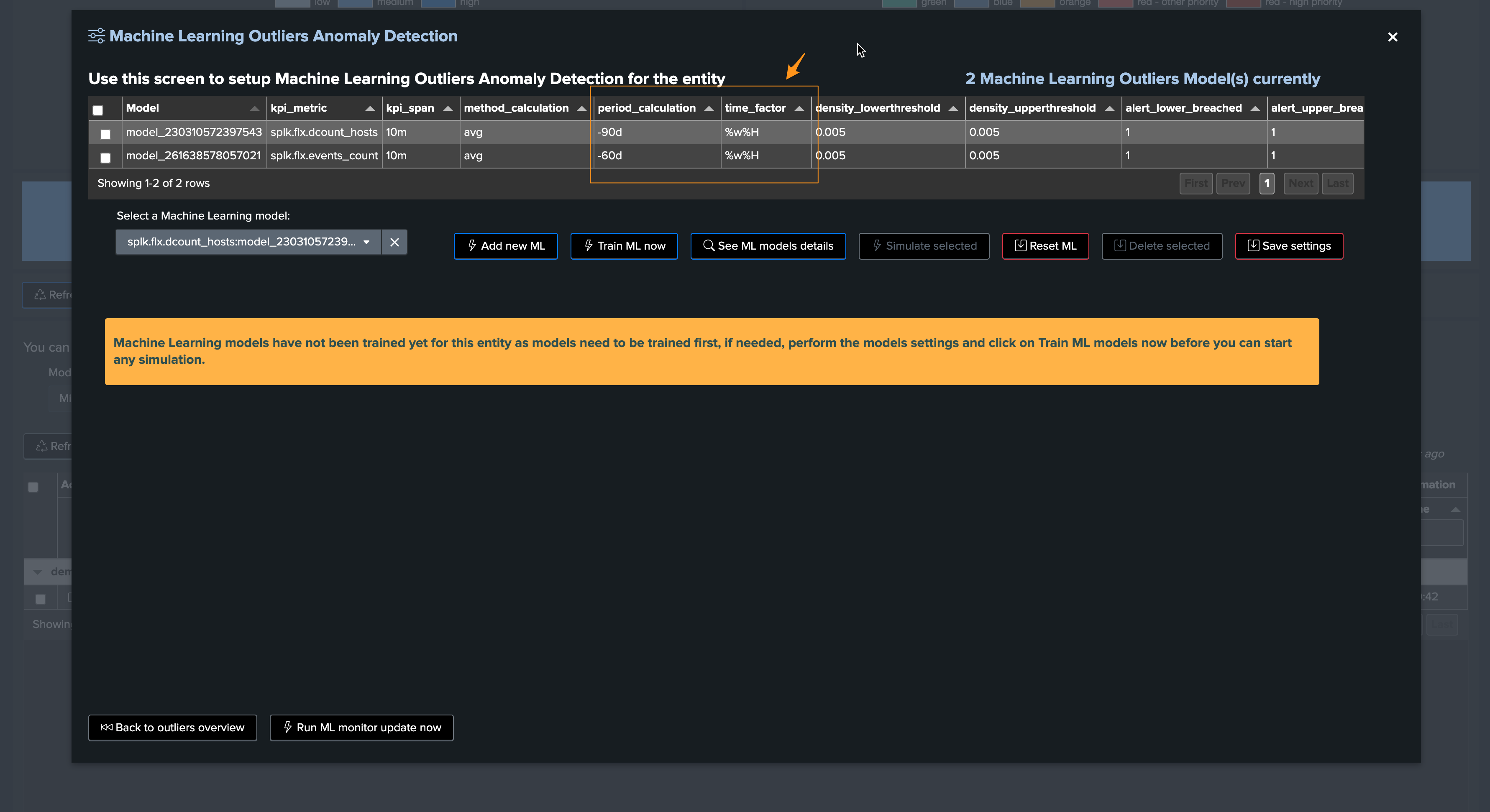
Let’s access and review the models definition, for now we will only increase the training period to the past 90 days:
Click on “Manage Outliers detection”
Update the models to increase the time range for the calculation
Manually run a training for each model
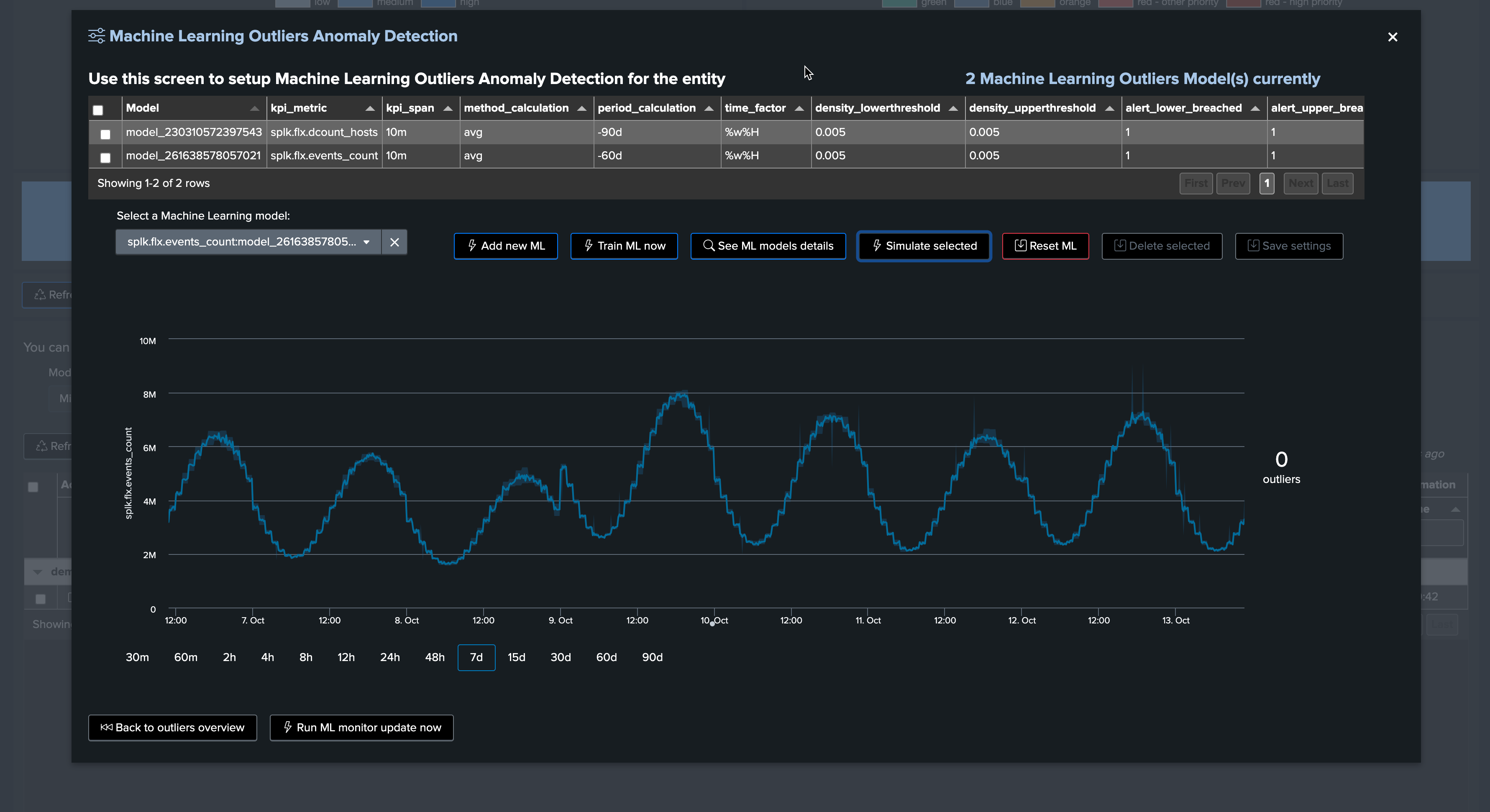
Click on Simulate Selected to review the results (we have selected the event count model), this is looking great for now
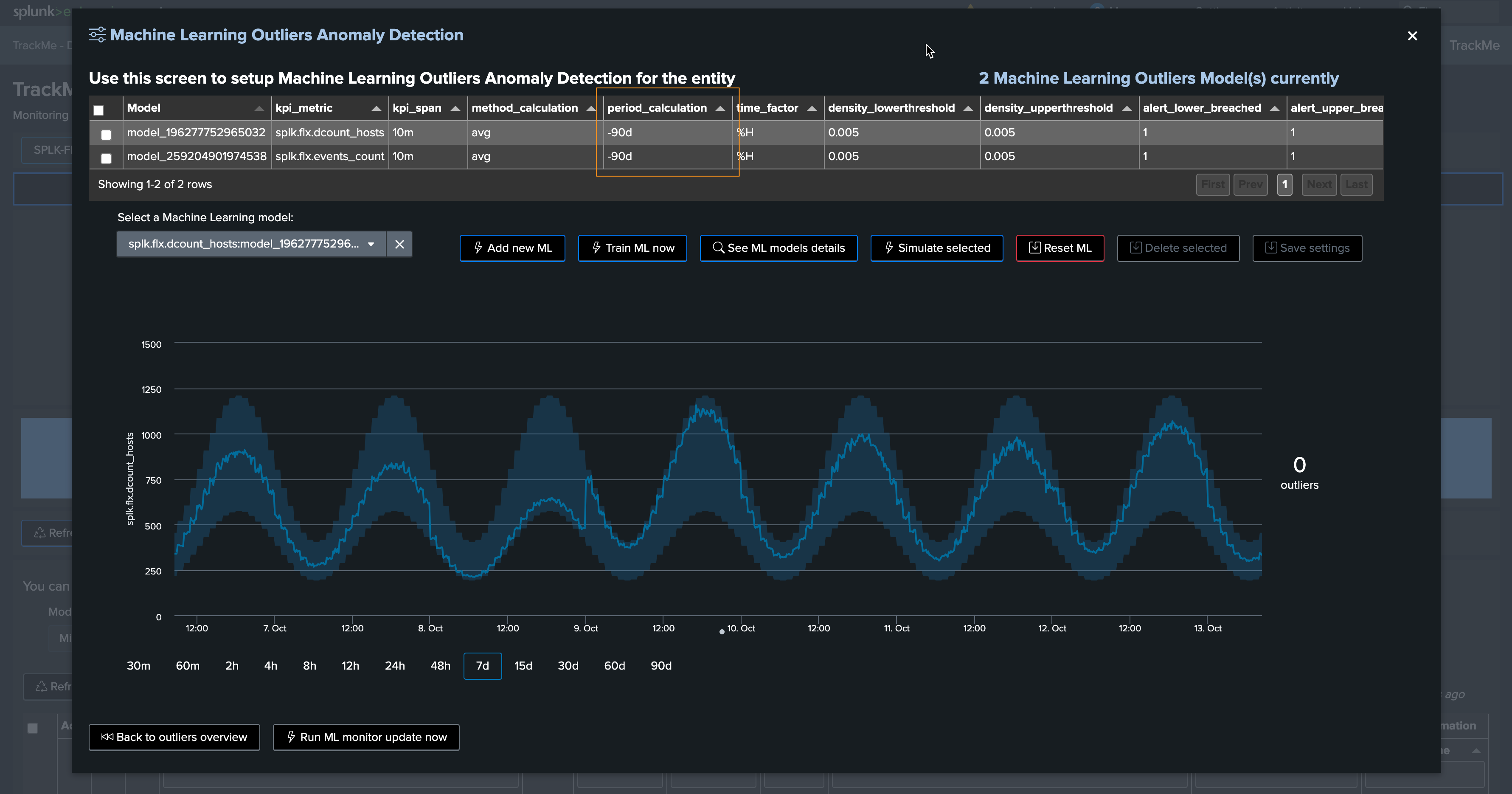
You can click on See ML model details to access and review to the models information:
Scenario: Detecting a lower bound outliers
Although we know there is a weekday behavior in the data, for now we will stick with the default settings and we will start generating a lower bound outlier.
To achieve this, we stop the run_backfill.sh and we start run_gen_lowerbound_outlier.sh, this basically:
Influence metrics with a large decrease of the curve, by an approximately 75%, accordingly to the magnitude of the week day / hour range
After a few minutes, we start to see a clear outlier using the previous days’ comparison timechart search:

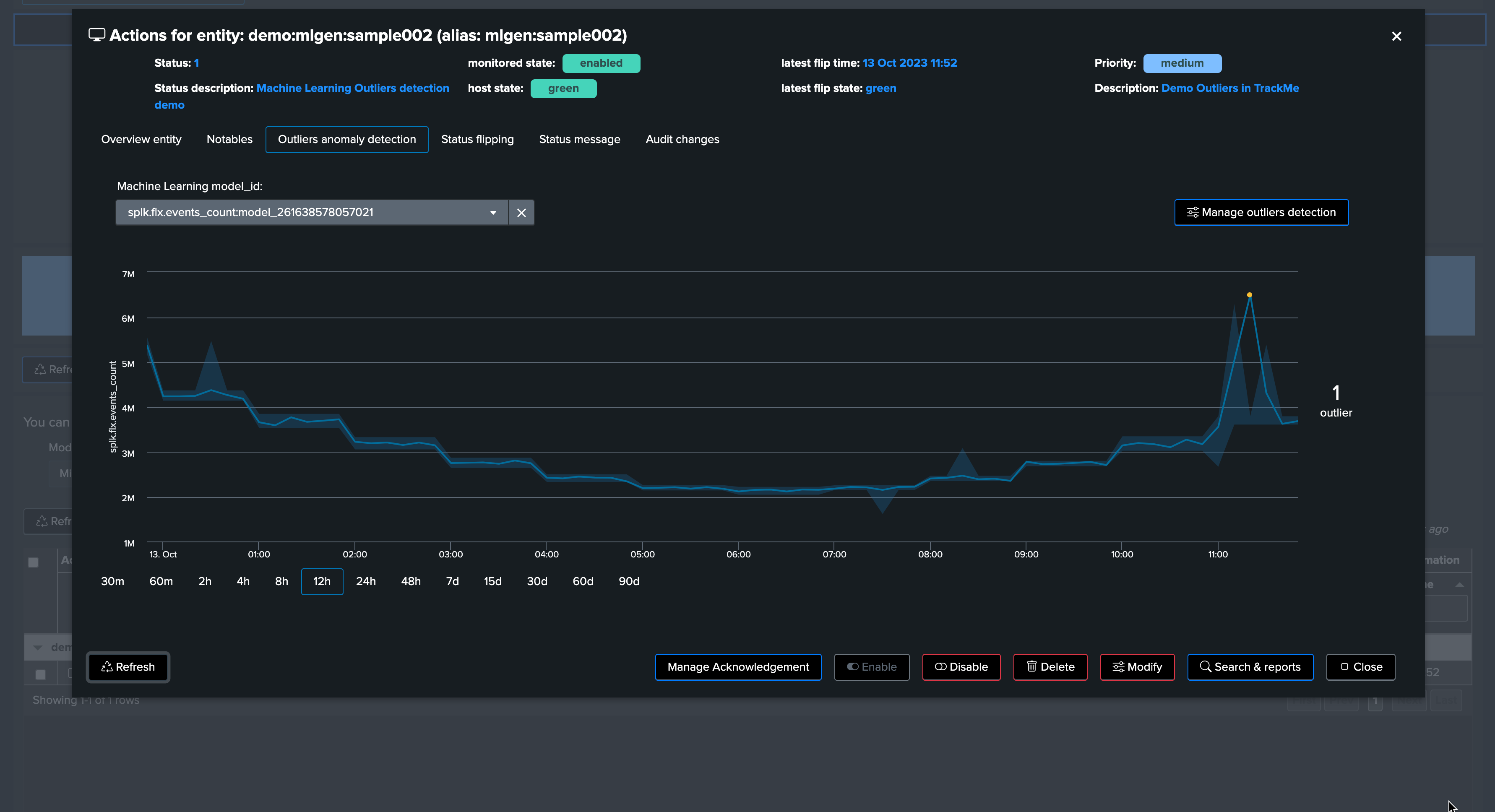
This outlier will also be reflected in TrackMe. It can take 5 to 10 minutes to be detected as an effective outlier:
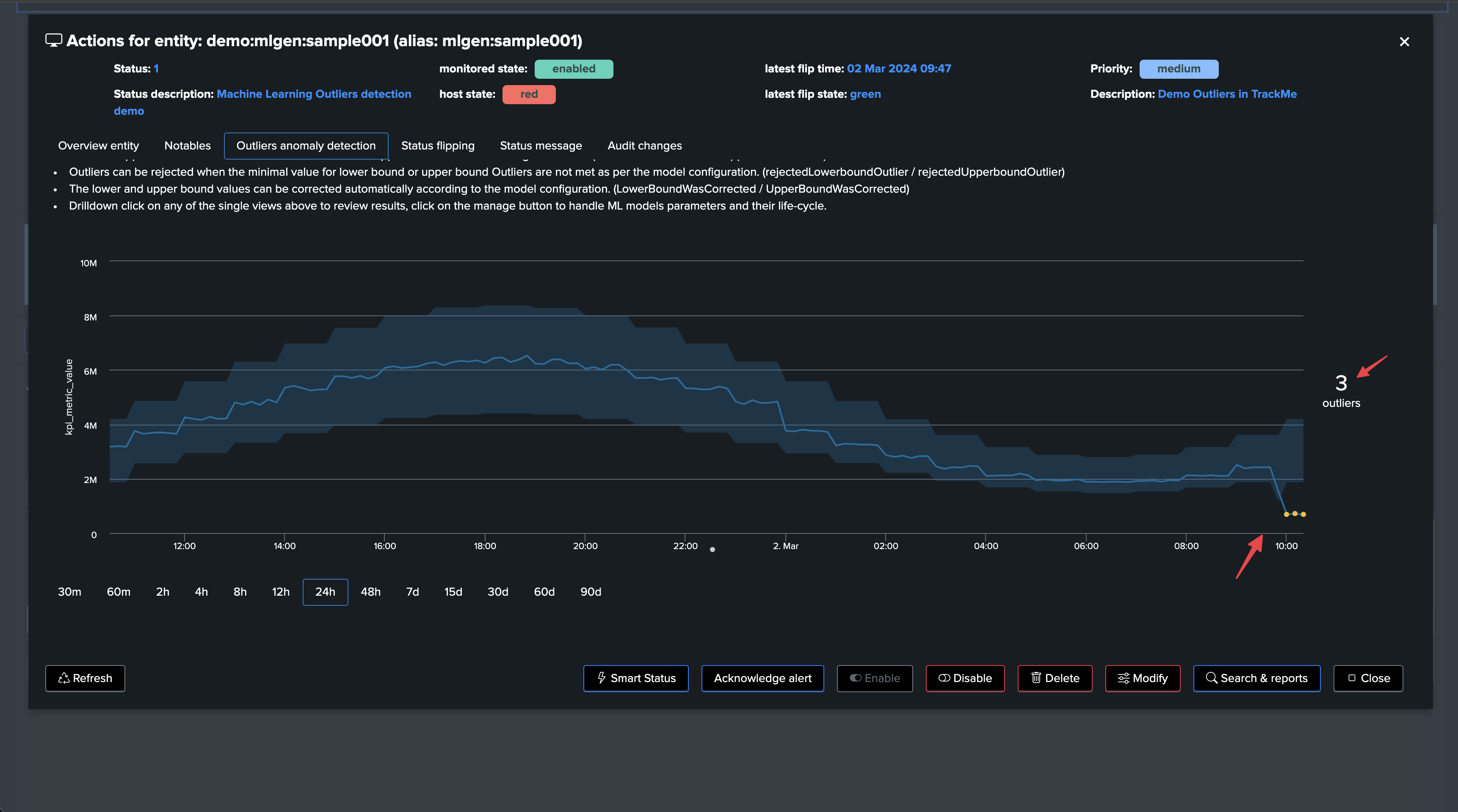
Let’s zoom in the period:
Excellent—the sudden decrease in activity has been detected successfully!
The next phase is to review the Machine Learning rendering phase. This means:
The
_mlmonitor_scheduled backend runs on a regular basis and attempts to review as many entities as possible in a given period of timeDepending on the volume of entities, this process can require some time before the outlier is effectively noticed
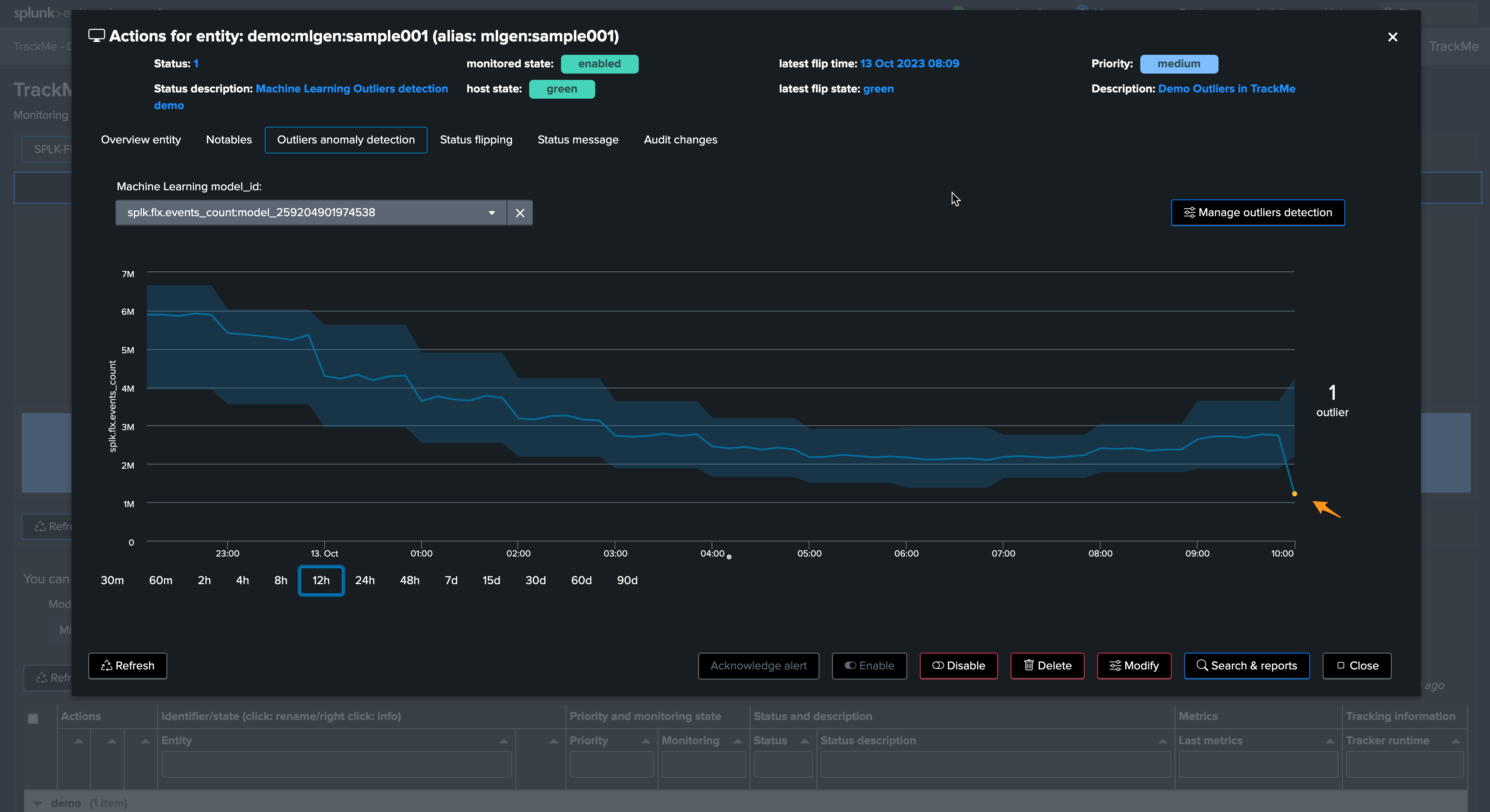
Let’s run the mlmonitor job:
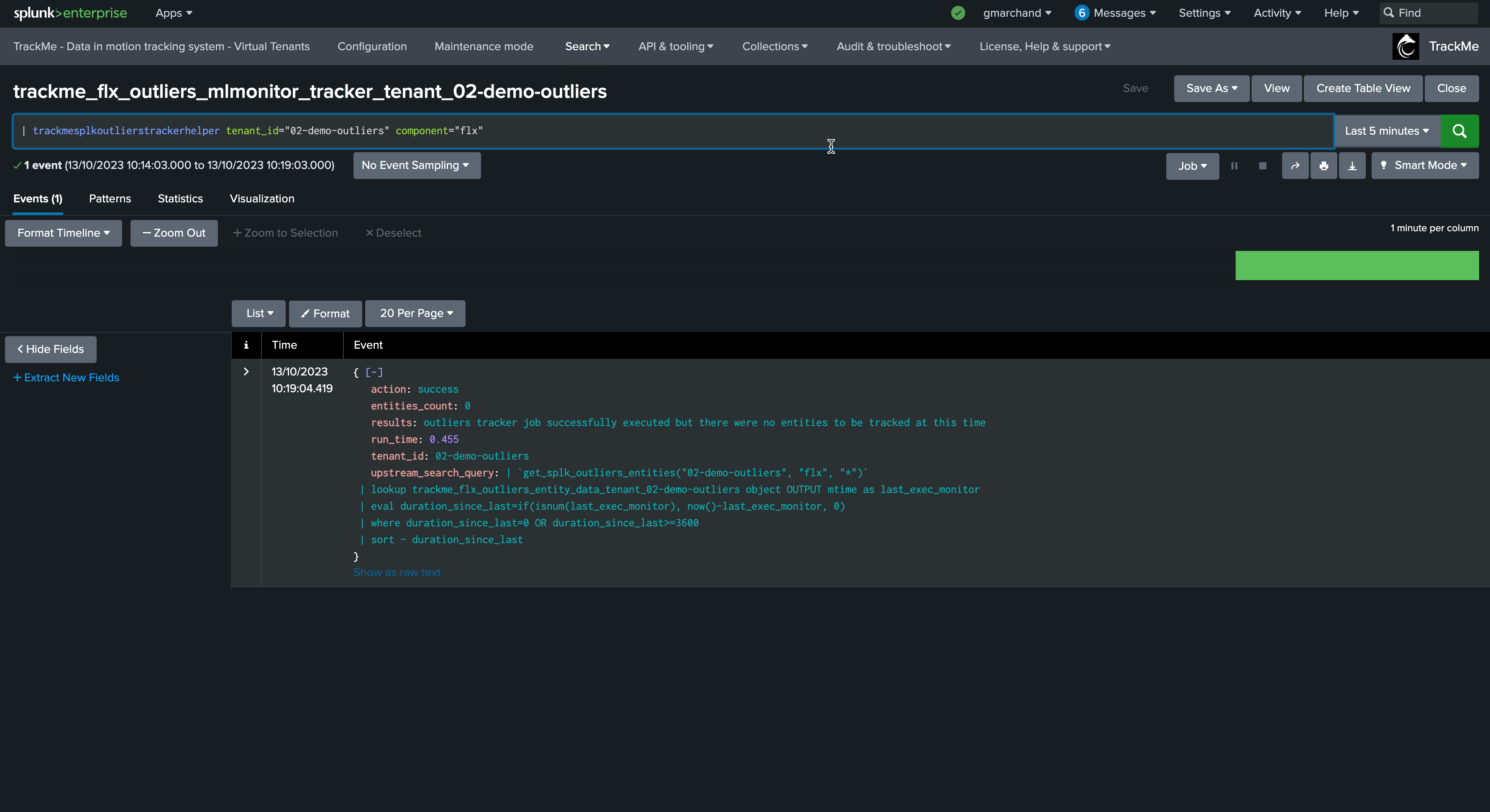
By default, the ML monitor will attempt to verify any entity that has not been verified for more than an hour
This behavior can be customized in the system-wide configuration:
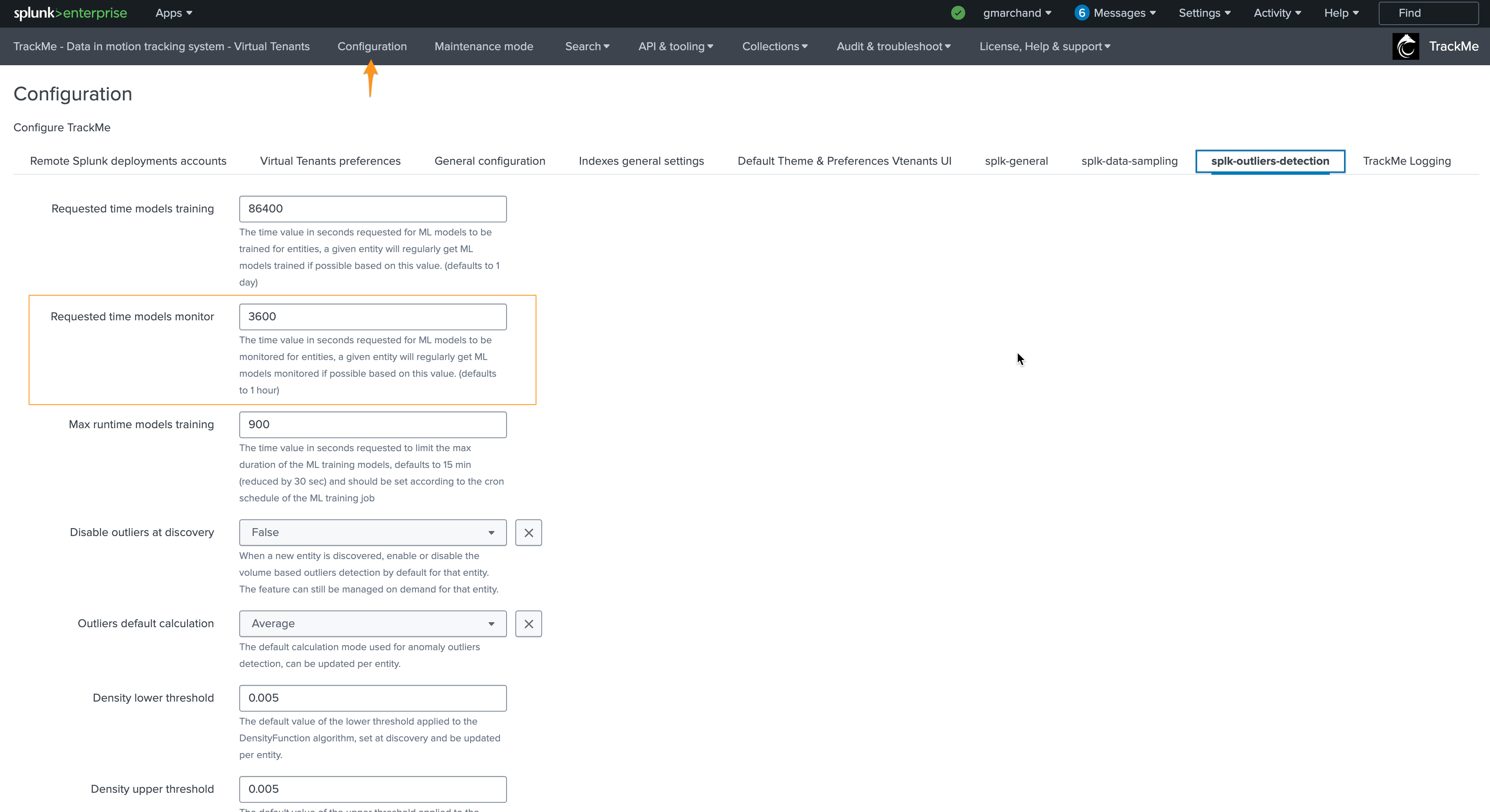
For the purposes of this documentation, we will reduce this to 5 minutes and re-run the monitor backend:
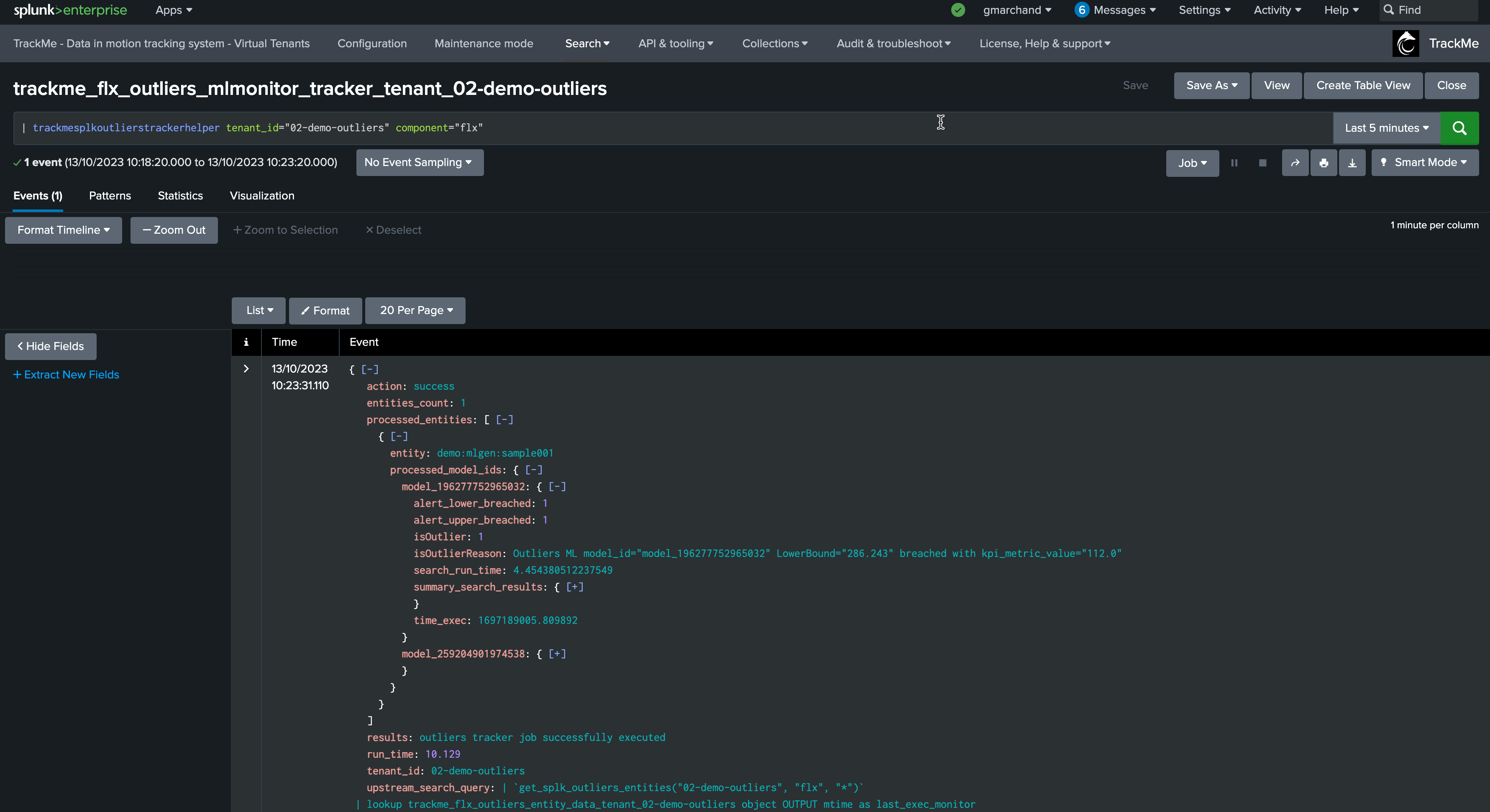
From this output, we already know that the outlier was detected. TrackMe stores the outlier results in a dedicated KVstore collection:
the name of the lookup transforms is trackme_<component>_outliers_entity_data_tenant_<tenant_id>
| inputlookup trackme_flx_outliers_entity_data_tenant_02-demo-outliers
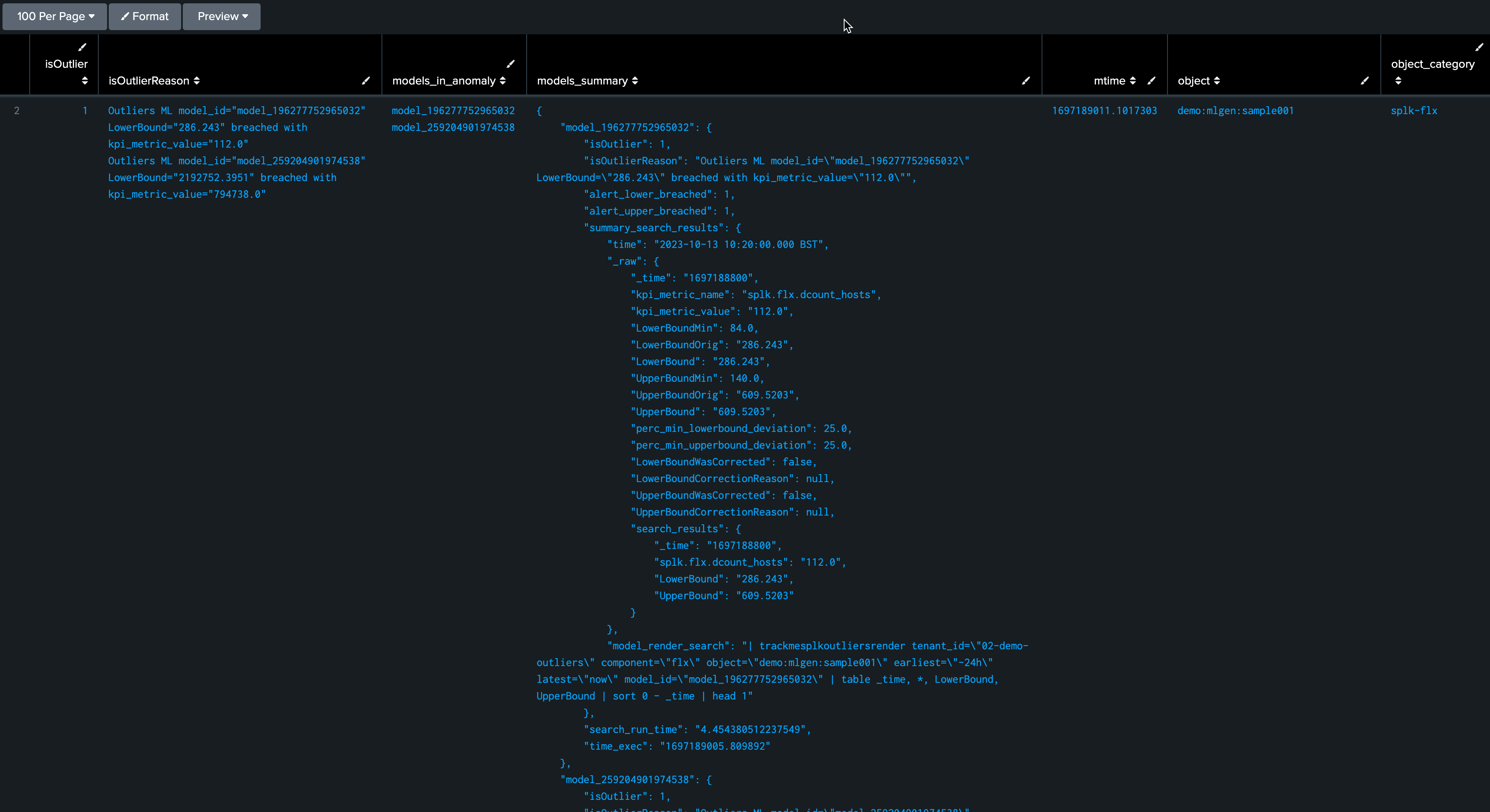
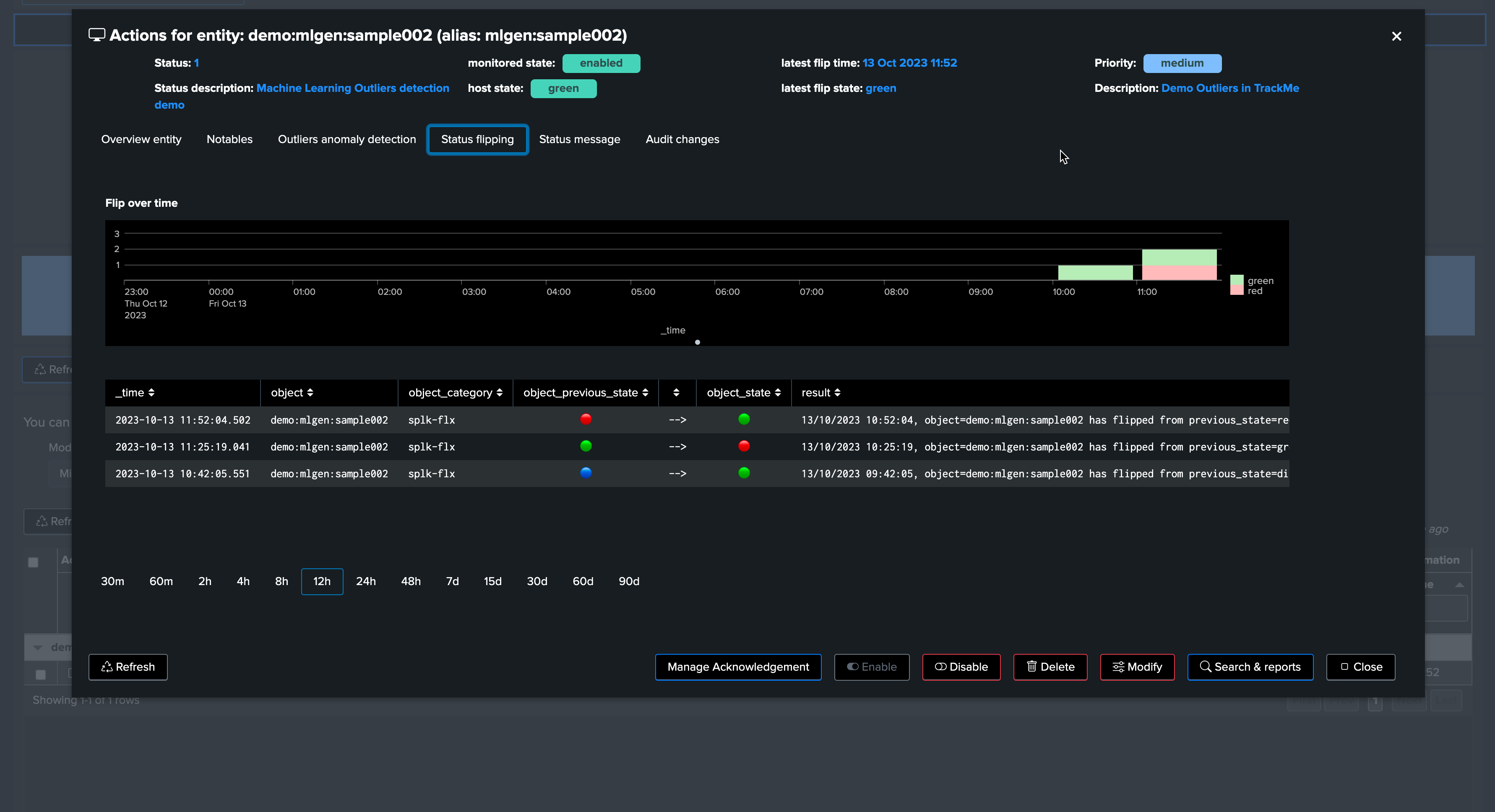
After a few minutes, the TrackMe tracker updates the metadata and the entity appears in red:
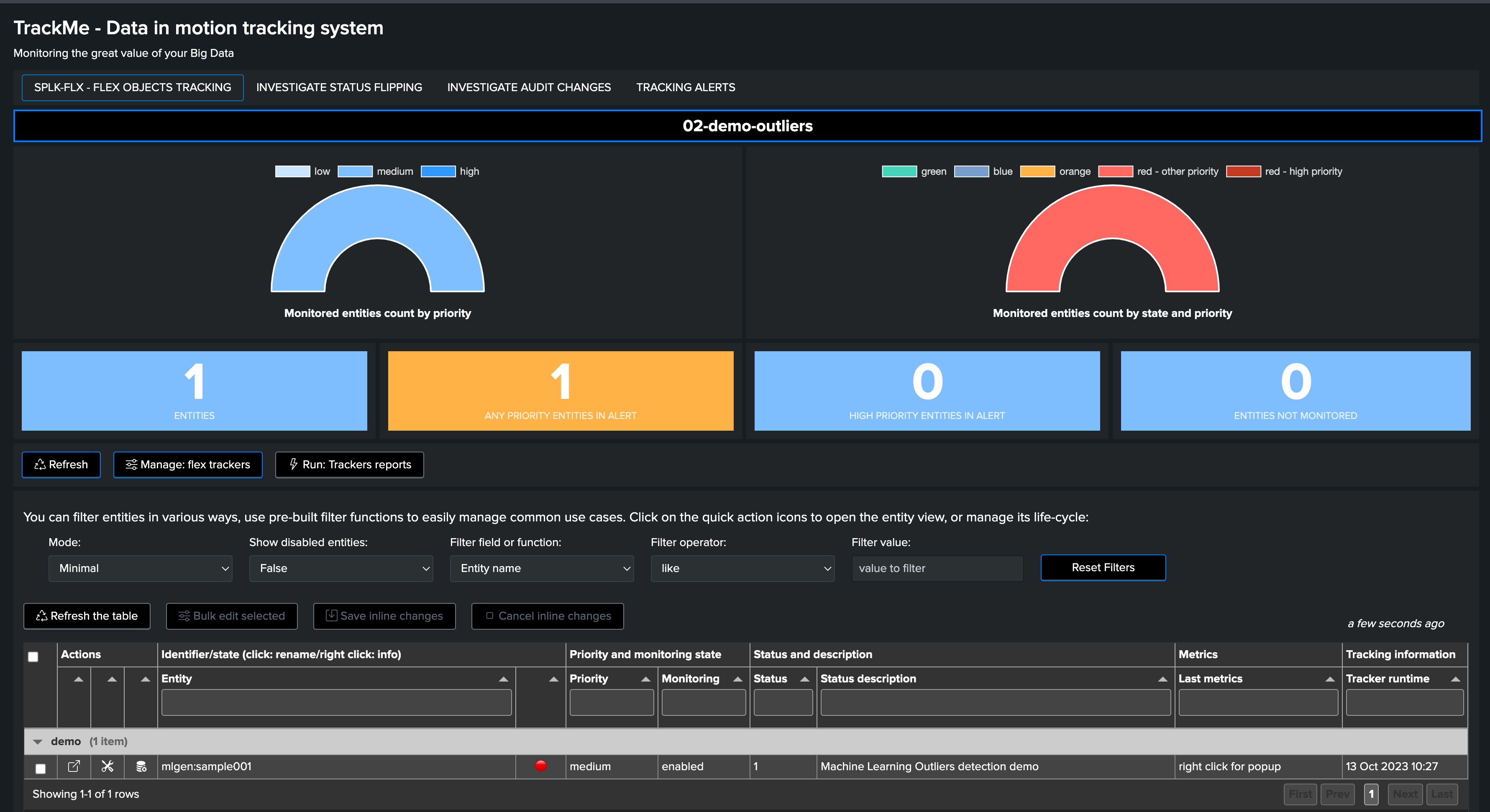
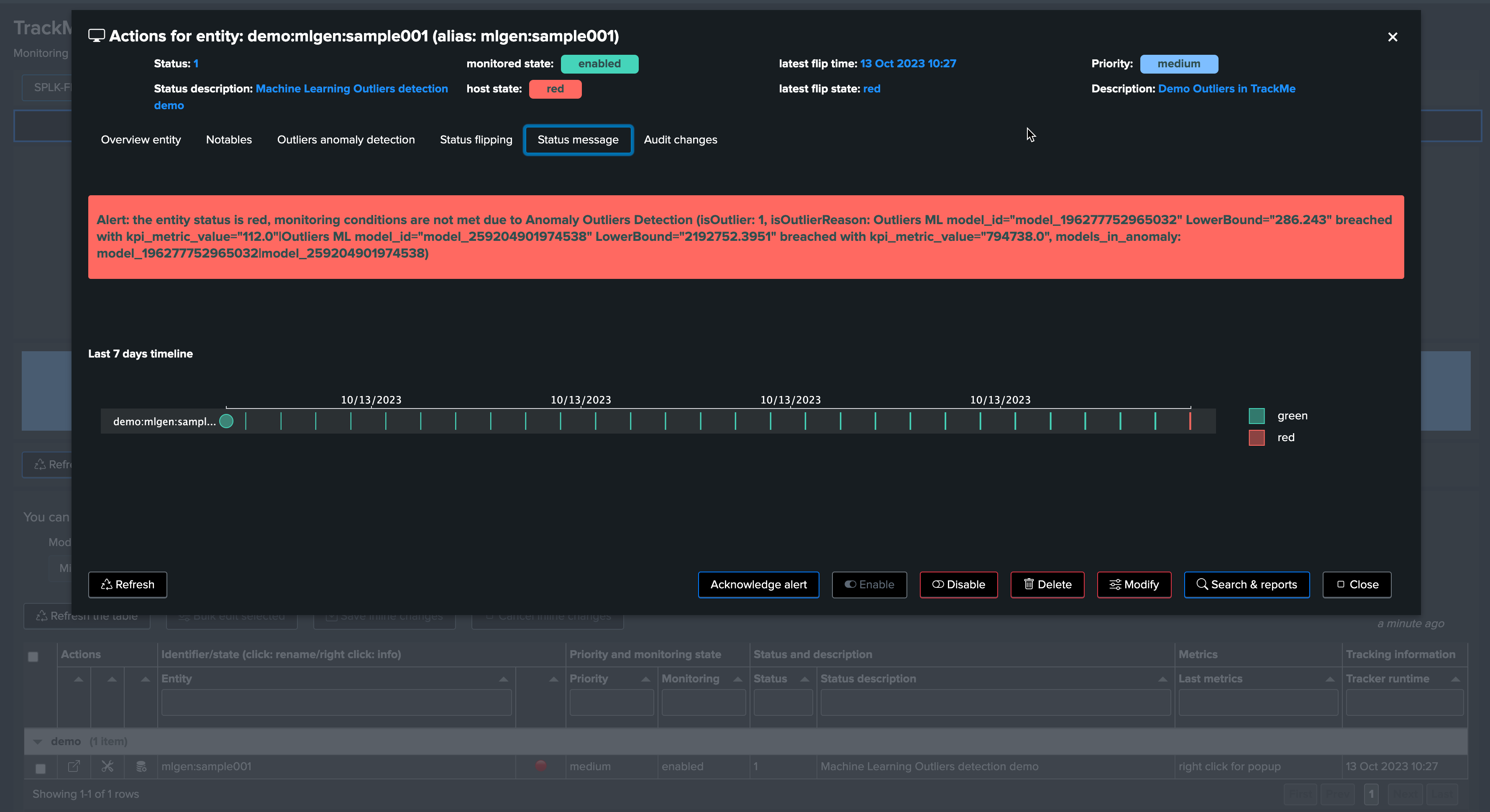
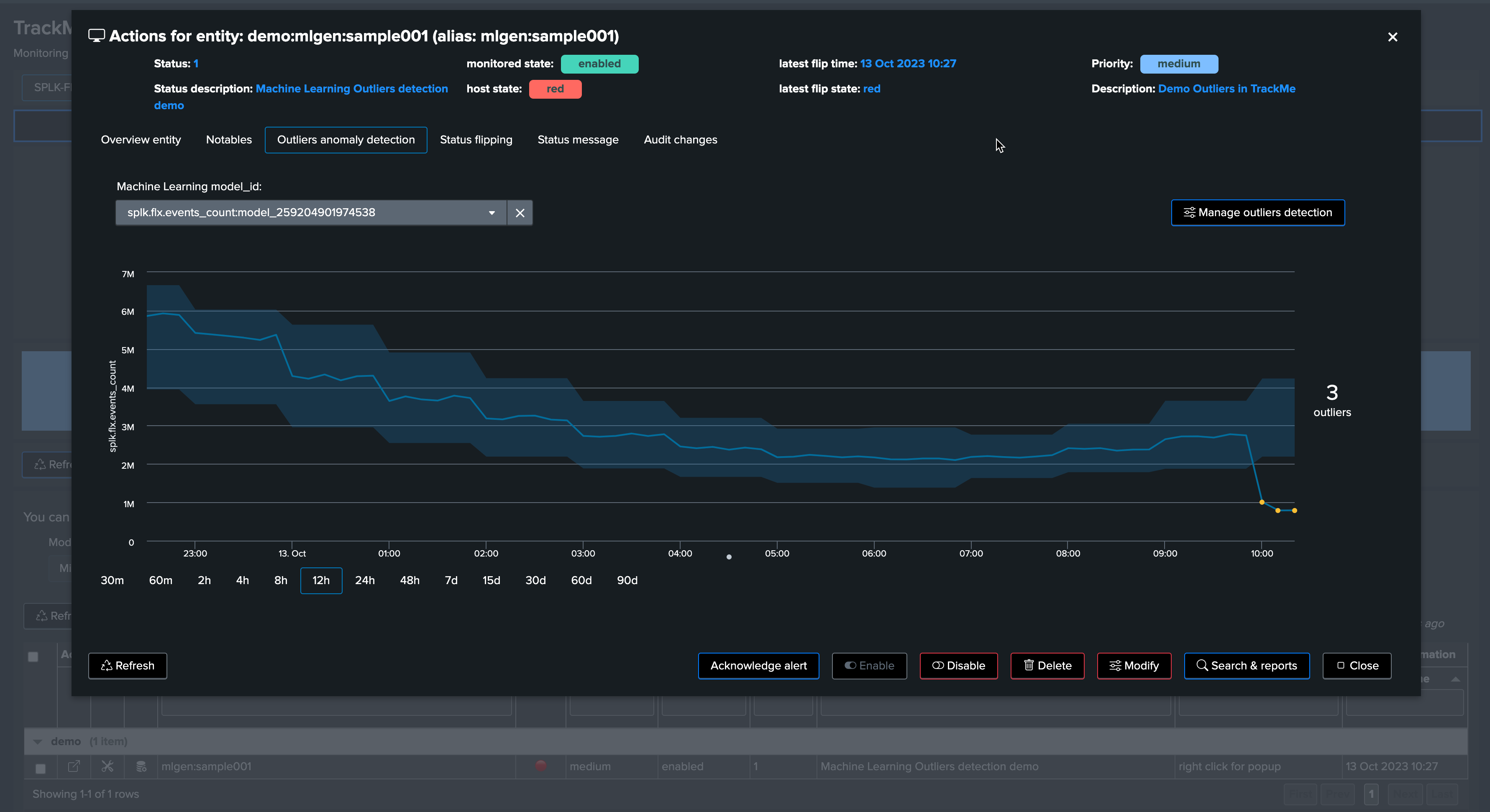
The job is complete, and we have successfully detected an abnormal change in behavior. The entity was impacted, and our alerting configuration would raise an alert accordingly!
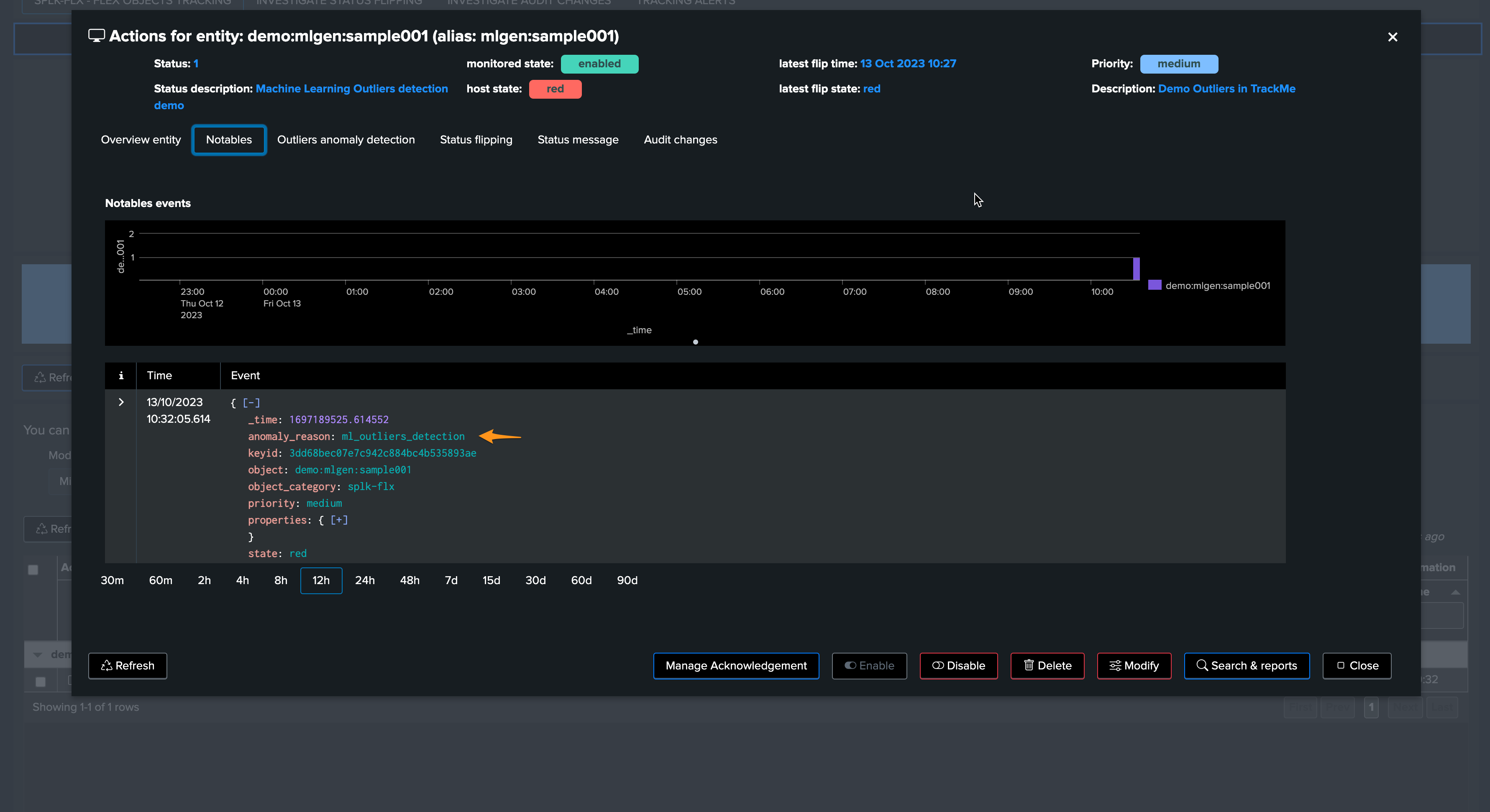
Fine tuning the ML models
True context simulation since TrackMe 2.0.84
Since this TrackMe release, the principal Simulation screen runs simulations in true context, this means that TrackMe will train an ML model dedicated for that simulation, allowing the Outliers detection to 100% reflect the live Outliers detection behaviors.
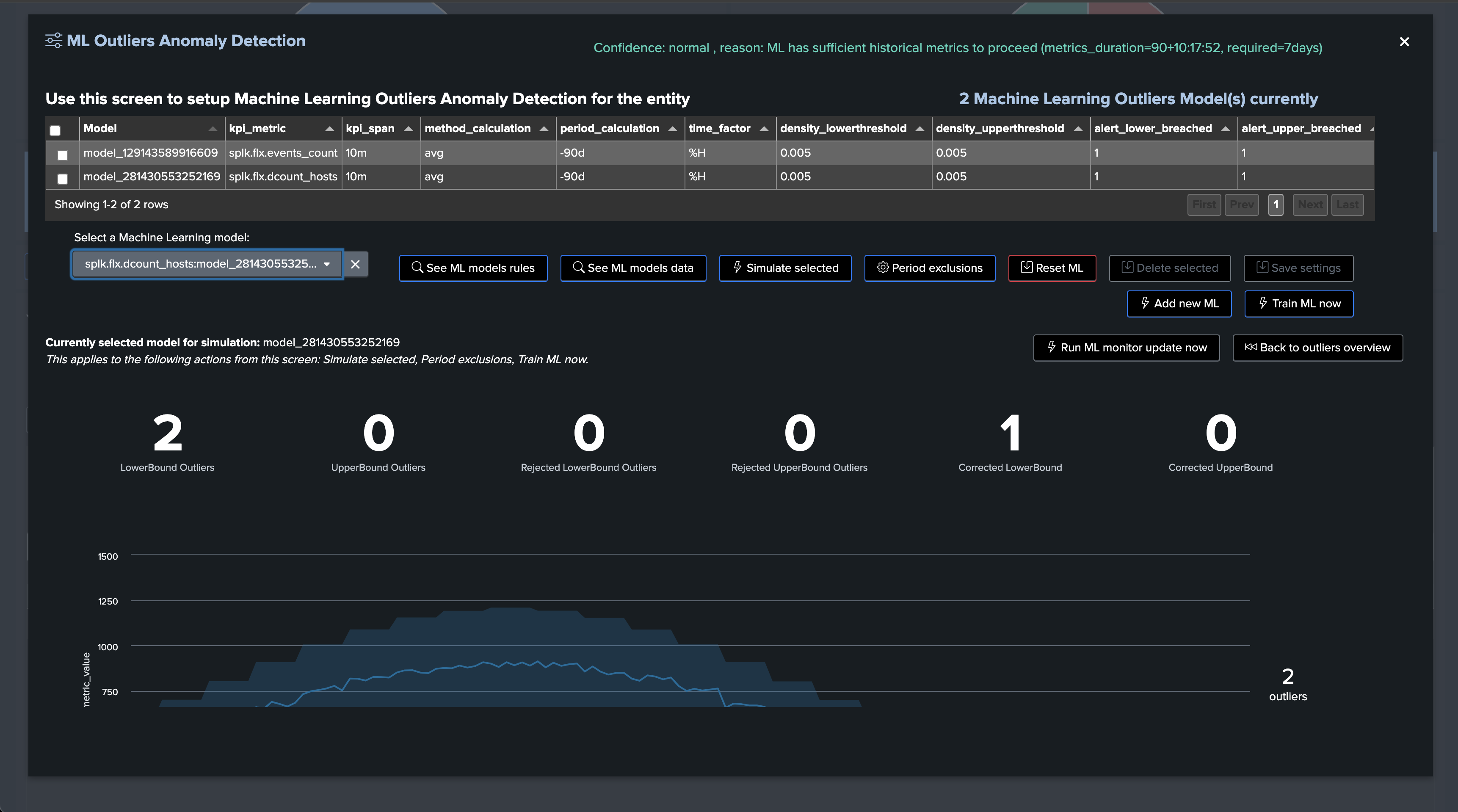
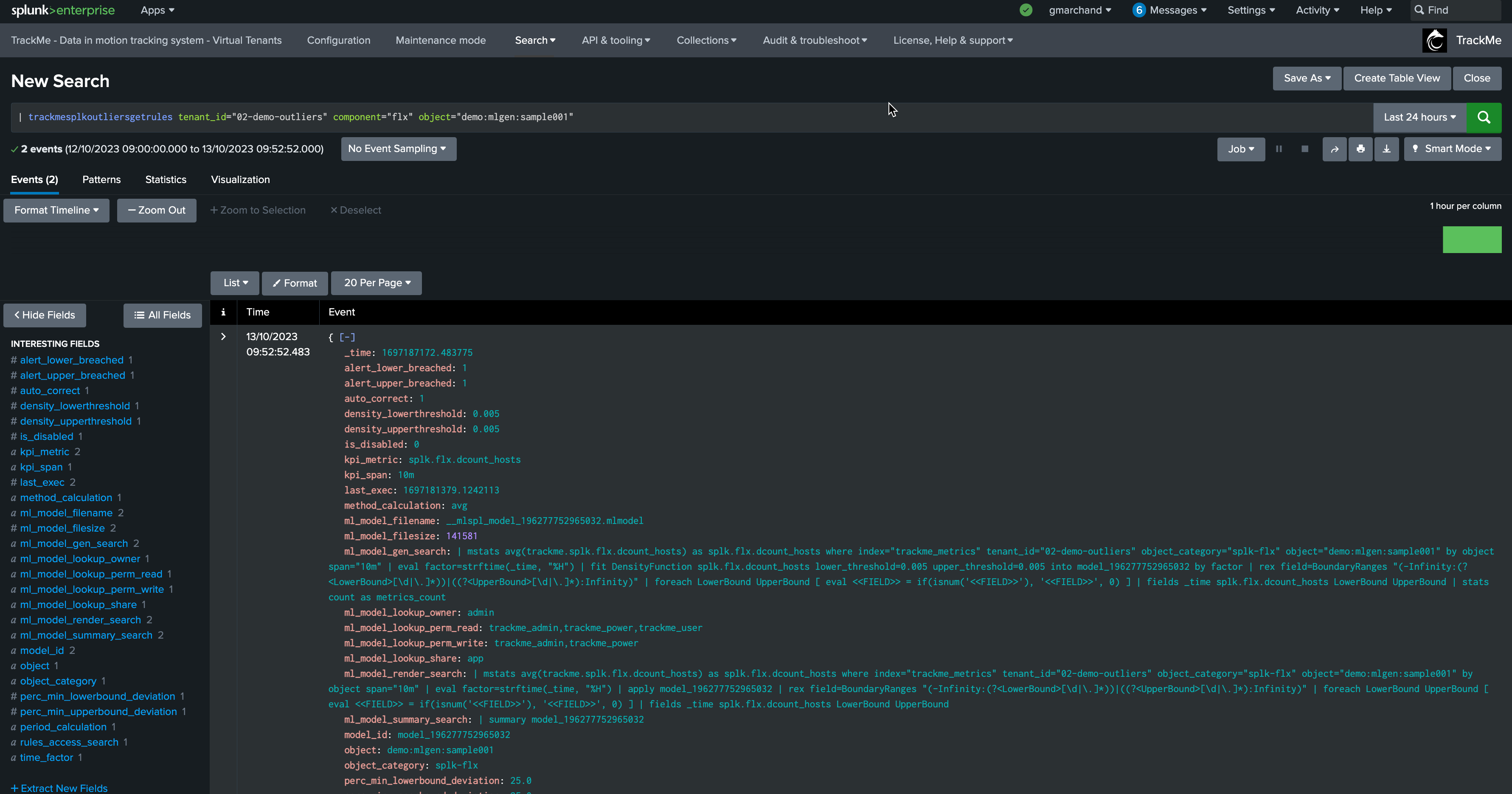
Once a true context simulation has run, the simulation model details become visible in the entity rules: (click on the button See ML models rules)
| trackmesplkoutliersgetrules tenant_id="02-demo-outliers" component="flx" object="demo:mlgen:sample001"
Fine tuning models
As we previously mentioned, our generated data has a concept of weekday behaviors, which we have not yet leveraged in the calculation.
To demonstrate this behavior, we will stop our current data generation, update our sample entity name, and generate a new data set by running the script run_backfill.sh again.
We process the same steps as previously to backfill the metrics using mcollect once the entity was discovered
Then, we edit the models to increase the period, and this time will ask TrackMe to take into account the weekdays in the outliers calculation
We can observe that the behavior is slightly different, with much closer lower bound and upper bound ranges. This is because our data is very stable and has shown enough consistency over time.
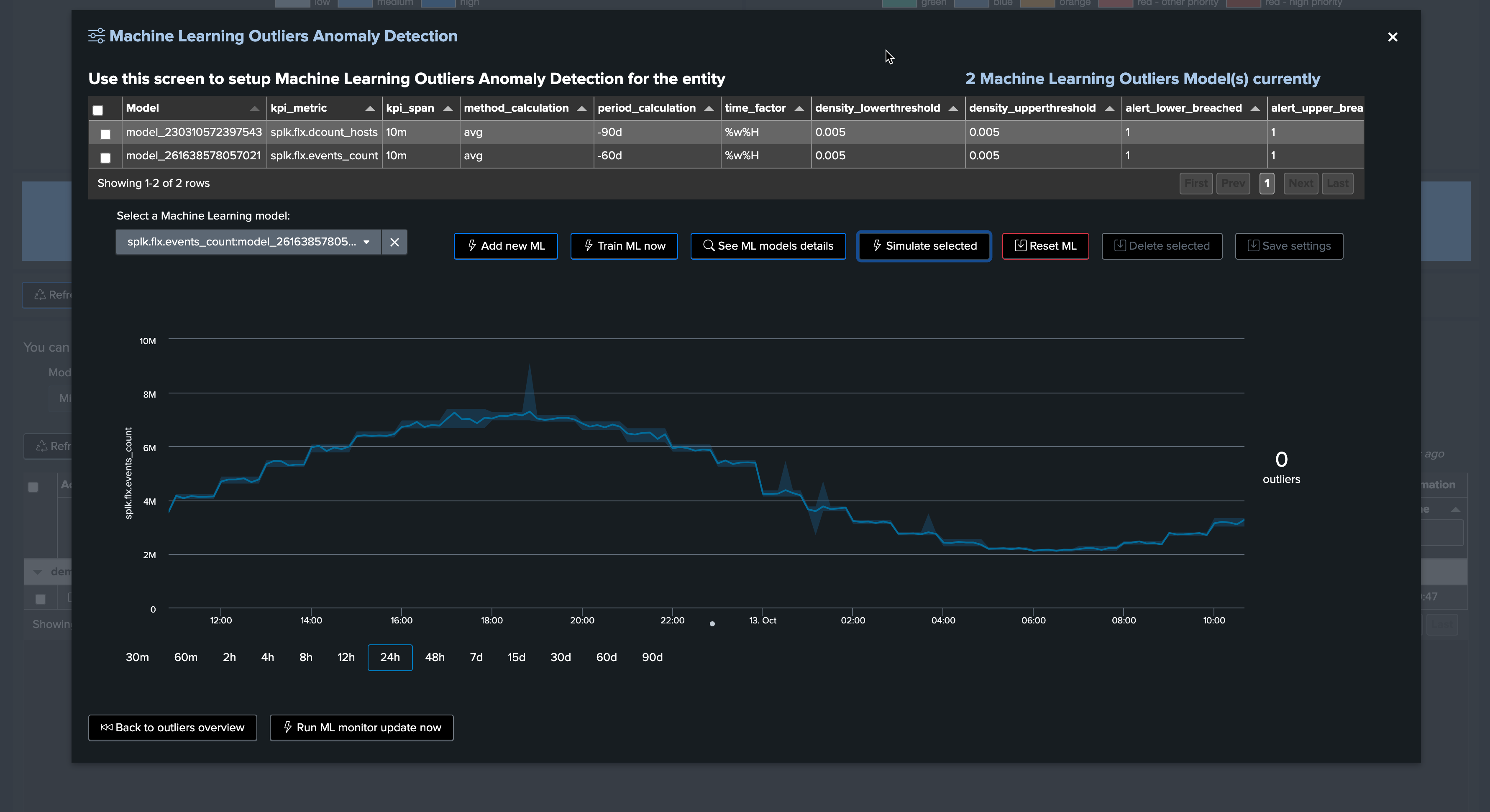
Focus last 24 hours:
Note that this also means our outlier detection will be much more sensitive, which can lead to false positive alerts.
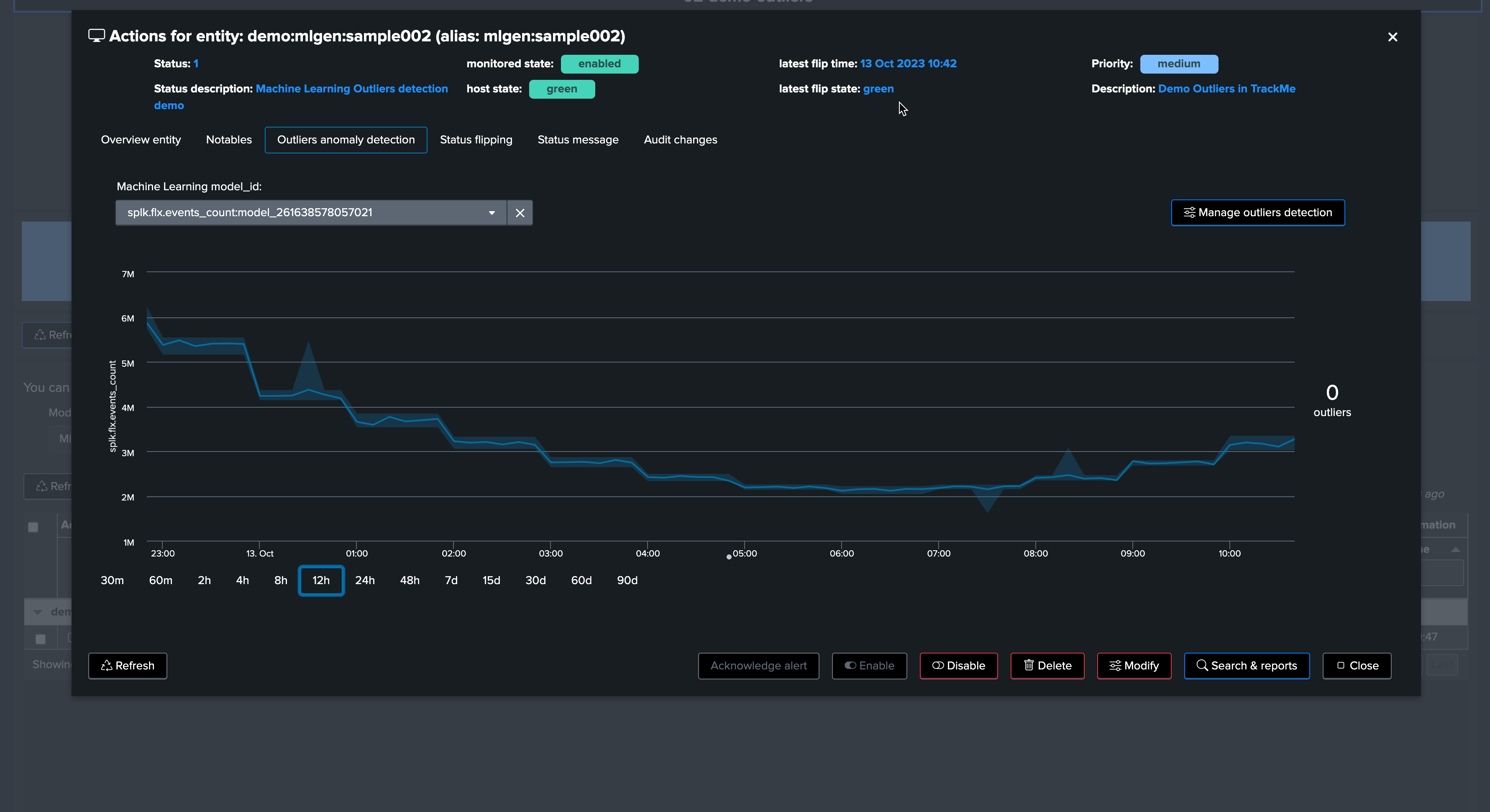
TrackMe implements a concept of “auto-correction” based on minimal variation in lower and upper dimensions, to avoid generating false positives:
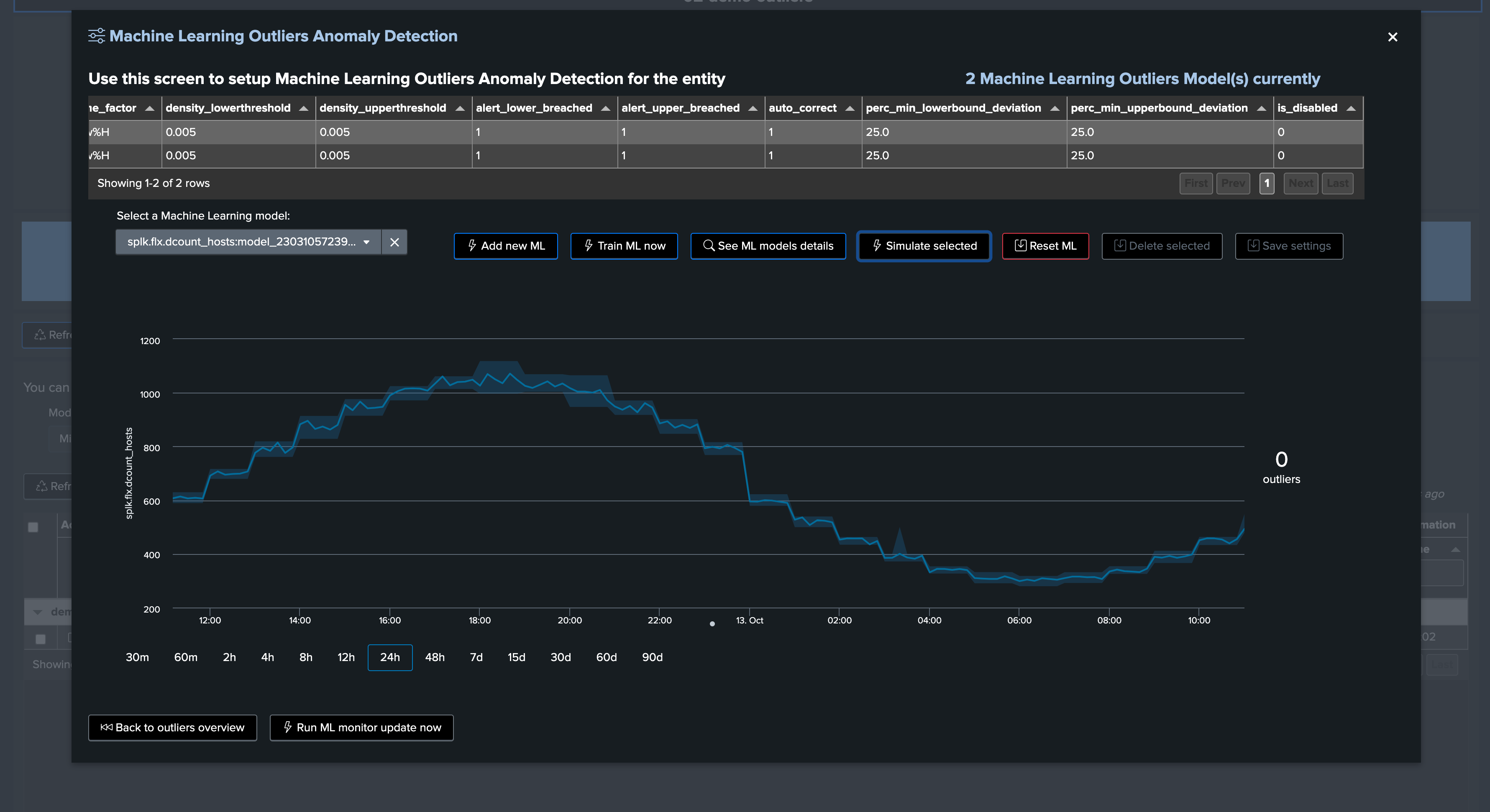
This time, we will generate upper bound outliers. We stop the current script and start run_gen_upper_outlier.sh, which slightly increases the volume of our metrics.
After a few minutes, we can observe the variation:

Shortly after, TrackMe notices the upper bound outlier:
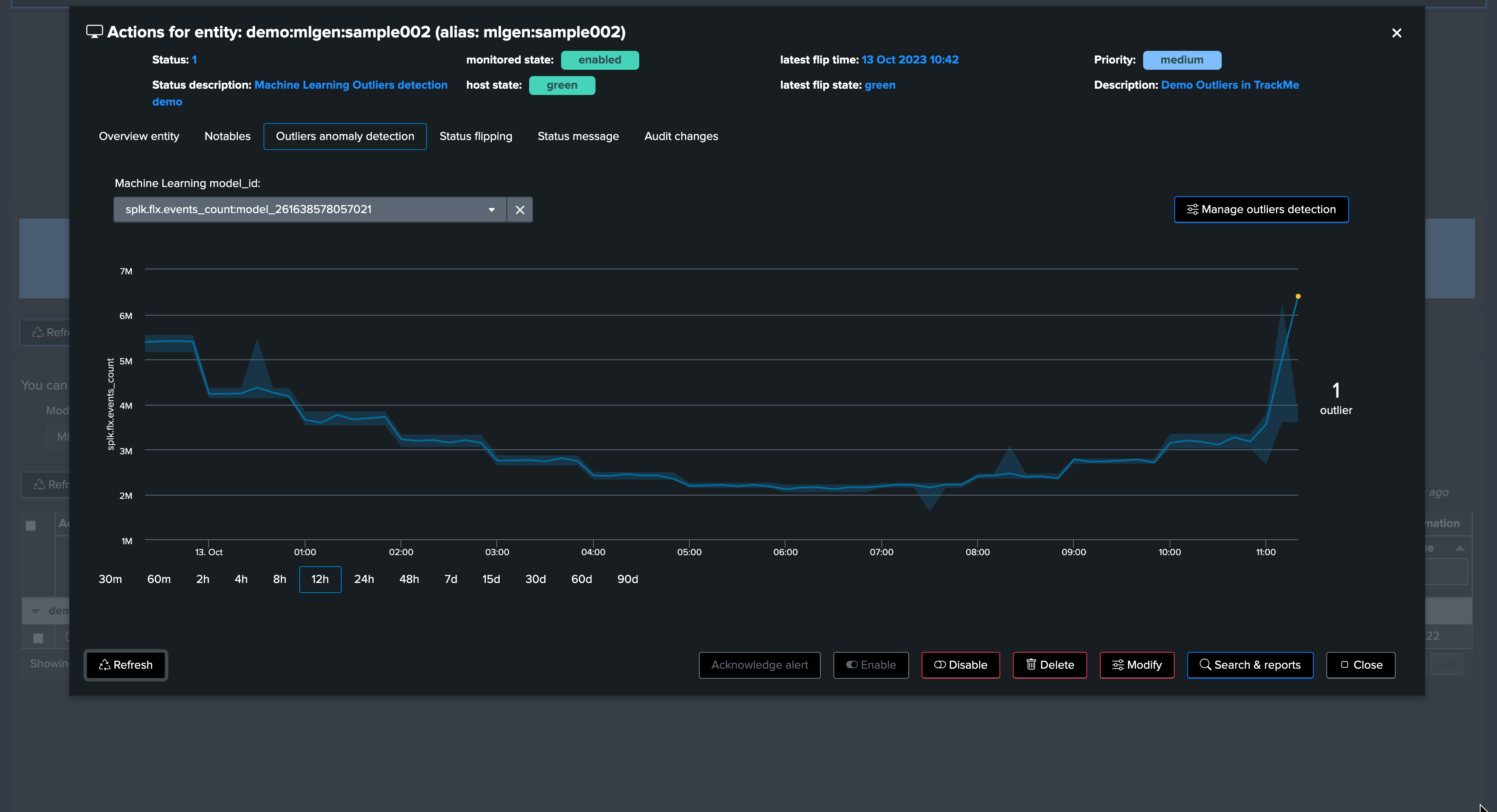
After a run of the ML monitor (which happens automatically), the upper bound condition is detected and the alert is raised accordingly.
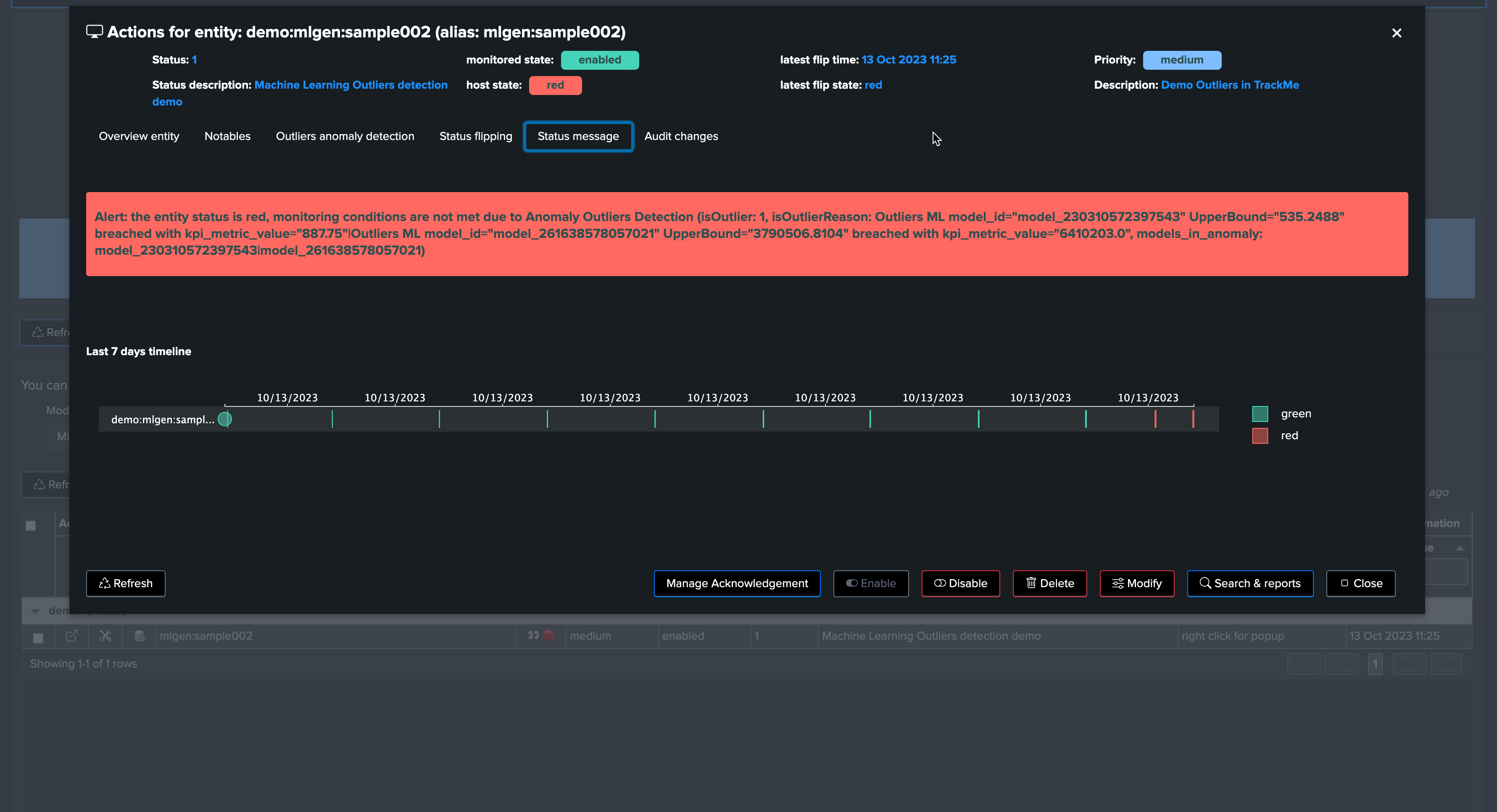
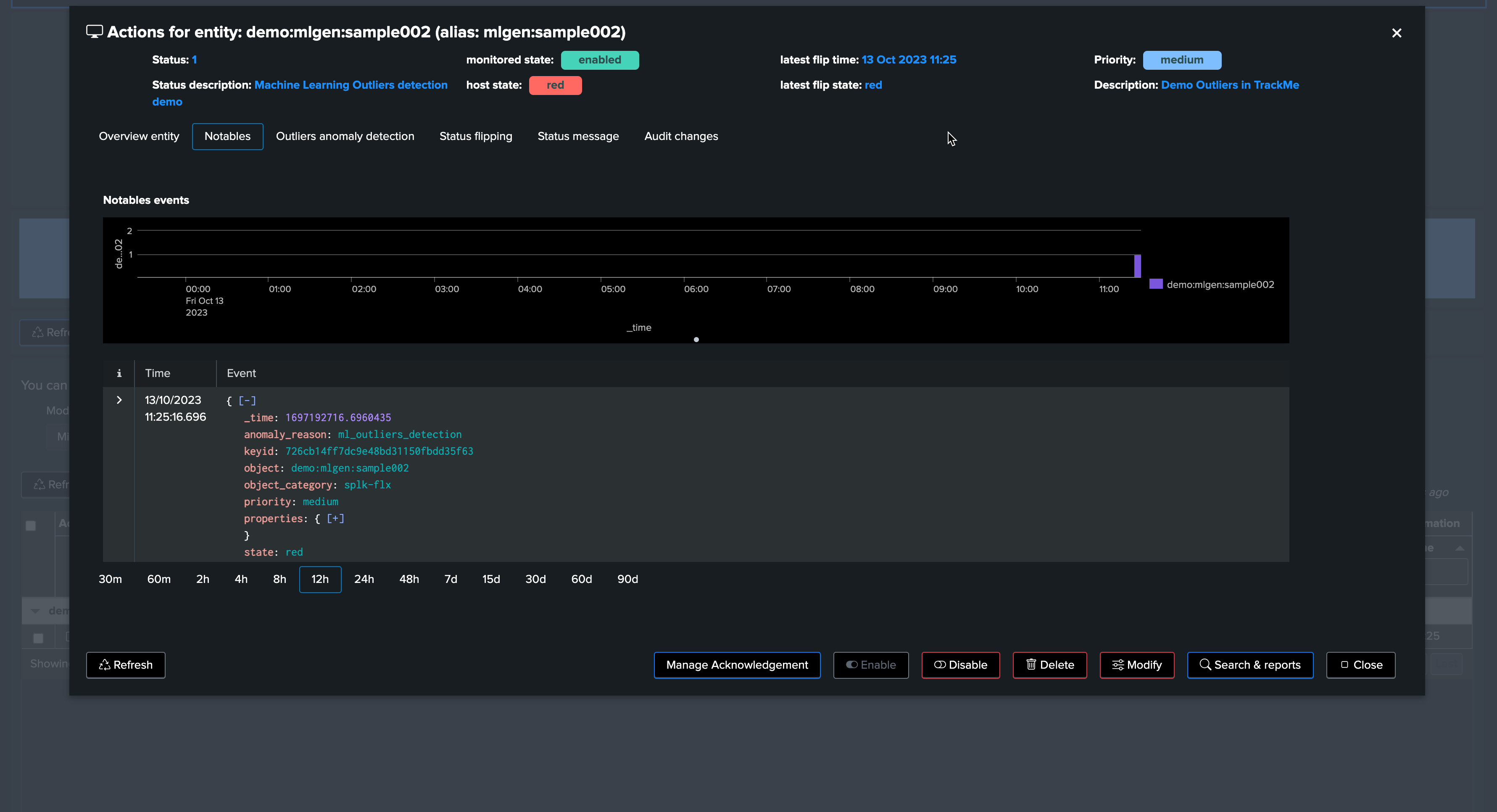
Now, let’s assume the “storm” is over. We stop the upper bound outlier generation script and instead call run_normal.sh. After some time, outliers are no longer occurring. TrackMe will notice, and the entity will return to a green status.

Soon after, TrackMe sees the entity back to green:
And the job is done!
Note that from TrackMe version 2.0.62, you can exclude the anomaly period from the ML model. This allows the ML model to learn from the data without the incident, making it more accurate in the future.
SmartStatus and Outliers
The SmartStatus is a TrackMe feature which automatically runs investigations when a given entity enters an alerting mode (red). When it comes to Outliers, the SmartStatus investigates automatically the Outliers condition:
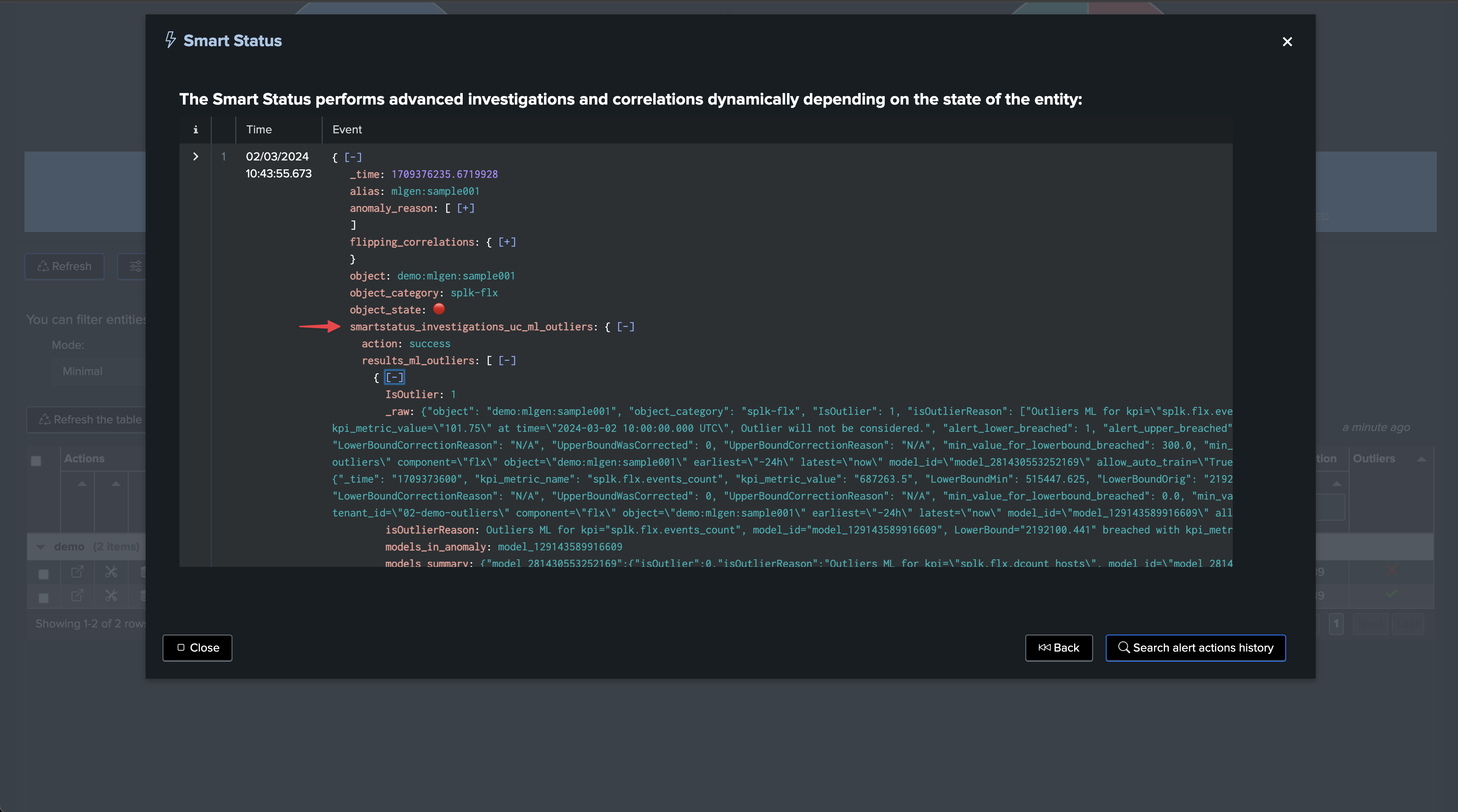
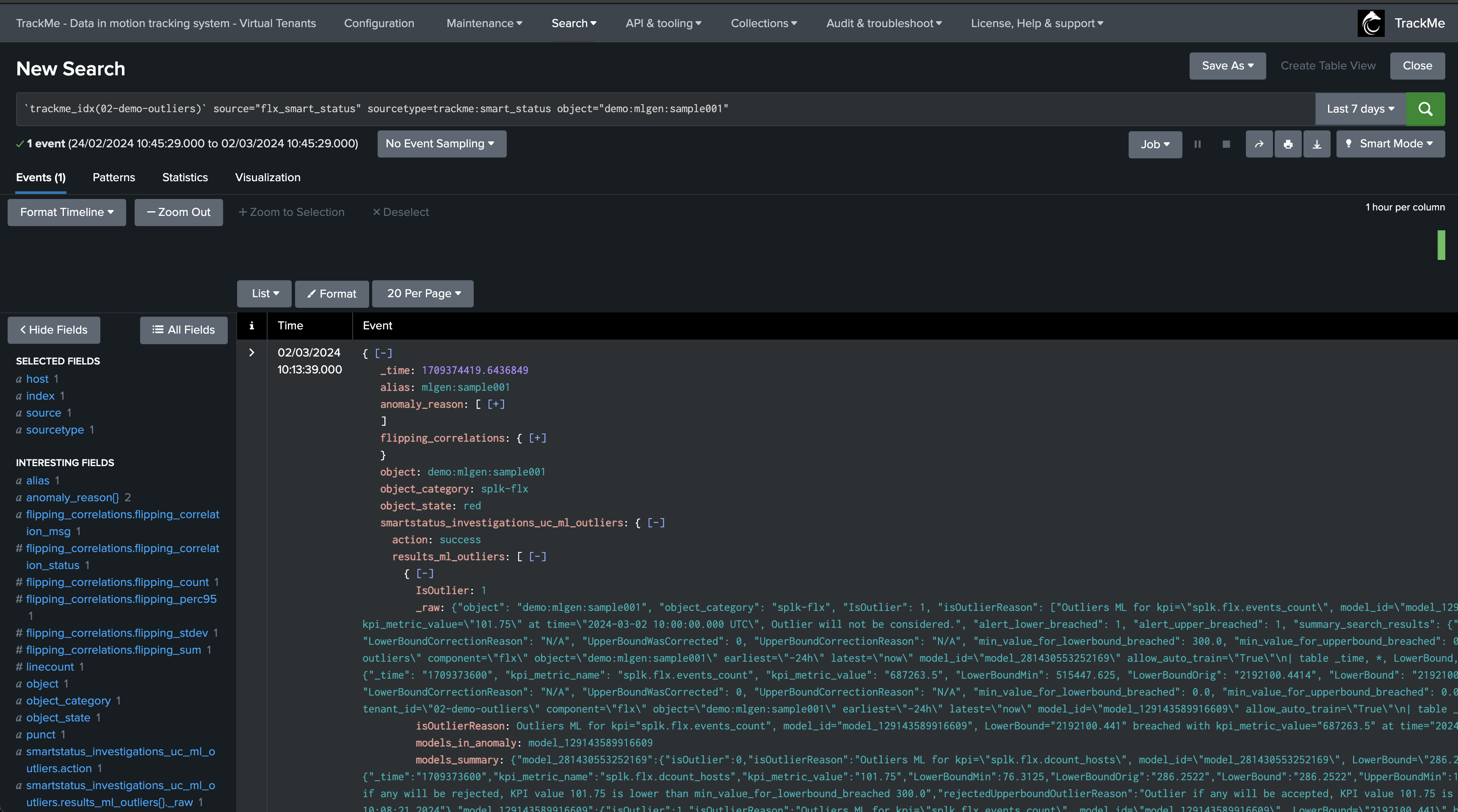
SmartStatus is also an alert action which indexes its results in TrackMe’s summary index, so you can review the actual condition when the alert came through:
`trackme_idx(02-demo-outliers)` source="flx_smart_status" sourcetype=trackme:smart_status object="demo:mlgen:sample001"
Accessing the ML models
You can access the ML models rules using the following command:
| trackmesplkoutliersgetrules tenant_id="<tenant_id>" component="<component>" object="<entity_name>"
TrackMe stores the ML models definition in a KVstore:
| inputlookup trackme_<component>_outliers_entity_rules_tenant_<tenant_id>
Accessing the ML models current results
You can access the ML models data (results) using the following command:
| trackmesplkoutliersgetdata tenant_id="<tenant_id>" component="<component>" object="<entity_name>"
TrackMe stores the ML models current results in a KVstore:
| inputlookup trackme_<component>_outliers_entity_data_tenant_<tenant_id>
Disabling alerting on Outliers
You can very simply disable alerting on Outliers on a per Virtual Tenant basis, access to the Configuration UI and the Virtual Tenant account:
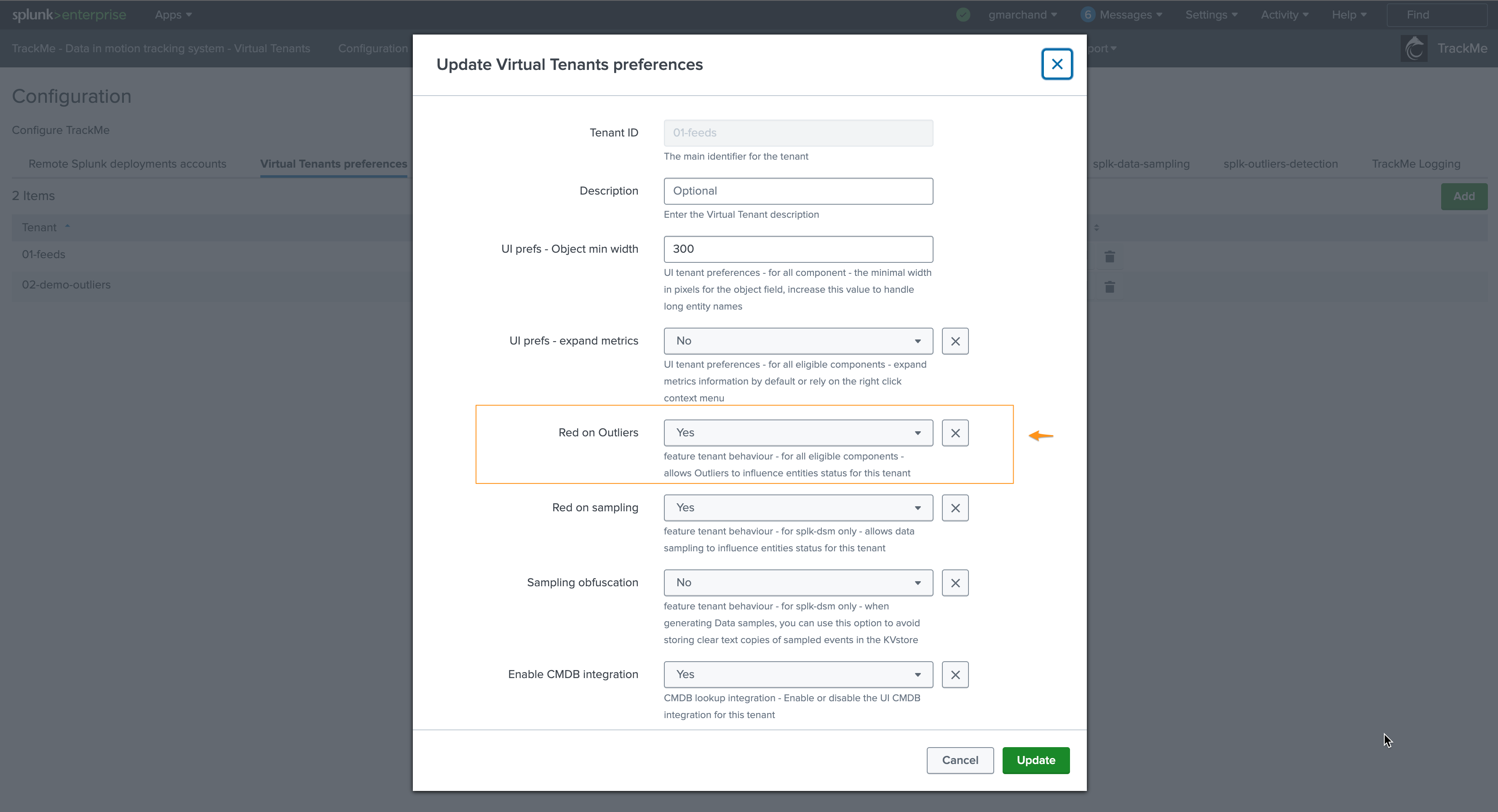
ML training scheduled jobs
When creating a Virtual Tenant, TrackMe creates a scheduled job called _ml_train_, this job is responsible for training the ML models for the entities of the tenant and a given component.
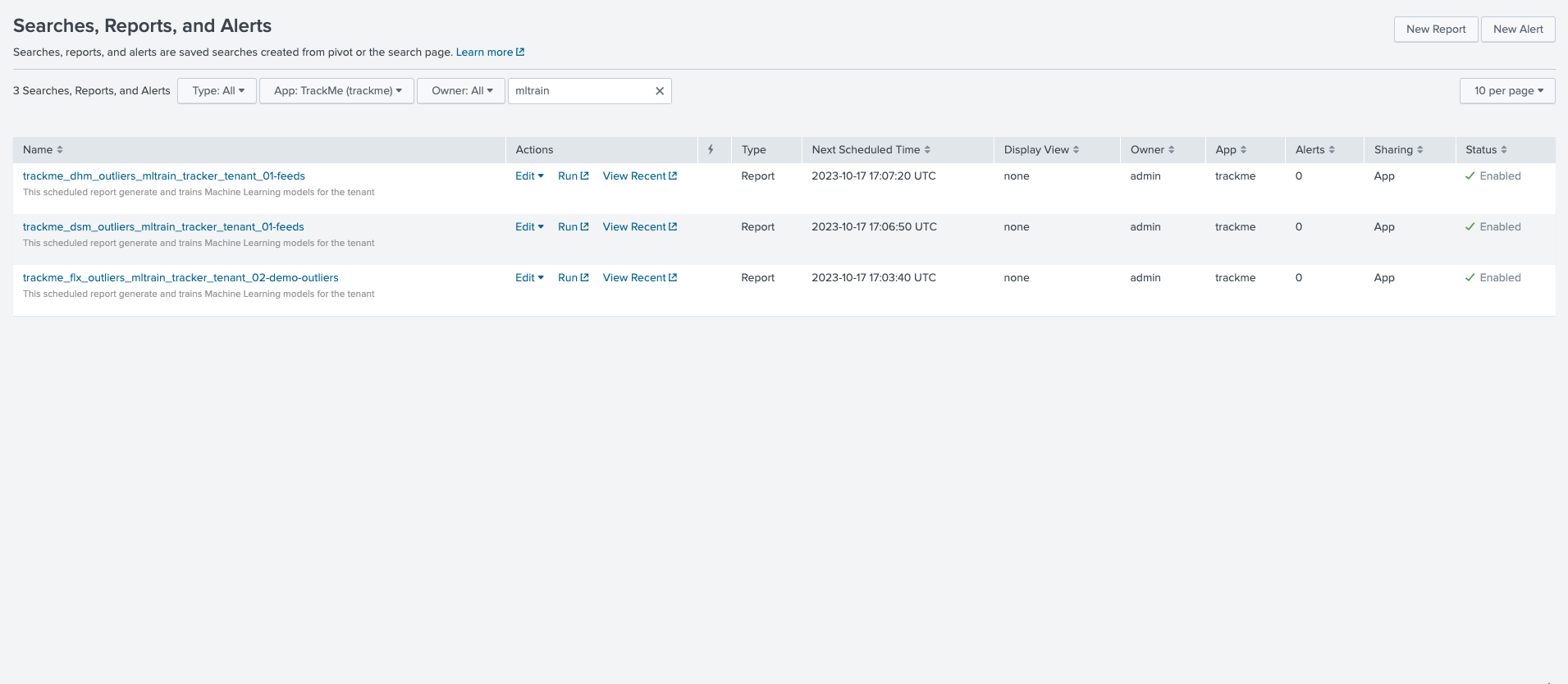
The scheduled ML training job behaves as follow:
The job is scheduled to run every once per hour
It runs for a certain amount of time which is driven by an implicit argument
max_runtimeto the commandtrackmesplkoutlierstrainhelper(defaults to 60 minutes minus a margin)
max_runtime_sec = Option(
doc="""
**Syntax:** **max_runtime_sec=****
**Description:** The max runtime for the job in seconds, defaults to 60 minutes less 120 seconds of margin.""",
require=False,
default="3600",
validate=validators.Match("max_runtime_sec", r"^\d*$"),
)
The job is influenced by system-wide options; see: ML Outliers system wide options
The job runs a first Splunk search to discover entities to be trained
The jobs log its activity as follows:
index=_internal sourcetype=trackme:custom_commands:trackmesplkoutlierstrainhelper
For instance:
2023-10-17 16:07:02,992 INFO trackmesplkoutlierstrainhelper.py generate 481 {
"tenant_id": "01-feeds",
"action": "success",
"results": "outliers models training job successfully executed",
"run_time": 11.839,
"entities_count": 12,
"processed_entities": [
{
"object_category": "splk-dsm",
"object": "webserver:apache:access:json",
"search": "| trackmesplkoutlierstrain tenant_id=\"01-feeds\" component=\"dsm\" object=\"webserver:apache:access:json\"",
"runtime": "0.5111777782440186"
},
{
"object_category": "splk-dsm",
"object": "webserver:nginx:plus:kv",
"search": "| trackmesplkoutlierstrain tenant_id=\"01-feeds\" component=\"dsm\" object=\"webserver:nginx:plus:kv\"",
"runtime": "0.5510256290435791"
},
<redacted>
],
"failures_entities": [],
"search_errors_count": 0,
"upstream_search_query": "| inputlookup trackme_dsm_outliers_entity_rules_tenant_01-feeds where object_category=\"splk-dsm\"\n | `trackme_exclude_badentities`\n | lookup local=t trackme_dsm_tenant_01-feeds object OUTPUT monitored_state\n | where monitored_state=\"enabled\"\n | eval duration_since_last=if(last_exec!=\"pending\", now()-last_exec, 0)\n | where duration_since_last=0 OR duration_since_last>=600\n | sort - duration_since_last"
}
In some cases and if you wish to reduce the number of changes performed by TrackMe, especially in a co-located SHC context (which we would recommend), you can update the scheduling plan and reduce its frequency.
After having loaded the list of entities to be trained, the ML training backend attempts to sequentially train as many entities as possible in the allowed max run time.
Each search is a highly efficient search relying on TrackMe metrics (mstats search)
Searches call the
MLTK applycommand to load the previously trained modelsSearches are driven by a TrackMe command called
trackmesplkoutlierstrainlogs are available here:
index=_internal sourcetype=trackme:custom_commands:trackmesplkoutlierstrain
ML monitor scheduled jobs
When creating a Virtual Tenant, TrackMe creates an _mlmonitor_ scheduled job, this job is responsible for monitoring the ML models for the entities of the tenant and a given component.
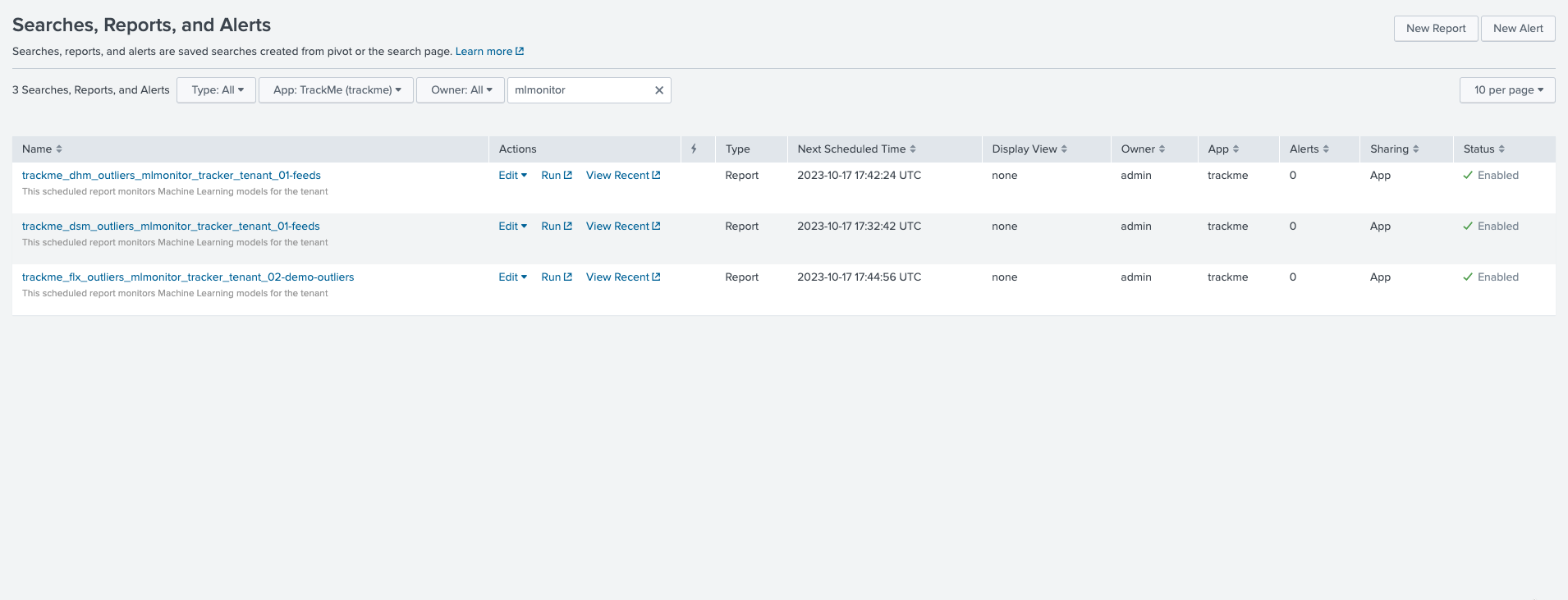
The scheduled ML monitor job behaves as follow:
The job is scheduled to run every 20 minutes
It runs for a maximum of 15 minutes (to avoid generating skipping searches), influenced by an implicit argument to the TrackMe command:
max_runtime = Option(
doc="""
**Syntax:** **max_runtime=****
**Description:** Optional, The max value in seconds for the total runtime of the job, defaults to 900 (15 min) which is subtracted by 120 sec of margin. Once the job reaches this, it gets terminated""",
require=False,
default="900",
validate=validators.Match("object", r"^\d*$"),
)
The job is influenced by system-wide options; see: ML Outliers system wide options
The job runs a first Splunk search to discover entities to be rendered
The jobs log its activity as follows:
index=_internal sourcetype=trackme:custom_commands:trackmesplkoutlierstrackerhelper
The job processes sequentially entities to be rendered and runs a highly efficient search to render the ML models using mstats, orchestrated by the TrackMe command
trackmesplkoutliersrenderThe command automatically updates the records in the outliers data KVstore collection
| inputlookup trackme_<component>_outliers_entity_data_tenant_<tenant_id>
ML period exception: excluding periods of time
From TrackMe version 2.0.62, you can exclude one or more periods of time on an ML model basis:
If an incident occurs, you can exclude the period of time where the incident happened
Doing so will allow the ML model to learn from the data without the incident, and will therefore be more accurate in the future
When the exclusion period is expired because the latest time of the period is now out of the exclusion period, this period is deleted automatically from the ML model during the next ML training phase
For instance, the following entity was impacted by abnormal behavior, we can exclude the period of time where the incident happened:
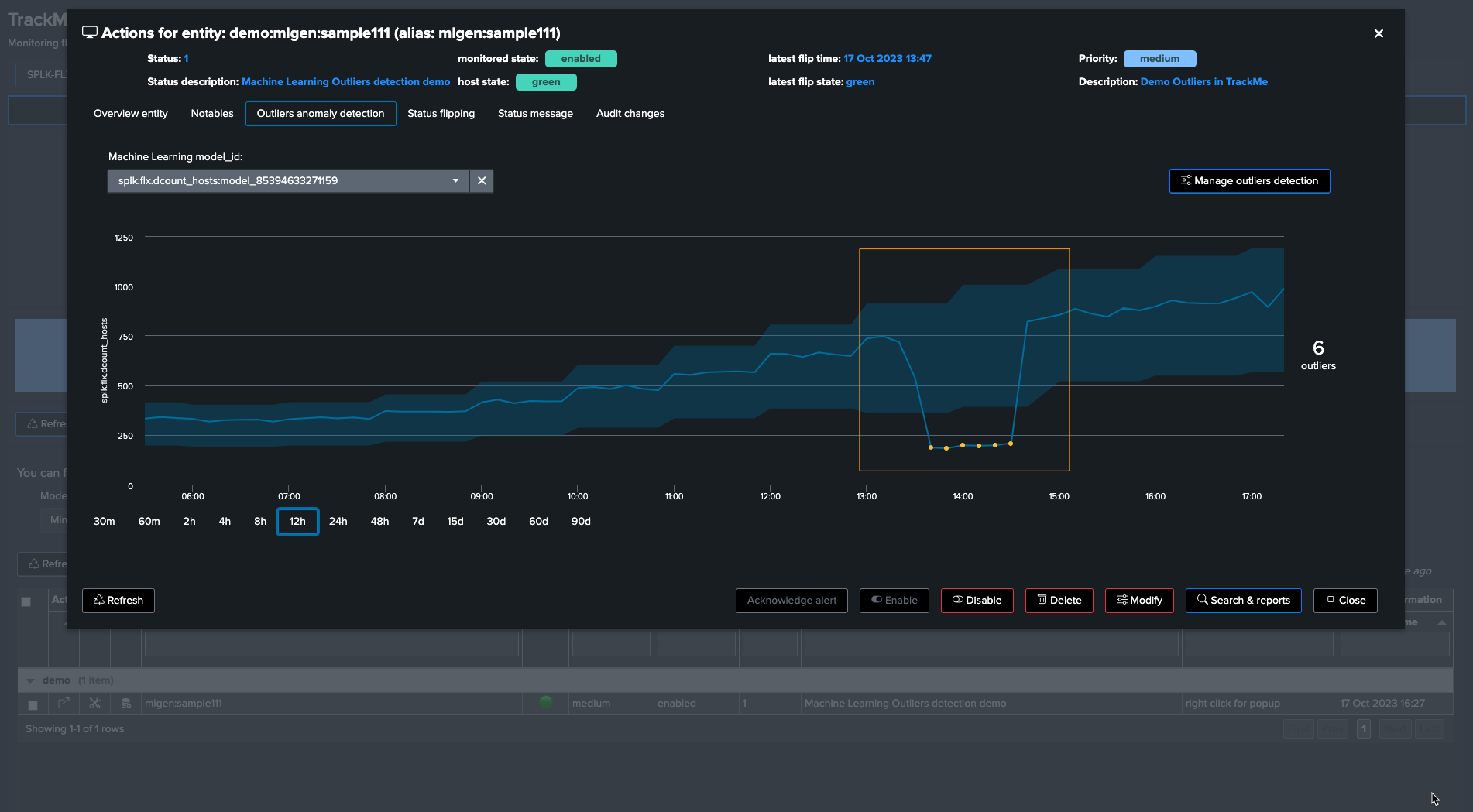
To exclude this period, click on “Manage Outliers detection” and then on “Period Exclusions”. Note that exclusions apply per ML model:
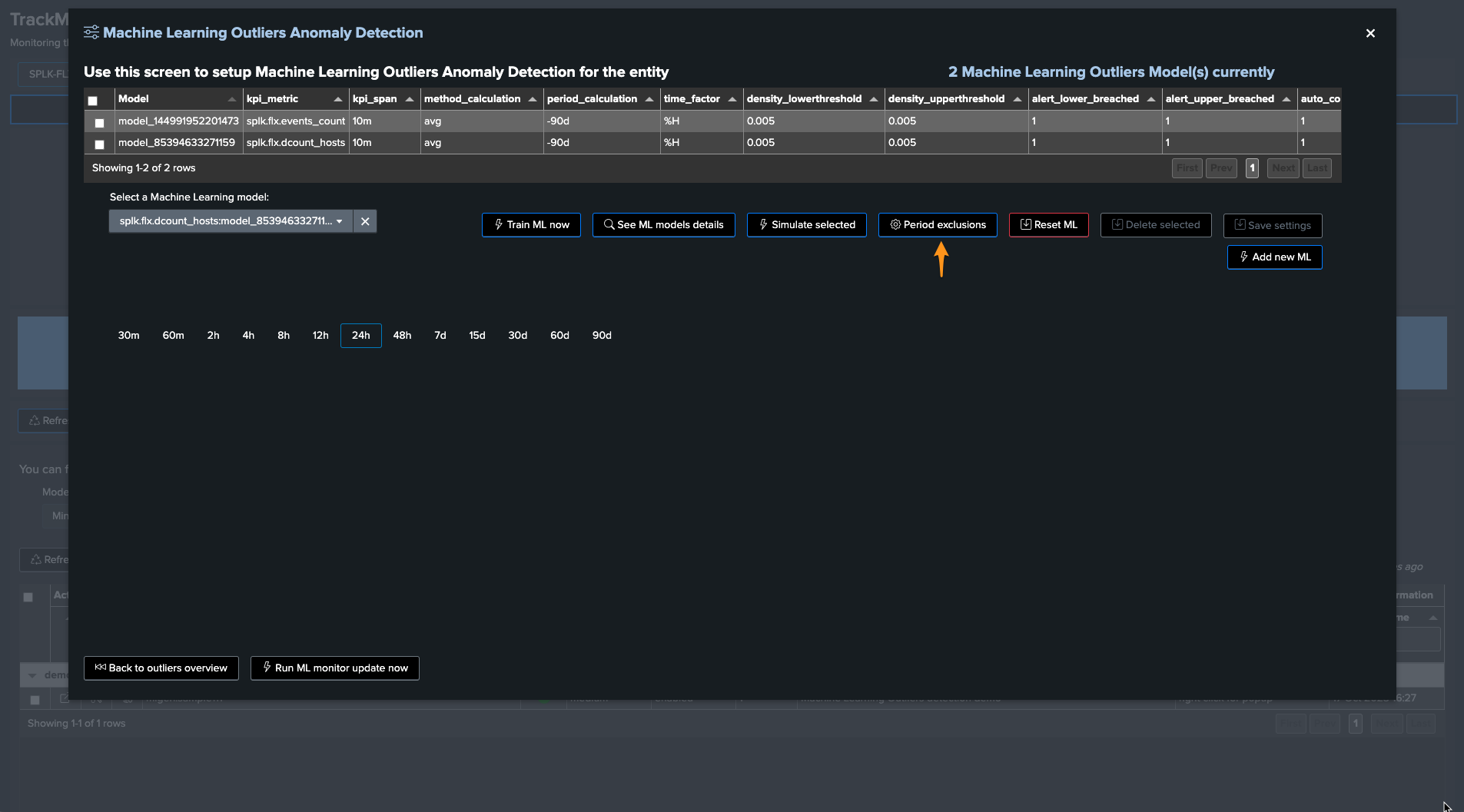
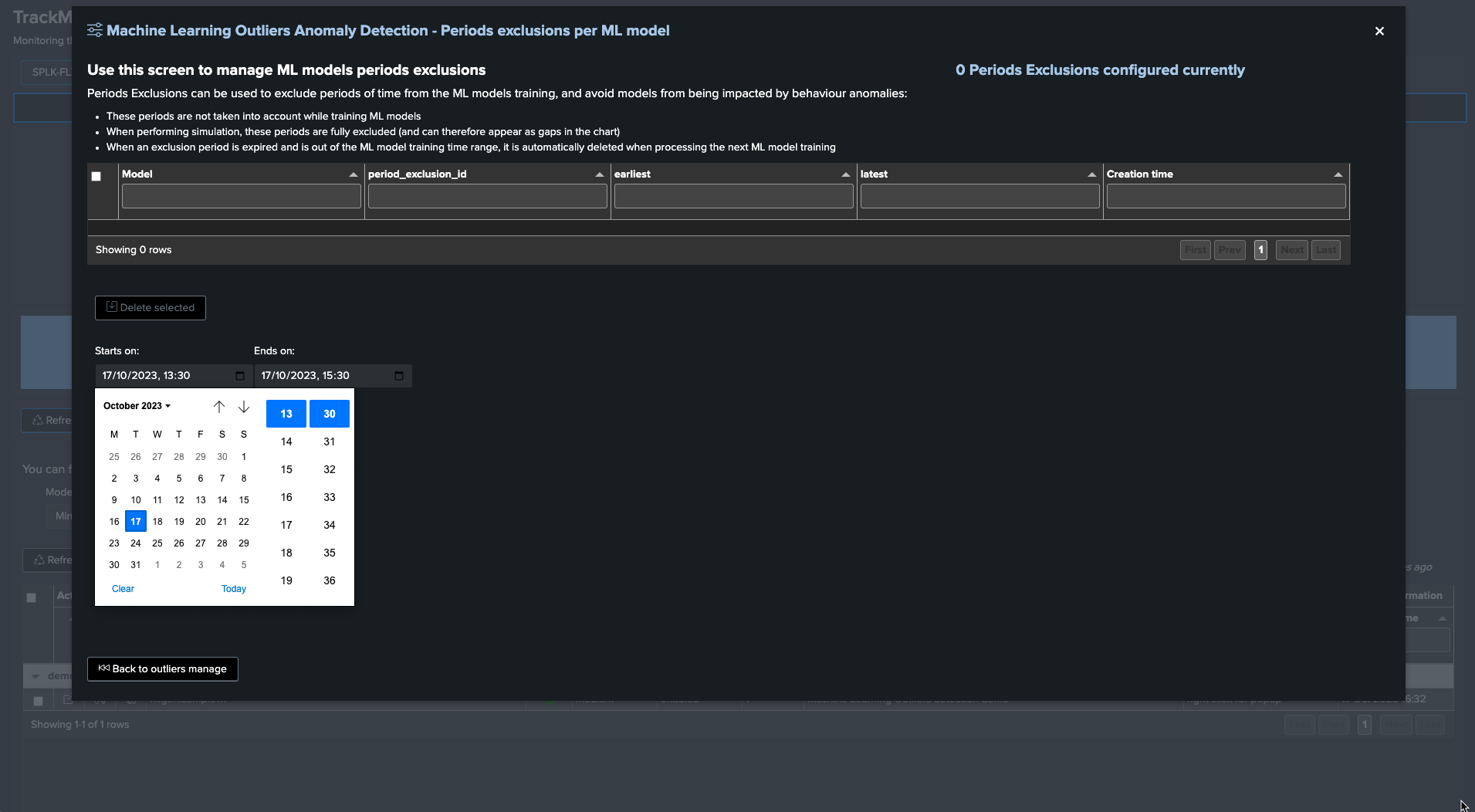
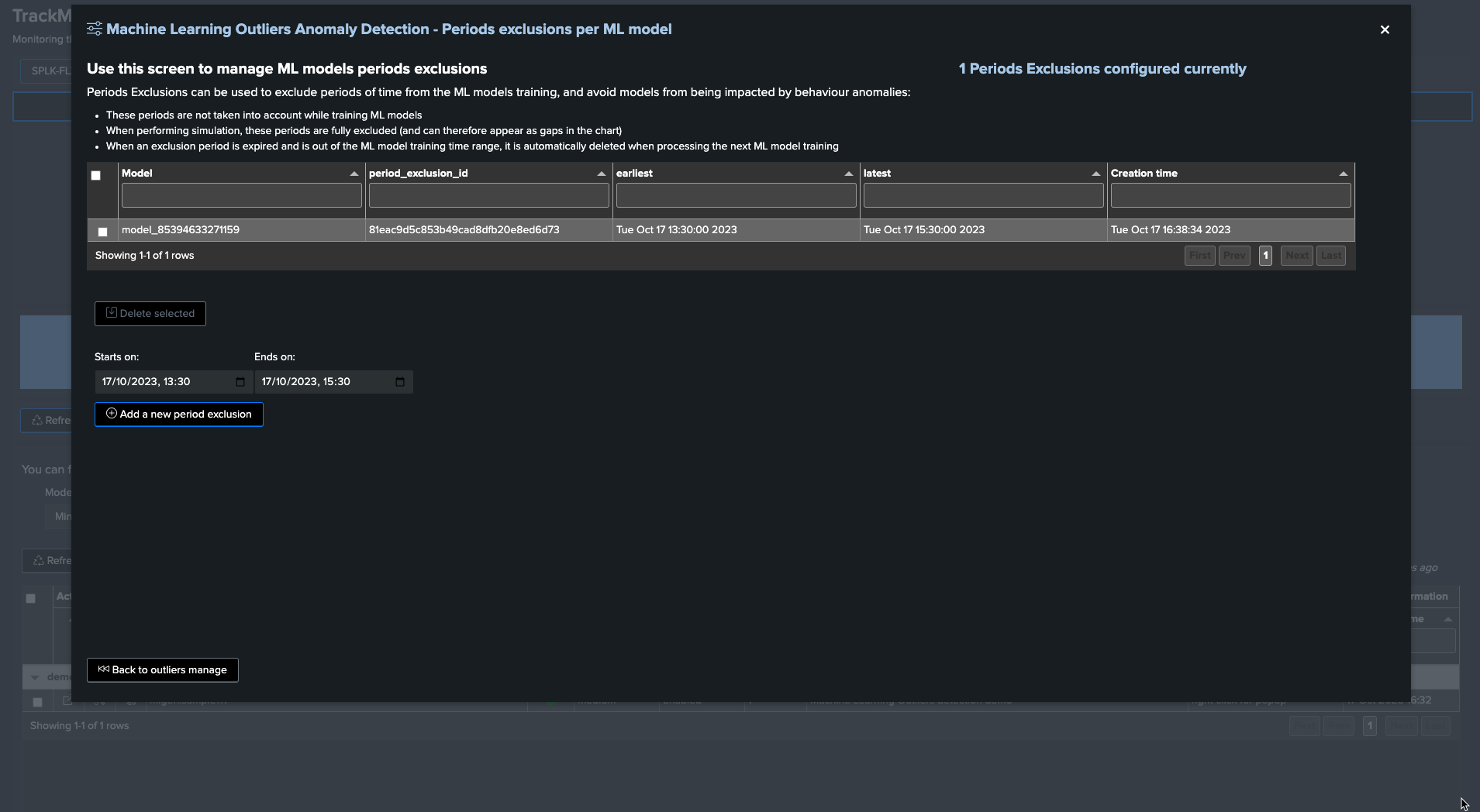
When the next ML training happens for this entity, accessing the ML models details will show the exclusion period: (click on See ML model details)
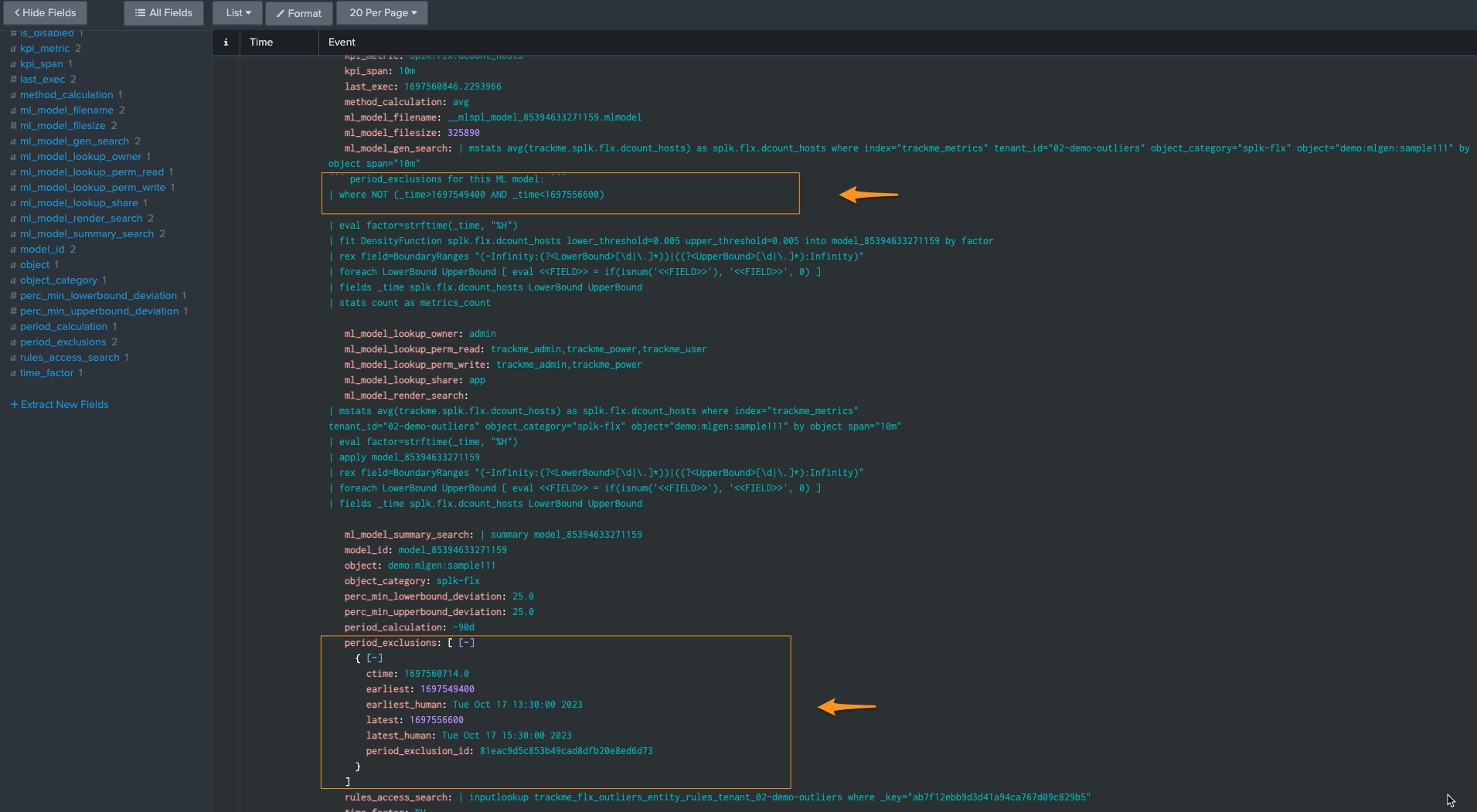
Finally, when the excluded period is out of the time range scope of the ML training, for instance if the ML is trained for the past 30 days and the exclusion period is beyond that, the exclusion period is deleted automatically:
index=_internal sourcetype="trackme:custom_commands:trackmesplkoutlierstrain" "period exclusion"
example:
2023-10-17 16:46:15,044 INFO trackmesplkoutlierstrain.py generate 486 tenant_id=02-demo-outliers, object=demo:mlgen:sample111, model_id=model_144991952201473 rejecting period exclusion as it is now out of the model period calculation: {
"period_exclusion_id": "180ea7b1a6ec737c823cfc38a6cd9414",
"earliest": 1682947800,
"earliest_human": "Mon May 1 13:30:00 2023",
"latest": 1683041400,
"latest_human": "Tue May 2 15:30:00 2023",
"ctime": "1697561162.0"
}
ML Outliers system wide options
The following options are applied globally; these influence the Outliers detection behaviours and/or ML models definition: (when entities are discovered or ML is being reset)
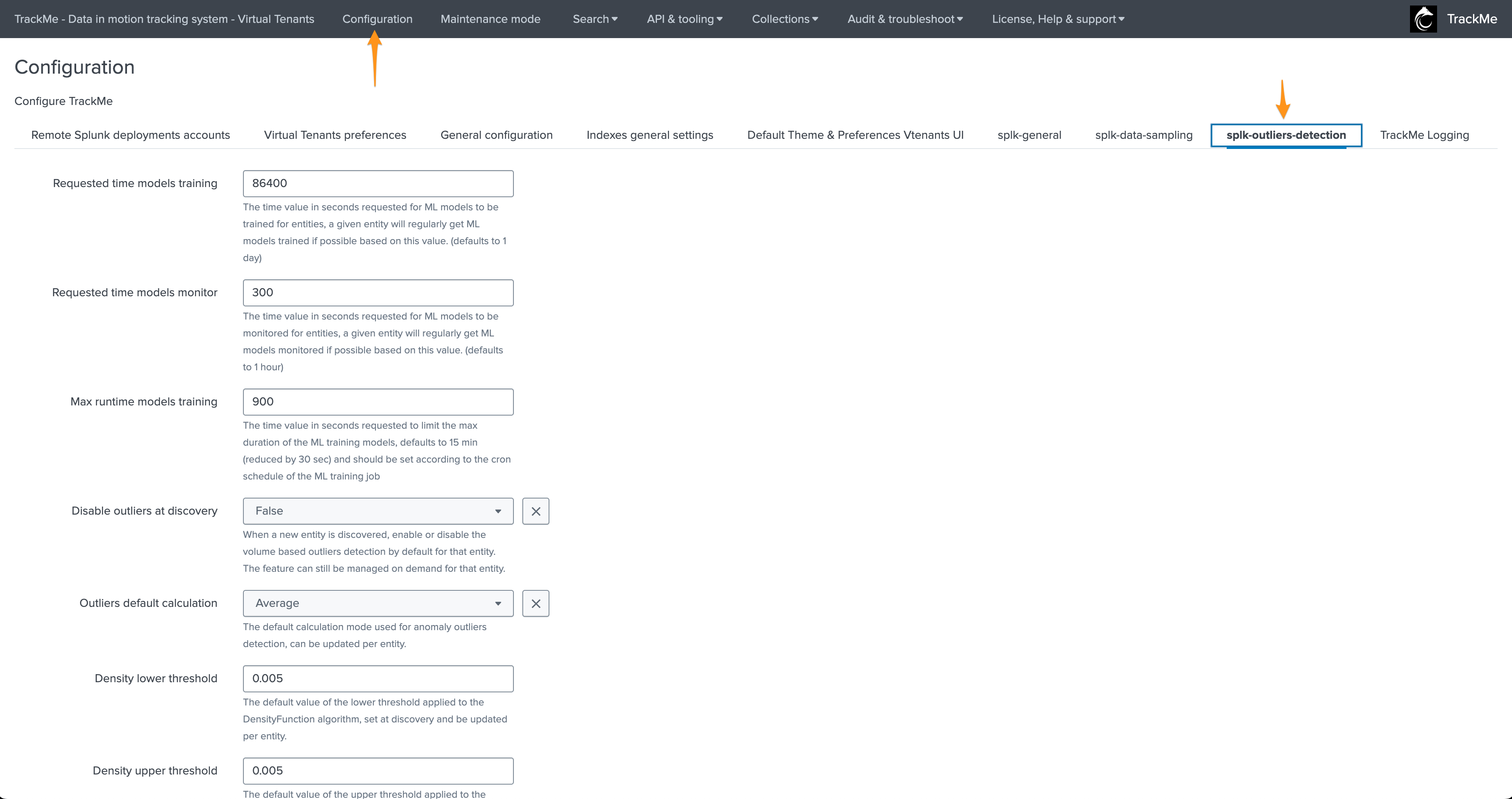
Options:
Option |
Purpose |
|---|---|
Min days historical metrics for confidence |
The minimal number of days of historical metrics required to compute the confidence level of the outliers detection, defaults to 7 days |
Requested time models training |
The time value in seconds requested for ML models to be trained for entities, a given entity will regularly get ML models trained if possible based on this value. (defaults to 1 day) |
Requested time models monitor |
The time value in seconds requested for ML models to be monitored for entities, a given entity will regularly get ML models monitored if possible based on this value. (defaults to 1 hour) |
Max runtime models training |
The time value in seconds requested to limit the max duration of the ML training models, defaults to 15 min (reduced by 30 sec) and should be set according to the cron schedule of the ML training job |
Max time since last training |
When executing a rendering operation, TrackMe verifies the last time this model was trained, if this time exceeds the value set here, the model will be retrained automatically before rendering. (defaults to 15 days) |
Disable outliers at discovery |
When a new entity is discovered, enable or disable the volume based outliers detection by default for that entity. The feature can still be managed on demand for that entity. |
Outliers default calculation |
The default calculation mode used for anomaly outliers detection, can be updated per entity. |
Density lower threshold |
The default value of the lower threshold applied to the DensityFunction algorithm, set at discovery and be updated per entity. |
Density upper threshold |
The default value of the upper threshold applied to the DensityFunction algorithm, set at discovery and be updated per entity. |
Volume lower breached |
Alert when the lower bound threshold is breached for volume based KPIs. |
Volume upper breached |
Alert when the upper bound threshold is breached for volume based KPIs. |
Latency lower breached |
Alert when the lower bound threshold is breached for volume based KPIs. |
Latency upper breached |
Alert when the upper bound threshold is breached for latency based KPIs. |
Default period for calculation |
The relative period used by default for outliers calculations, applied during entity discovery and can be updated per entity |
Default outliers time factor |
The default time factor applied for the outliers dynamic thresholds calculation |
Default latency kpi metric |
The default kpi metric for latency outliers detection |
Default volume kpi metric |
The default kpi metric for volume outliers detection |
Default auto correct |
When defining the model, enable or disable auto_correct by default, which uses the concept of auto correction based on min lower and upper deviation. |
Perc min lower deviation |
If an outlier is not deviant (LowerBound) from at least that percentage of the current KPI value, it will be considered as a false positive. |
Perc min upper deviation |
If an outlier is not deviant (UpperBound) from at least that percentage of the current KPI value, it will be considered as a false positive. |
splk_outliers_mltk_algorithms_list |
TrackMe uses the MLTK DensityFunction algorithm. You can add custom algorithms as a comma-separated list of values; these will become selectable automatically in the different Outliers configuration screens in TrackMe. |
splk_outliers_mltk_algorithms_default |
If you have multiple algorithms, you can define here which algorithm should be used by default when TrackMe defines the ML models rules, which happens usually at the entities discovery, or when adding/resetting ML models. |
splk_outliers_fit_extra_parameters |
You can optionally add extra parameters to be added to the MLTK fit command (training phase) at the time of the definition of the ML rules (generally when entities are discovered), for instance: exclude_dist=”beta” to exclude Beta distributions for the density function, see MLTK documentation for more information. |
splk_outliers_apply_extra_parameters |
You can optionally add extra parameters to be added to the MLTK apply command (rendering phase) at the time of the definition of the ML rules (generally when entities are discovered), for instance: sample=”True”, see MLTK documentation for more information. Default is empty for no extra parameters. |
splk_outliers_boundaries_extraction_macro_default |
This defines the name of the boundaries extraction macro which is used when defining ML models rules, usually at the time of the entity discovery or when defining a new model. |
splk_outliers_boundaries_extraction_macros_list |
This defines the list of boundaries macros. If you need to define a custom macro to extract boundaries according to a custom algorithm, you can add a comma-separated list of macros which will become automatically selectable in TrackMe Outliers management screens. |
ML Outliers options
Options per ML models can be accessed via the TrackMe UI:
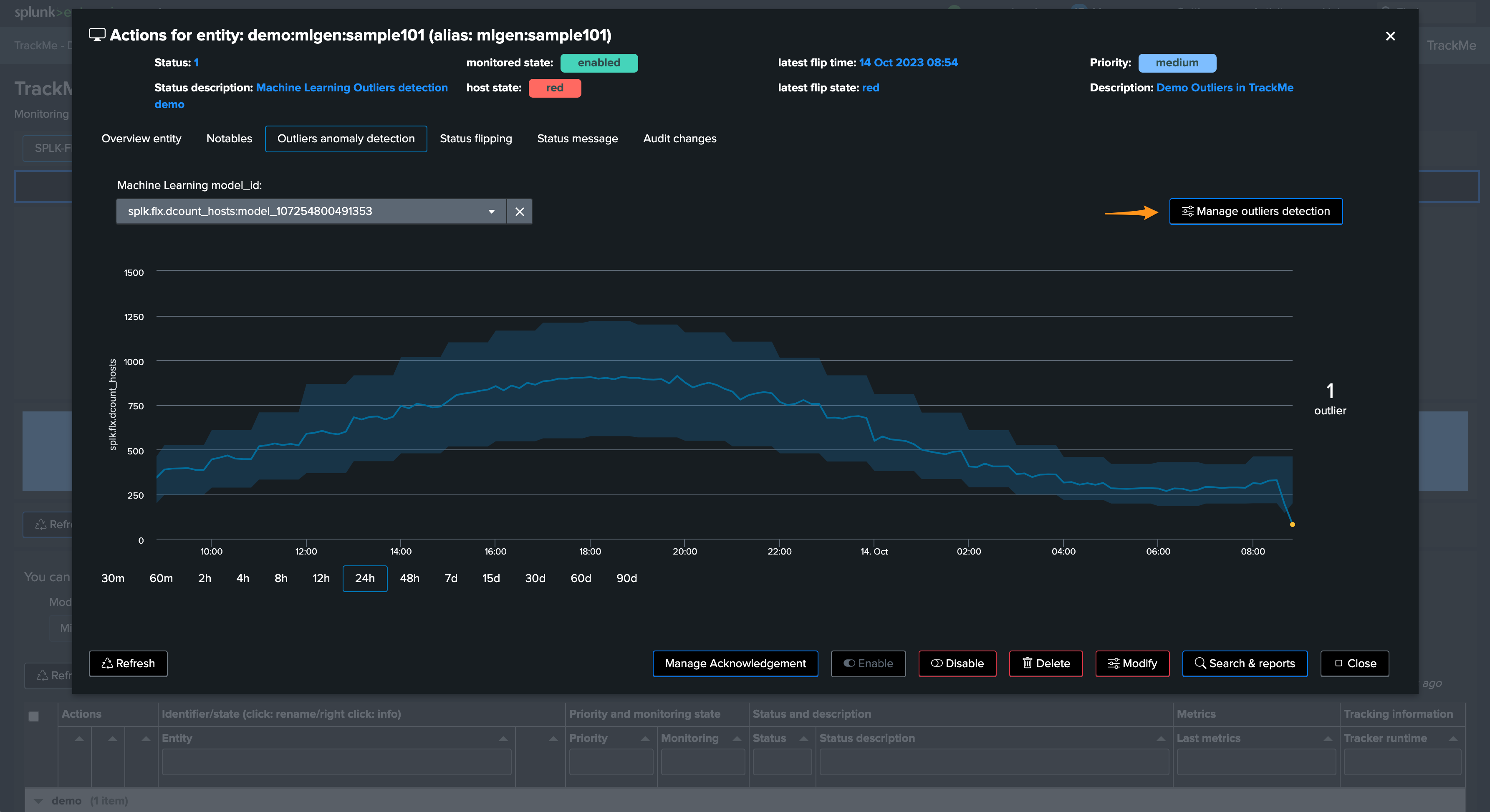
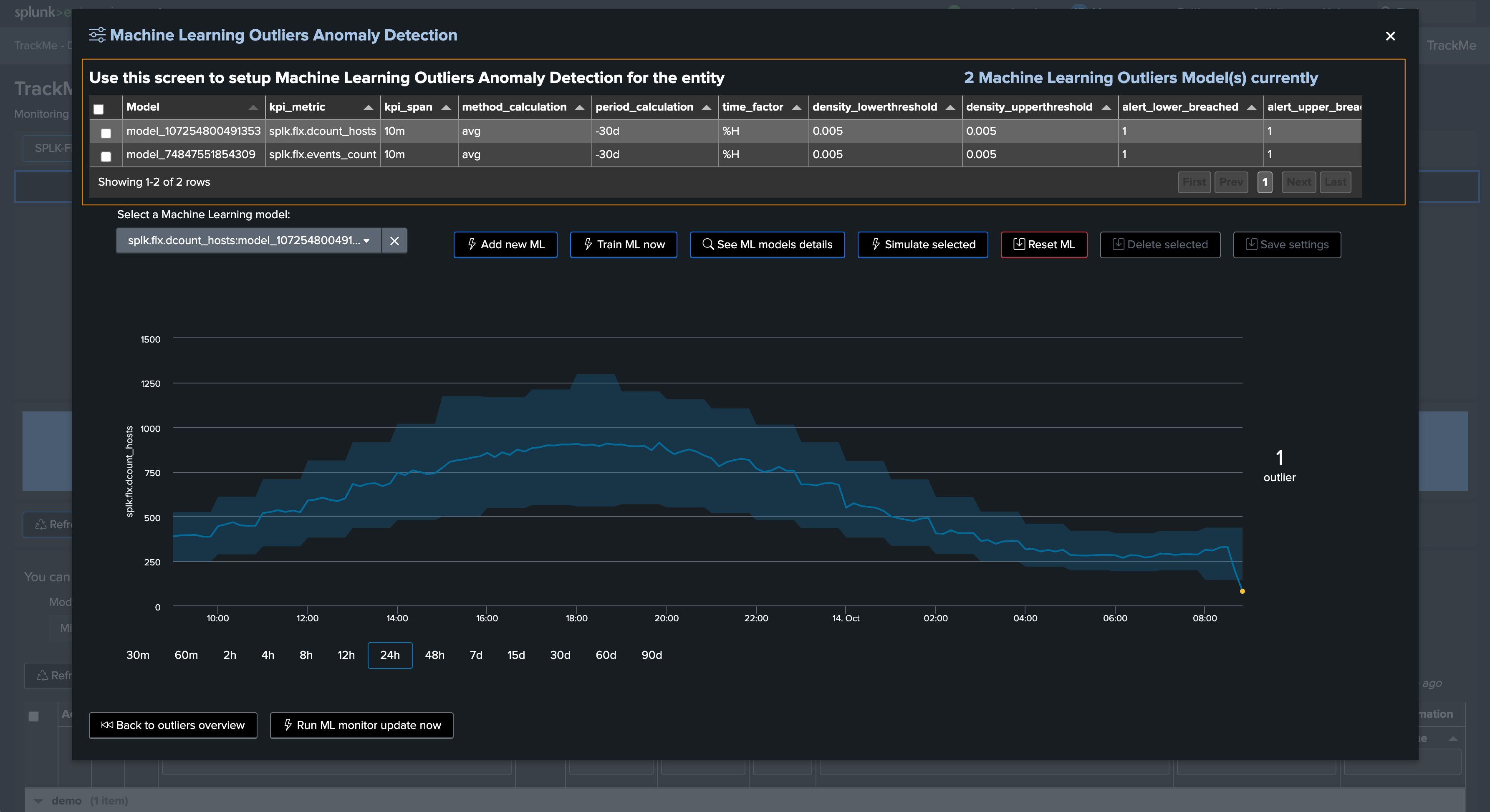
The following options can be defined per ML Outlier model:
Option |
Purpose |
|---|---|
kpi_metric |
The Key Performance Indicator associated with the ML model |
kpi_span |
The span time value used for the calculations |
method_calculation |
The calculation method to be applied (e.g., average, perc95…) |
period_calculation |
The period for the calculation for the model training purposes |
time_factor |
Defines the time-based granularity for the ML model training |
density_lowerthreshold |
The lower bound threshold for the MLTK density function |
density_upperthreshold |
The upper bound threshold for the MLTK density function |
auto_correct |
Enable or disable the auto-correction features; its goal is to limit false positives using the deviation settings |
perc_min_lowerbound_deviation |
The min percentage of deviation between the lower bound and the KPI current value |
perc_min_upperbound_deviation |
The min percentage of deviation between the upper bound and the KPI current value |
alert_lower_breached |
Alert if the lower threshold is breached |
alert_upper_breached |
Alert if the upper threshold is breached |
min_value_for_lowerbound_breached |
The min value for the lower bound to be breached, outliers below this will be rejected |
min_value_for_upperbound_breached |
The min value for the upper bound to be breached, outliers above this will be rejected |
is_disabled |
Enable or disable training and monitoring for this model |
Understanding and Troubleshooting ML rendering results
When TrackMe calls the ML rendering, the following command is called:
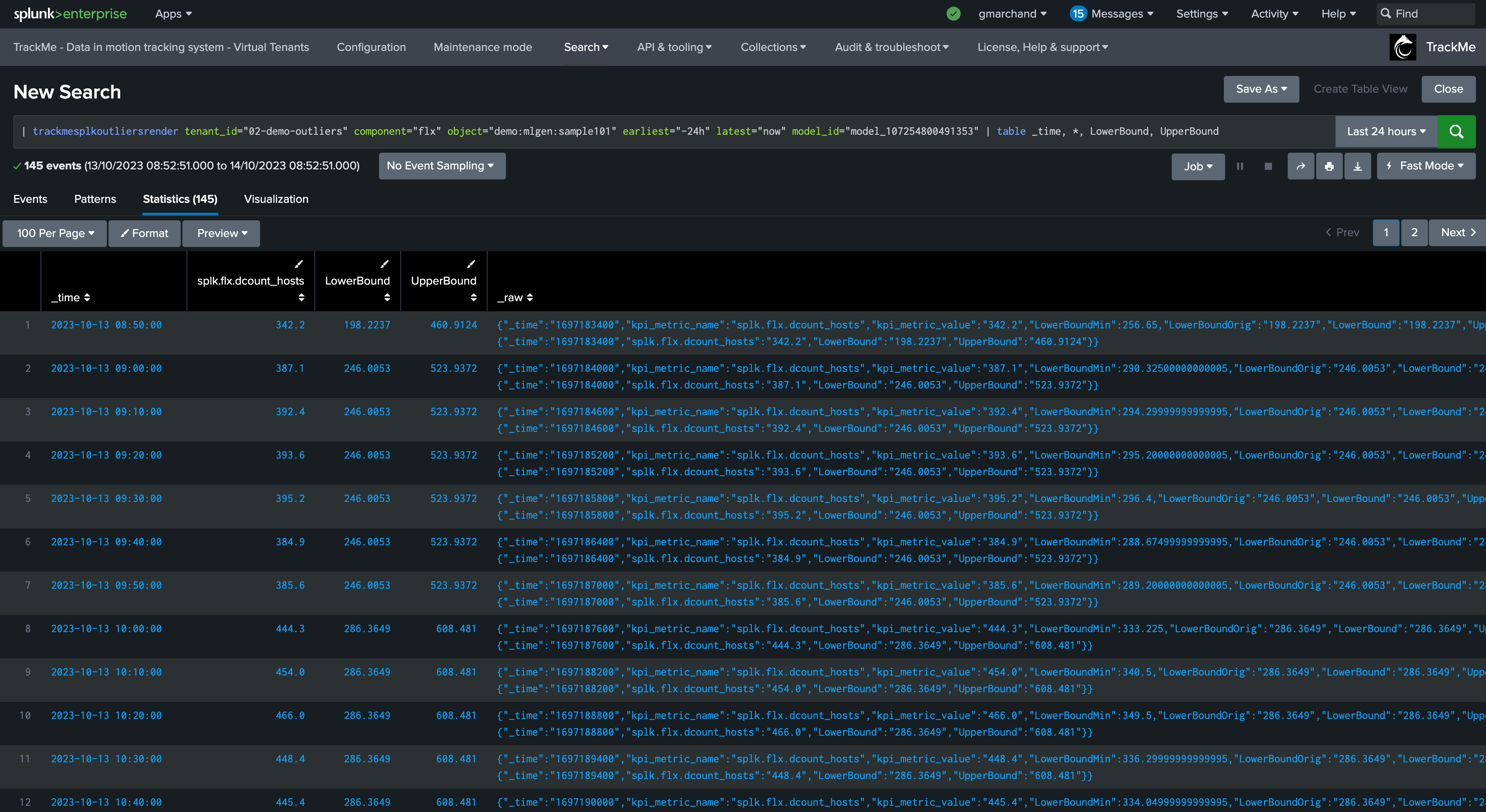
You can go in statistics mode and add the following SPL to review in details the ML decisions:
| fields _time, _raw
| trackmeprettyjson fields=_raw
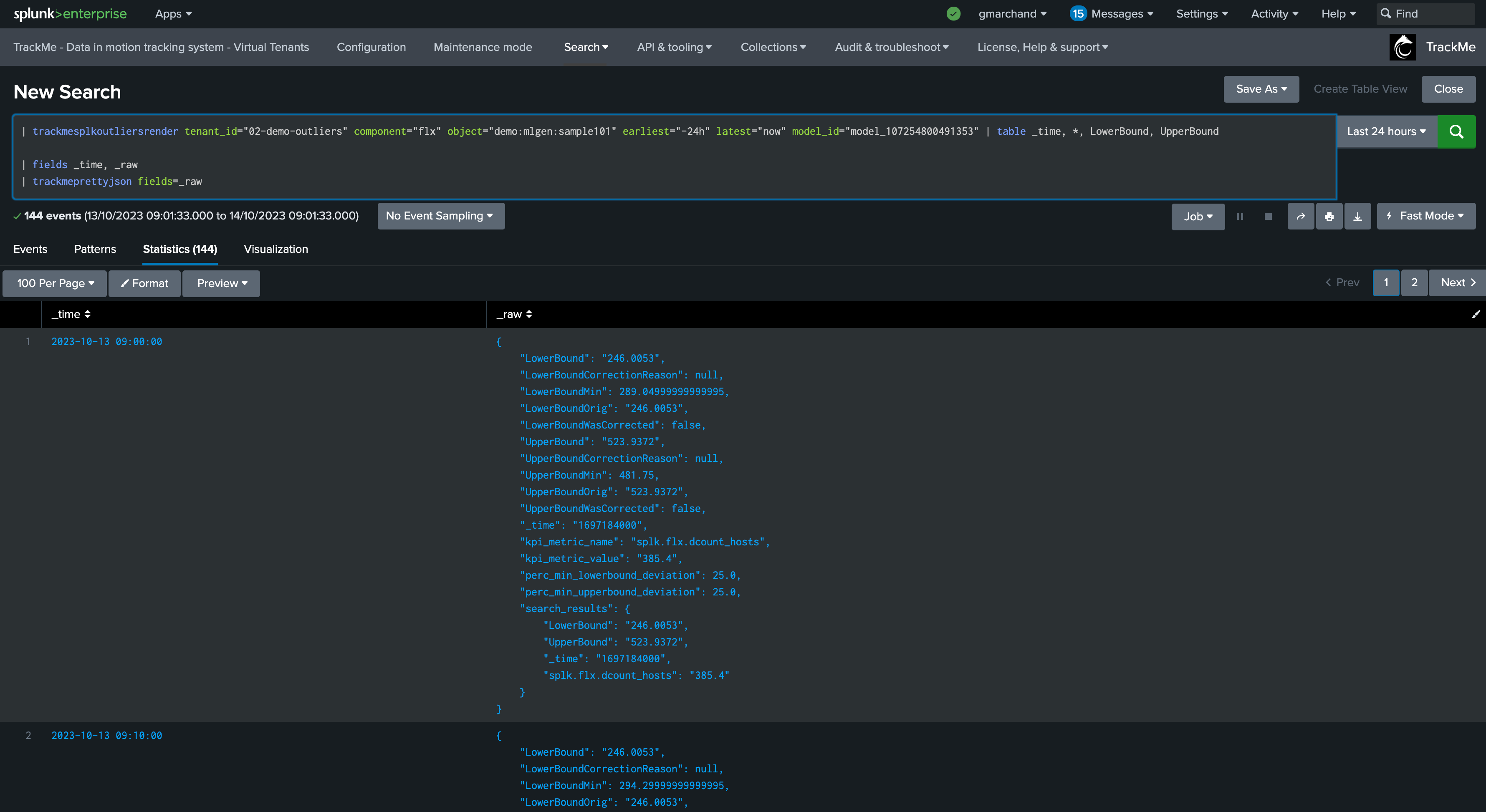
The JSON object contains various information such as the origin MLTK rendering results per time frame, and TrackMe Auto correction decisions.
While in simulation mode, the same command is called with the simulation definition of the ML instead:
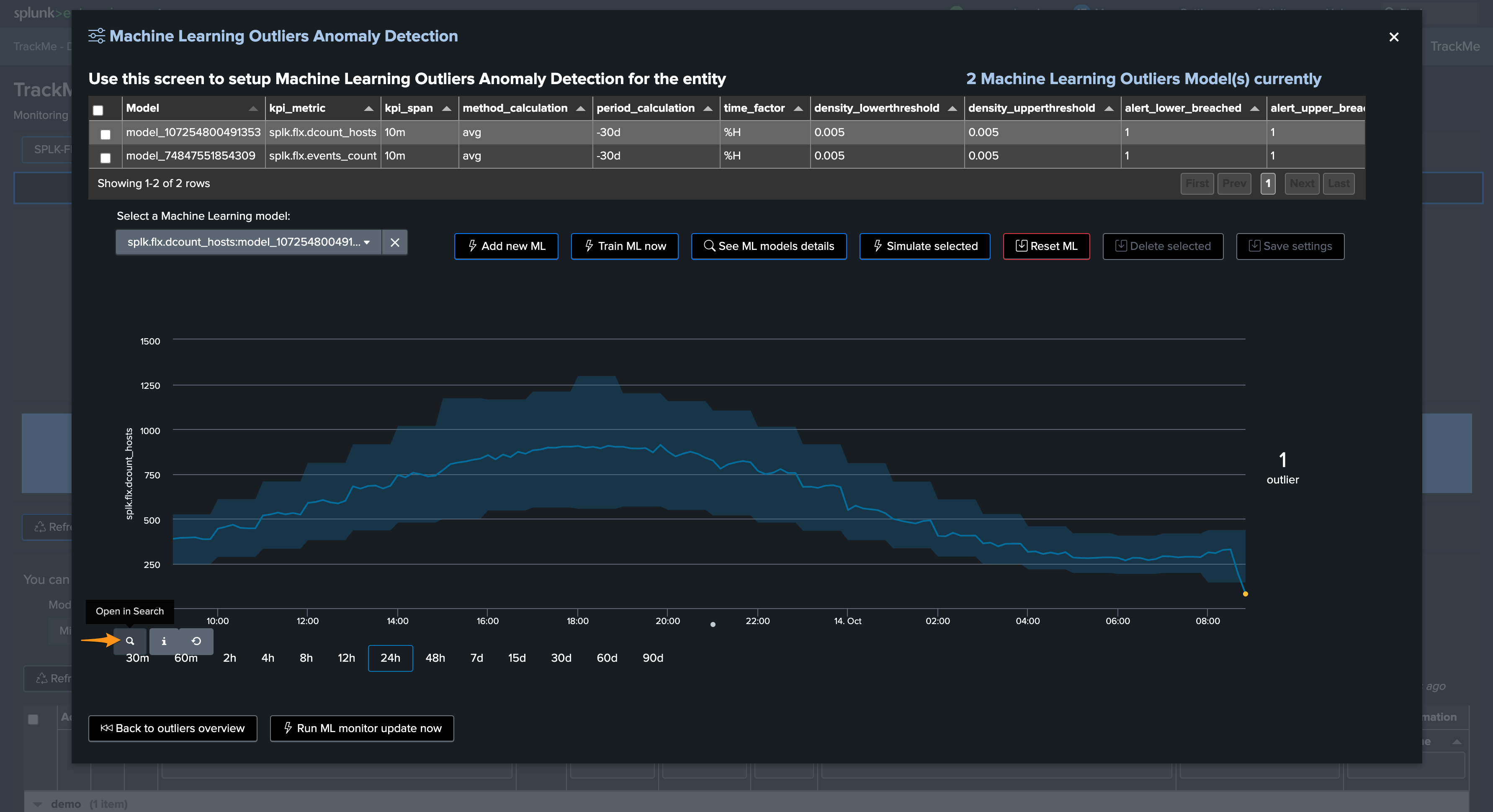
You can apply the same SPL lines to review the ML decisions:
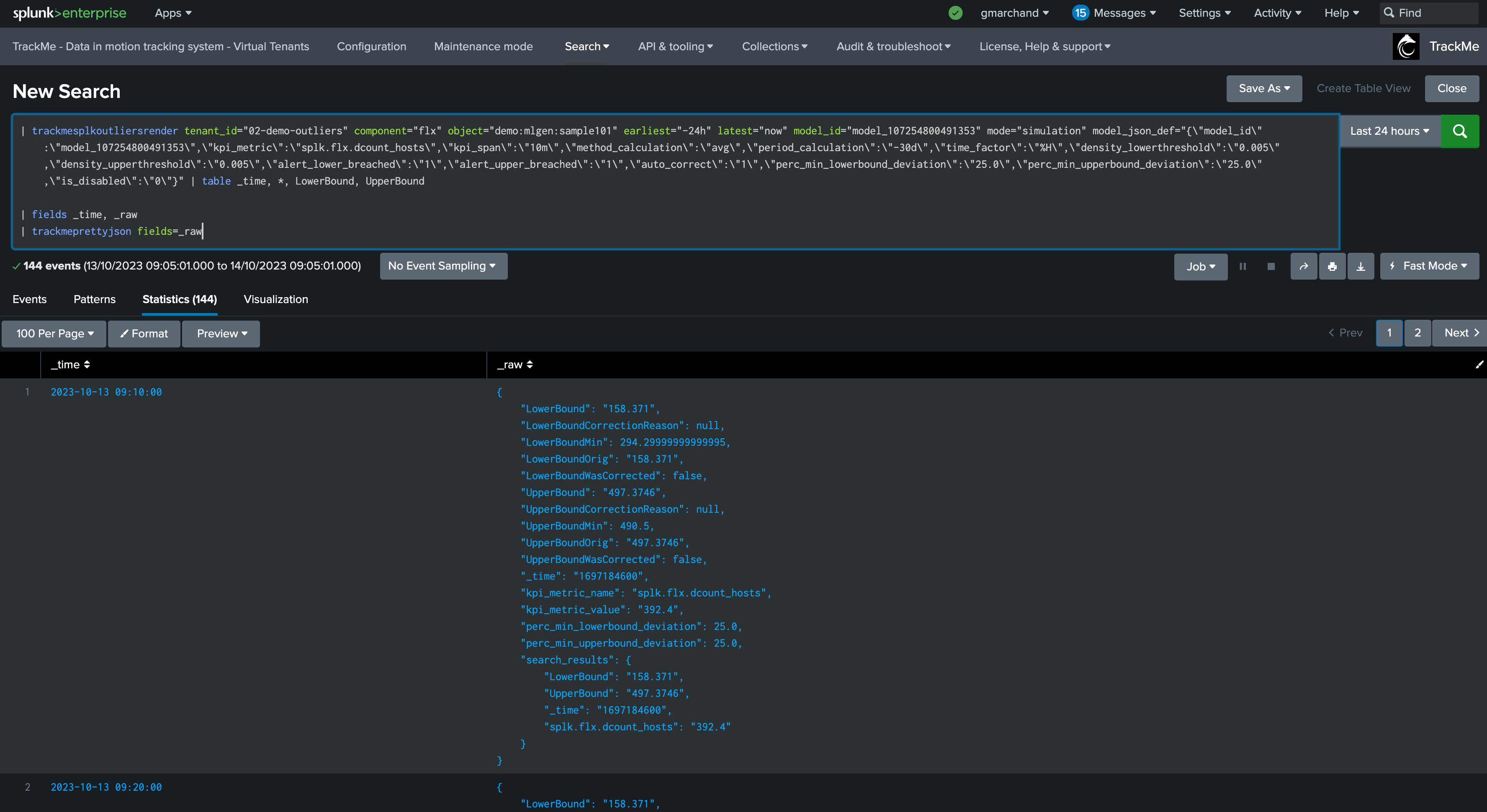
Troubleshooting ML training logs
The first level of the training logic is handled via the command trackmesplkoutlierstrackerhelper. You can access logs via:
index=_internal sourcetype=trackme:custom_commands:trackmesplkoutlierstrackerhelper
notes: this command orchestrates the ML training activity for the tenant and the component. It will then proceed by iteration to the training calling the trackmesplkoutlierstrain command
The per-entity ML training logic is handled via the command trackmesplkoutlierstrain. You can access logs via:
index=_internal sourcetype=trackme:custom_commands:trackmesplkoutlierstrackerhelper
Troubleshooting ML rendering (monitoring) logs
Similarly, the ML monitor phase is orchestrated by the trackmesplkoutlierstrackerhelper command. You can access logs via:
index=_internal sourcetype=trackme:custom_commands:trackmesplkoutlierstrackerhelper
It will then call the command trackmesplkoutliersrender. You can access logs via:
index=_internal sourcetype=trackme:custom_commands:trackmesplkoutliersrender
REST API endpoints for ML in TrackMe
TrackMe exposes different REST API endpoints for the ML Outliers purposes; the same endpoints are used by the UI:
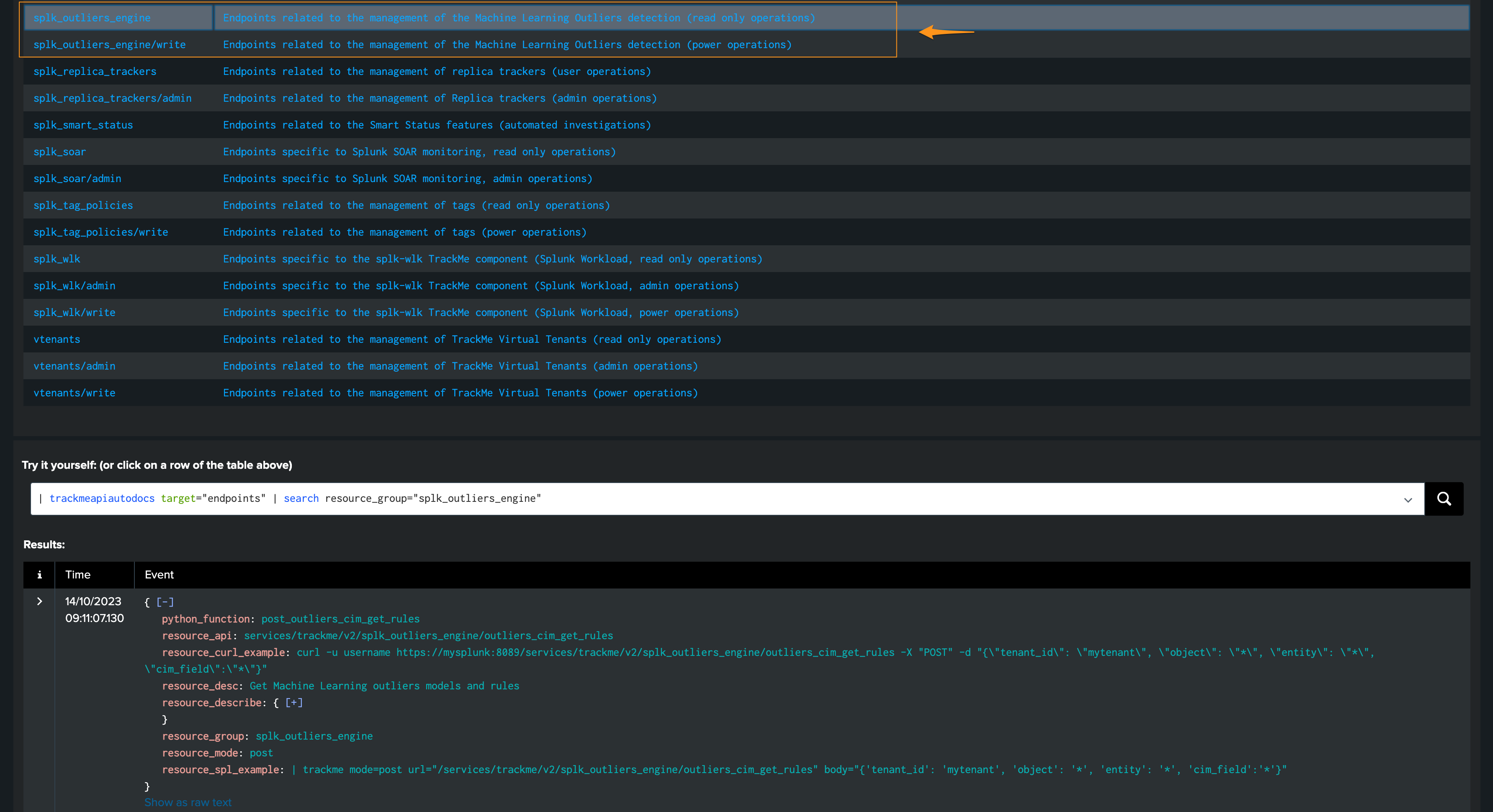
TrackMe provides usage examples with every endpoint, both in cURL and in SPL:
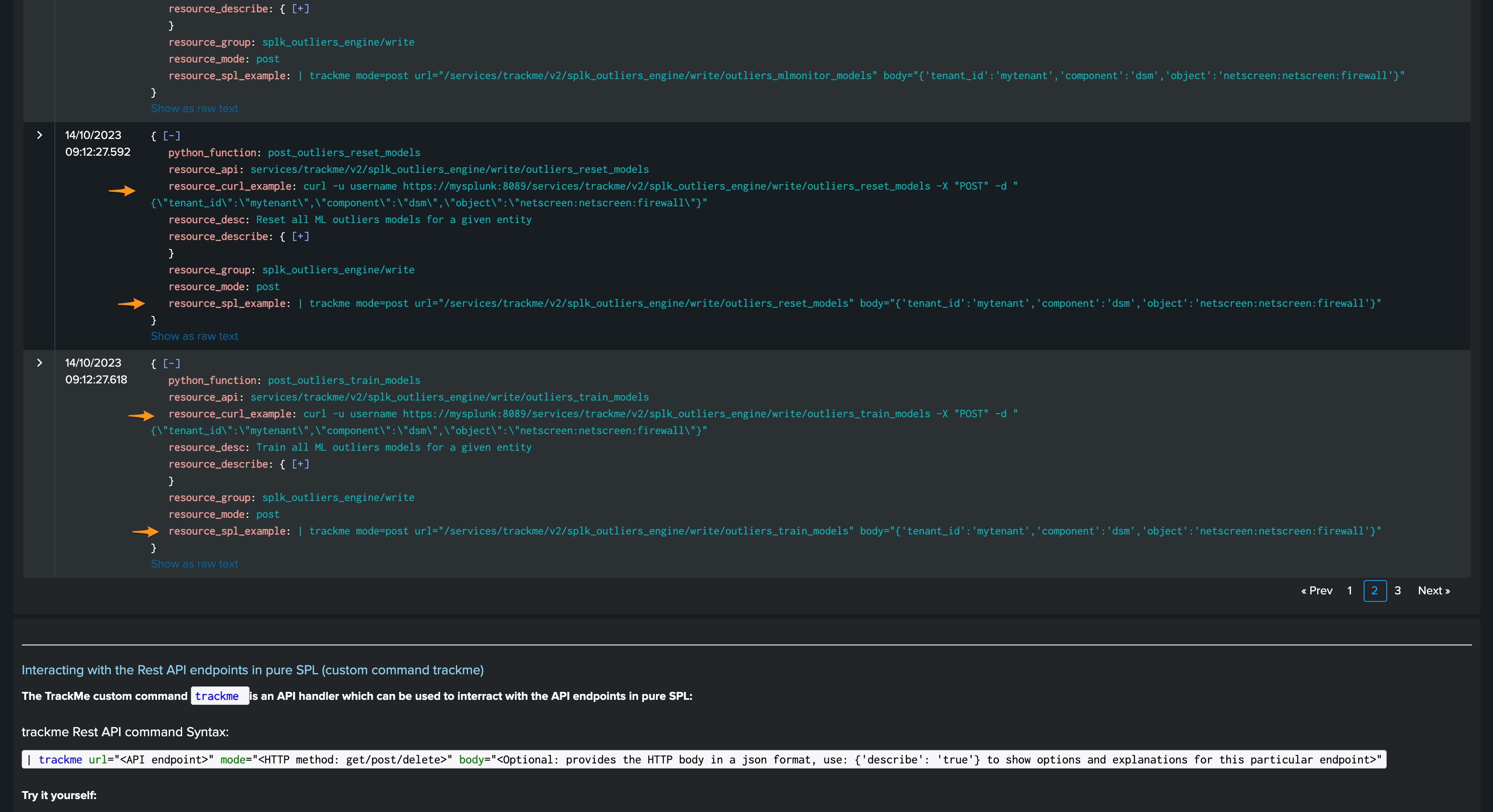
You can, for instance, reset ML models or force training via the REST API:
train:
| trackme mode=post url="/services/trackme/v2/splk_outliers_engine/write/outliers_train_models" body="{'tenant_id':'02-demo-outliers','component':'flx','object':'demo:mlgen:sample101'}"
reset:
| trackme mode=post url="/services/trackme/v2/splk_outliers_engine/write/outliers_reset_models" body="{'tenant_id':'02-demo-outliers','component':'flx','object':'demo:mlgen:sample101'}"
Expanding ML models results and definition
In TrackMe version 2.0.67, we have included a streaming command trackmesplkoutliersexpand which can expand the models results or definition. This can be useful to add more context for custom alerting or reporting.
ML Models are stored in complex dictionaries, and even more when there is more than a single model in a given entity. Accessing the models’ deep information is challenging; the Splunk spath command is designed to handle these use cases properly.
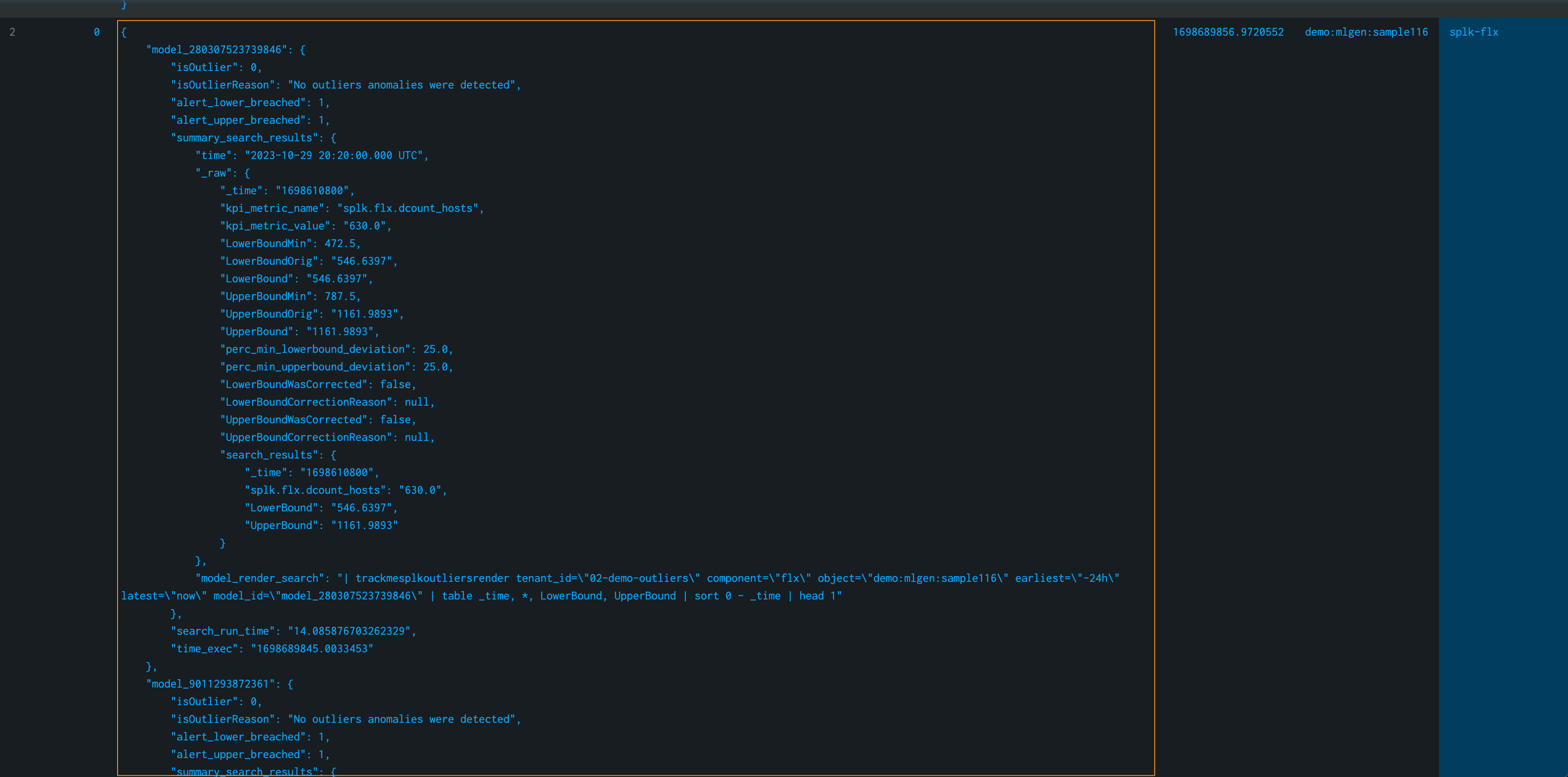
The following example expands results from our Flex tenant 02-demo-outliers:
| inputlookup trackme_flx_outliers_entity_data_tenant_02-demo-outliers
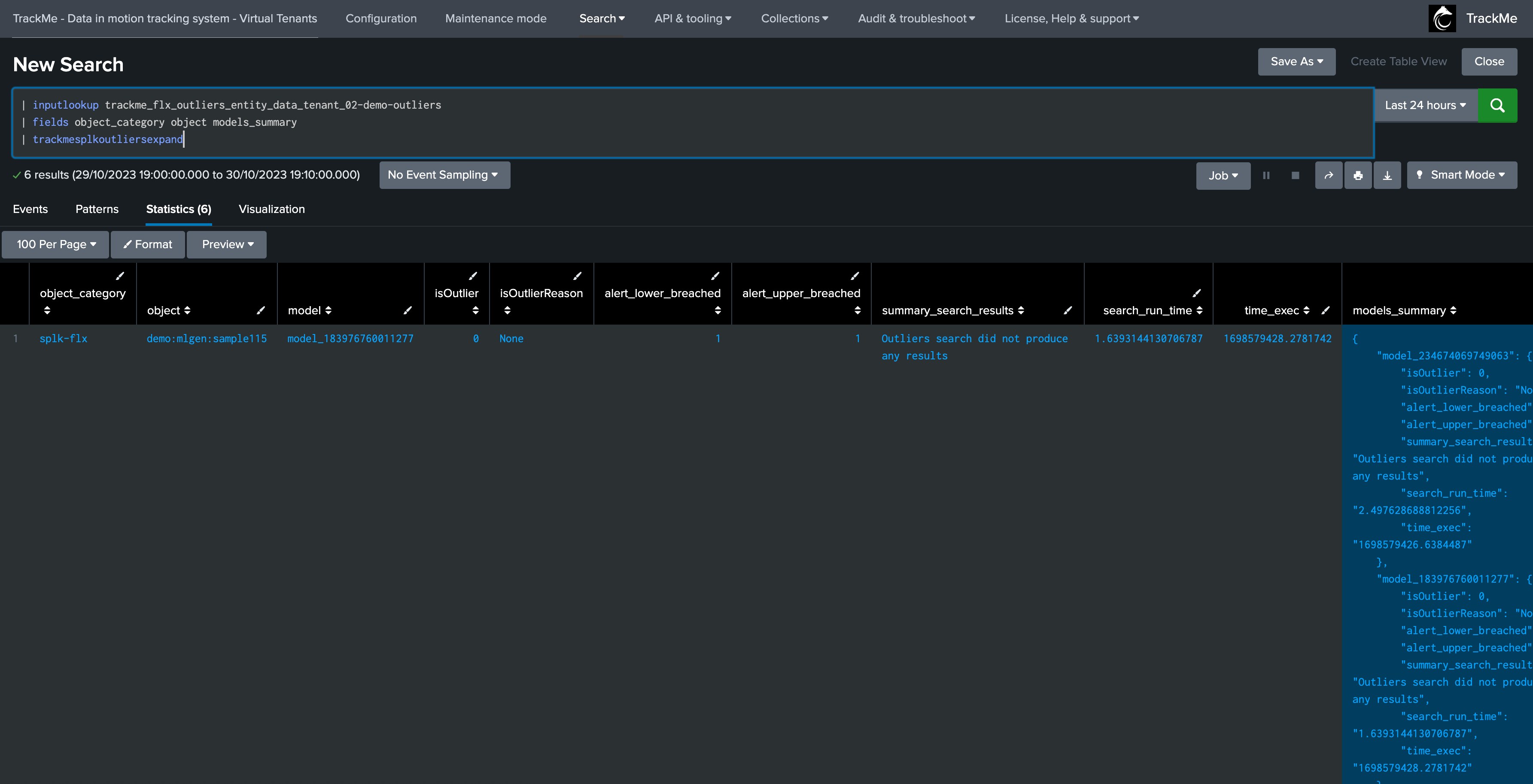
The following command expands the models for each entity; we then get as many rows as we have entities and models, with access to the model details:
| inputlookup trackme_flx_outliers_entity_data_tenant_02-demo-outliers
| fields object_category object models_summary
| trackmesplkoutliersexpand
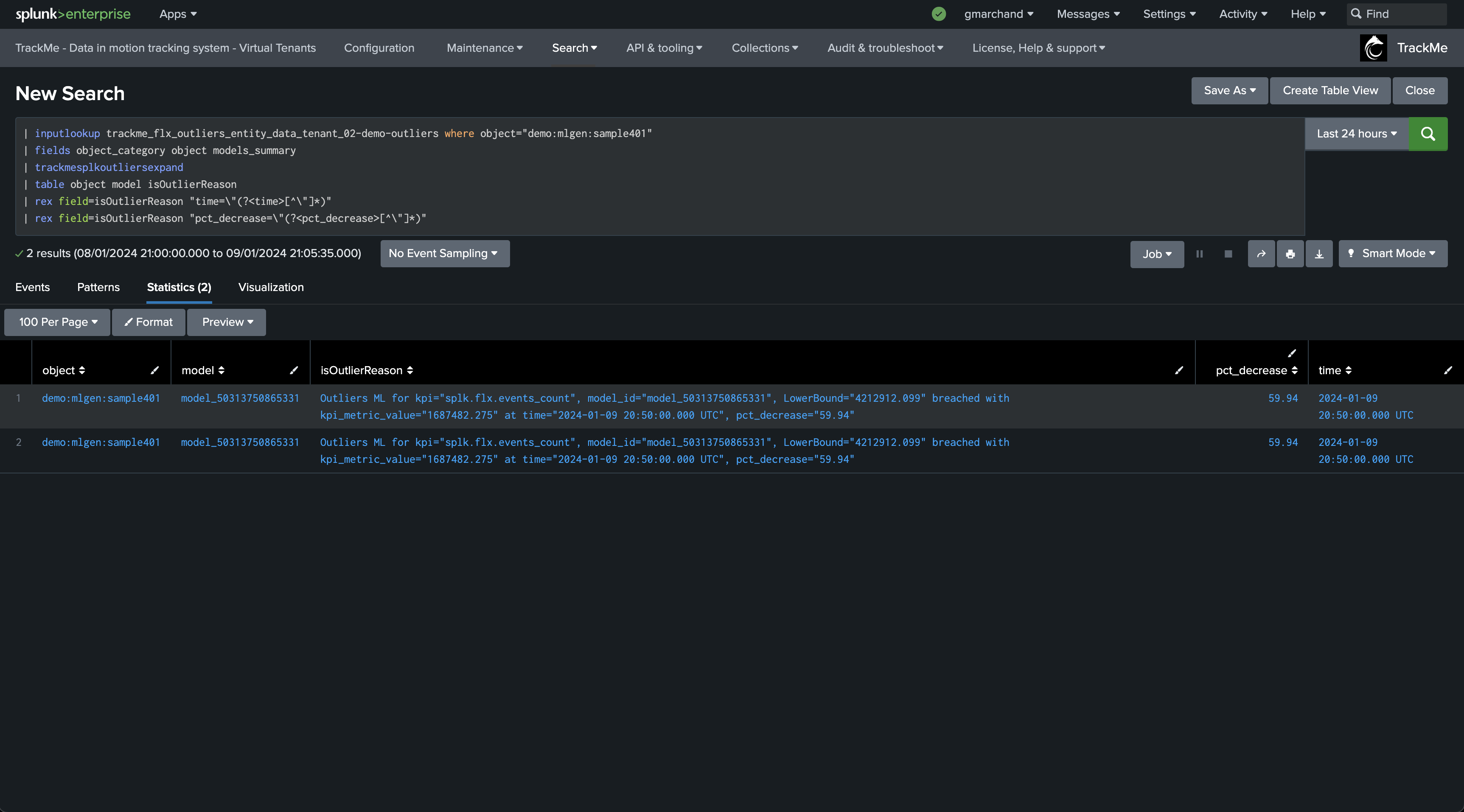
For instance, if you wish to extract the time and percentage of decrease when Outliers are detected:
| inputlookup trackme_flx_outliers_entity_data_tenant_02-demo-outliers where object="demo:mlgen:sample401"
| fields object_category object models_summary
| trackmesplkoutliersexpand
| table object model isOutlierReason
| rex field=isOutlierReason "time=\"(?<time>[^\"]*)"
| rex field=isOutlierReason "pct_decrease=\"(?<pct_decrease>[^\"]*)"
We can also expand the models definition; note the rename:
| inputlookup trackme_flx_outliers_entity_rules_tenant_02-demo-outliers
| fields object_category object entities_outliers
| rename entities_outliers as models_summary
| trackmesplkoutliersexpand
Mass deleting ML models
Say we want to mass delete ML models based on a certain criterion like the KPI; we can use the Splunk map command in addition with TrackMe REST API endpoints.
The following example deletes models associated with the latency KPI:
| inputlookup trackme_dsm_outliers_entity_rules_tenant_02-demo-outliers
| table object_category, object, entities_outliers
| rename entities_outliers as models_summary
| trackmesplkoutliersexpand
| where kpi_metric="splk.feeds.avg_eventcount_5m"
| eval tenant_id="02-demo-outliers"
| table tenant_id, object_category, object, model
| map maxsearches=100 search="| trackme mode=post url=/services/trackme/v2/splk_outliers_engine/write/outliers_delete_models body=\"{'tenant_id': '$tenant_id$', 'component': 'dsm', 'object': '$object$', 'models_list': '$model$'}\""