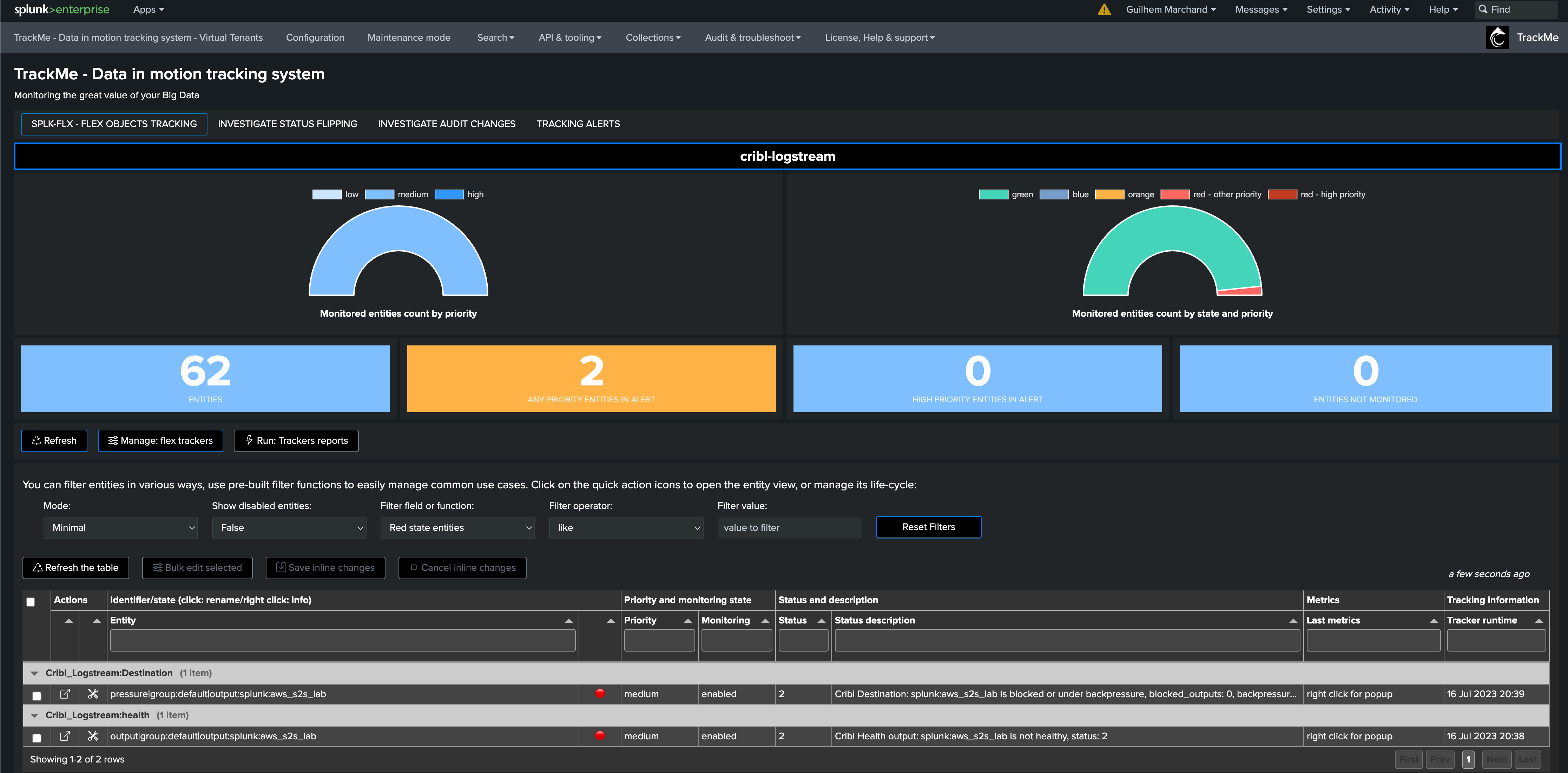
splk-flx - Creating and managing Flex Trackers
Introduction to Flex Trackers
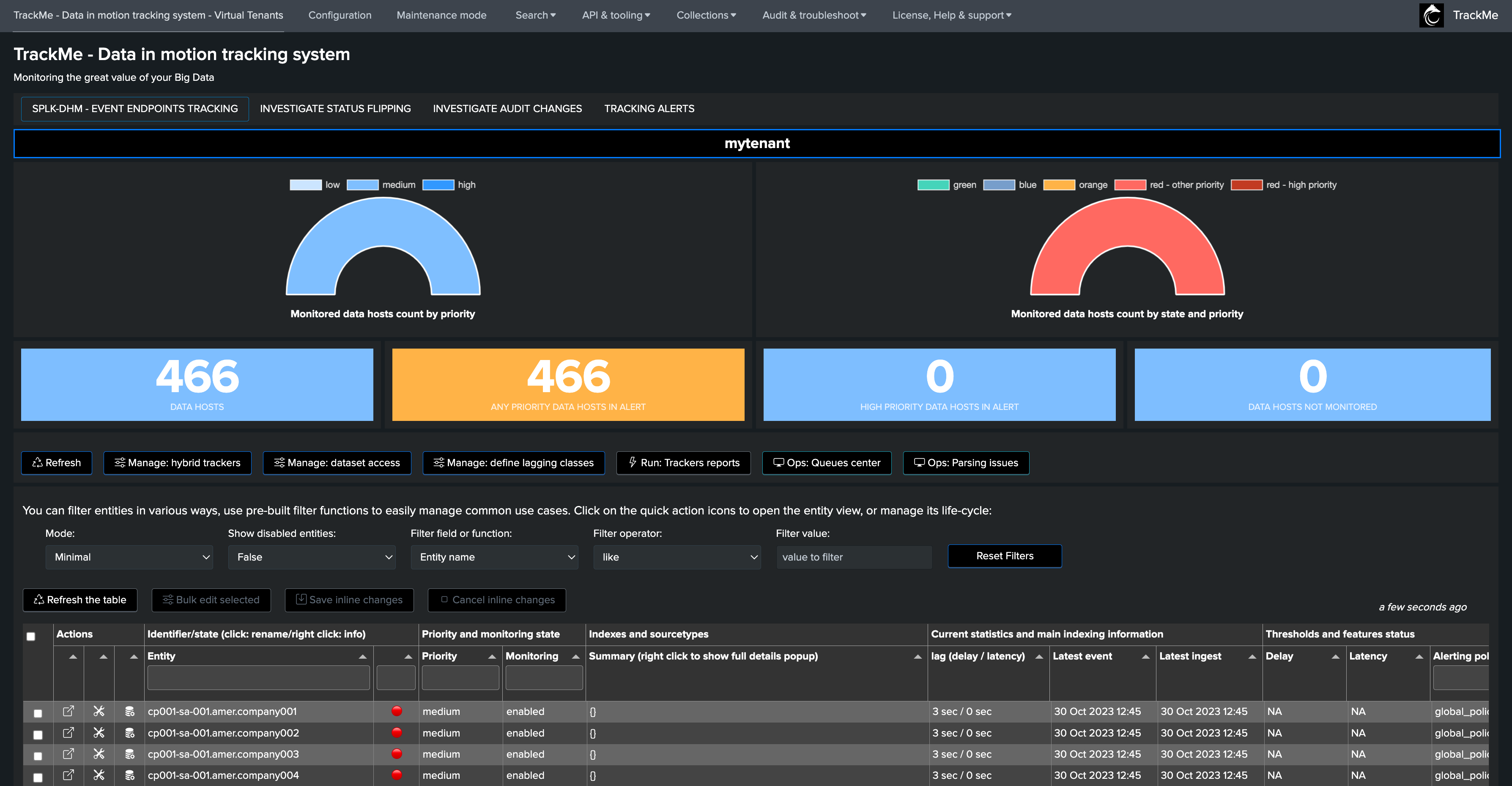
Flex Trackers are created and managed through TrackMe. These are scheduled backend jobs that orchestrate entity discovery and management for the TrackMe splk-flx component:
The splk-flx component stands for Splunk Flex Objects tracking
This component allows tracking any kind of results from a Splunk search, to manage the resulting entities into TrackMe’s unique workflow
A Flex tracker can, for example, monitor modular input statuses on remote Heavy Forwarders, monitor Data Model Acceleration, or your IoT devices - this can be anything adapted to your context
The Flex component expects a certain convention allowing identification of entities and their status. You can automatically define which Key Performance Metrics should be part of it and even define default Machine Learning models for Outliers detection
A single Tracker can discover and manage a few, or many entities according to the needs
When creating a tracker, the related knowledge objects will be owned by the owner defined at the Virtual Tenant level
TrackMe keeps records of the knowledge objects related to the Trackers; therefore, you need to manage its lifecycle through TrackMe
Hint
Flex Objects Library
The Flex Objects component comes with a use case library of dozens of pre-built searches for Splunk Cloud, Splunk Enterprise, Splunk SOAR and even for third party product such as Cribl Logstream
The use cases in the library can easily be loaded when creating a new Flex tracker
See: Splunk SOAR Cloud & on-premise monitoring and active actions in TrackMe
Flex Object use cases Library & Tracker creation
You can access the use cases Library through the Hybrid tracker creation wizard:
The user interface also provides a direct link to the TrackMe use cases library provider custom command:
| trackmesplkflxgetuc
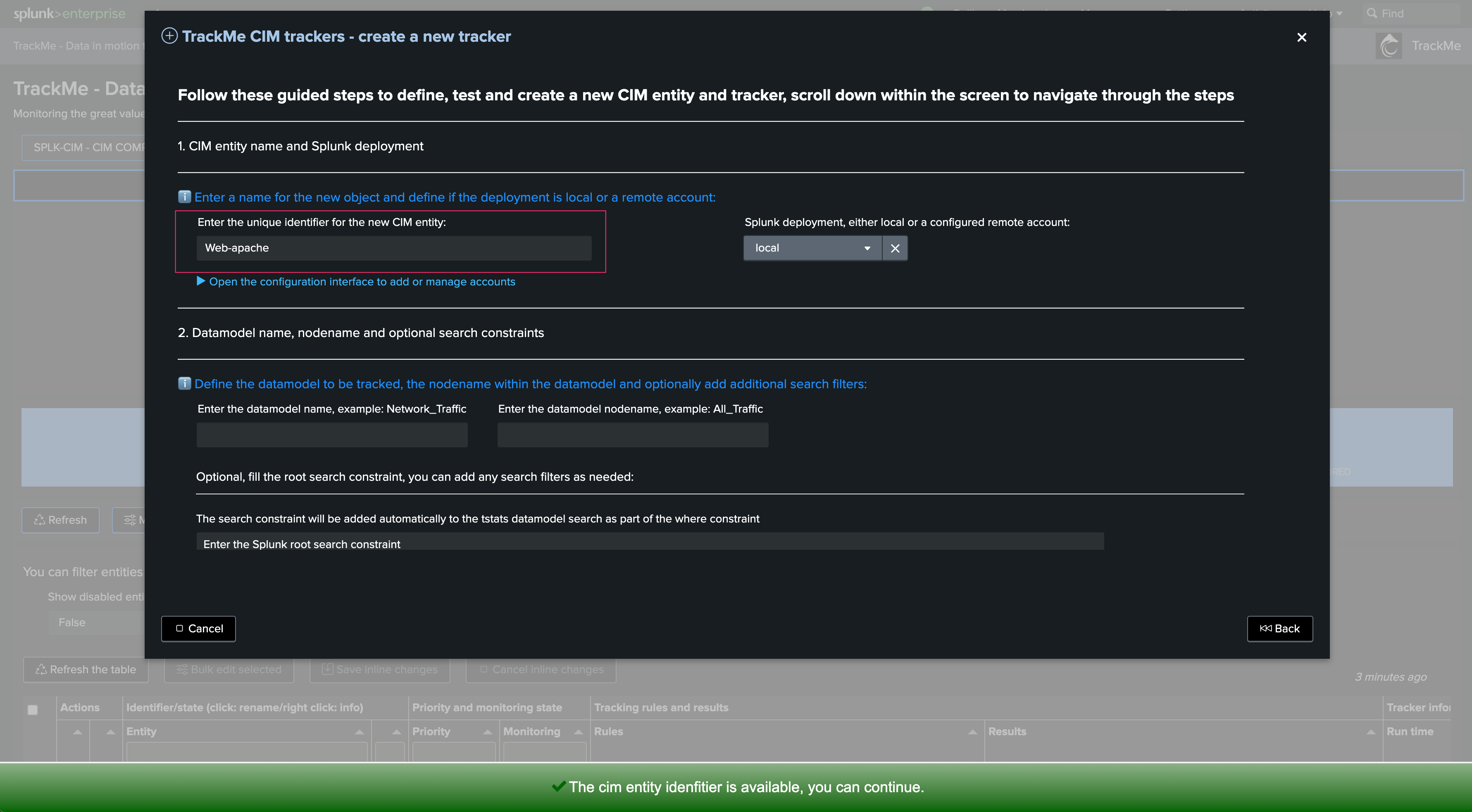
The Flex wizard opens. Start by defining the tracker identifier:
Note: This step is important as this identifier is used to categorize and group the entities in the user interface. Make sure to use any form of convention that makes sense for you:
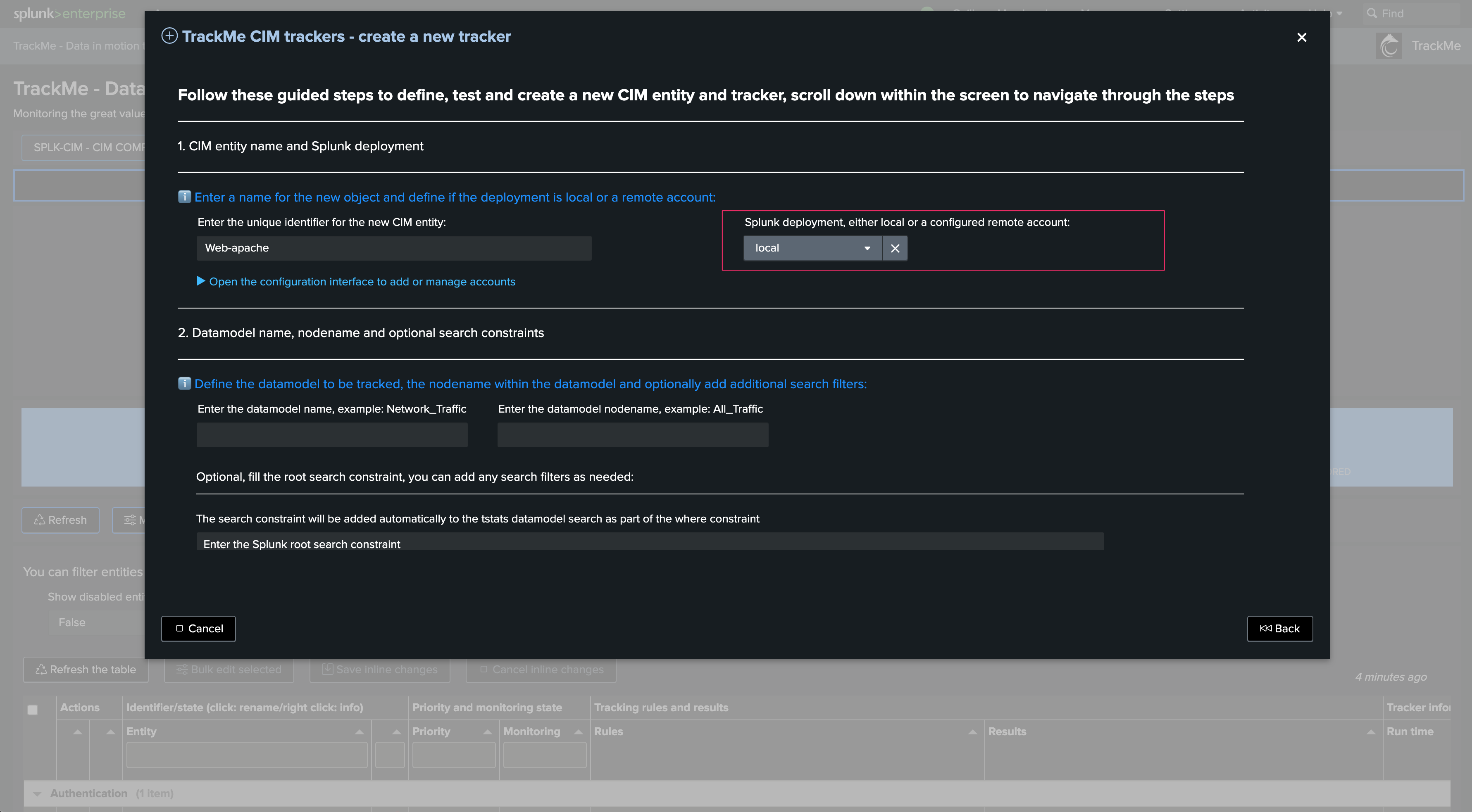
Choose the environment target, if the target is remote, a connectivity check is immediately performed:
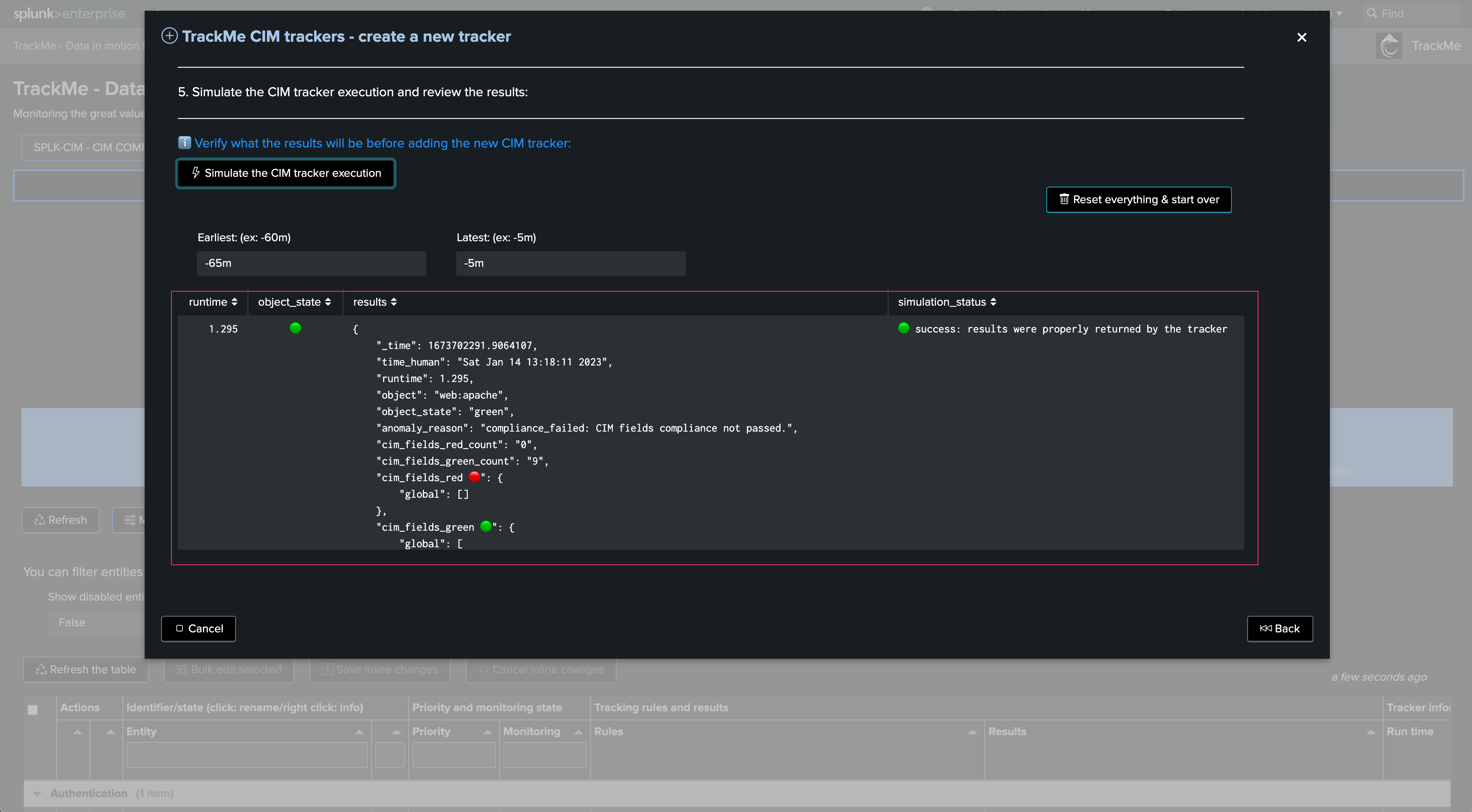
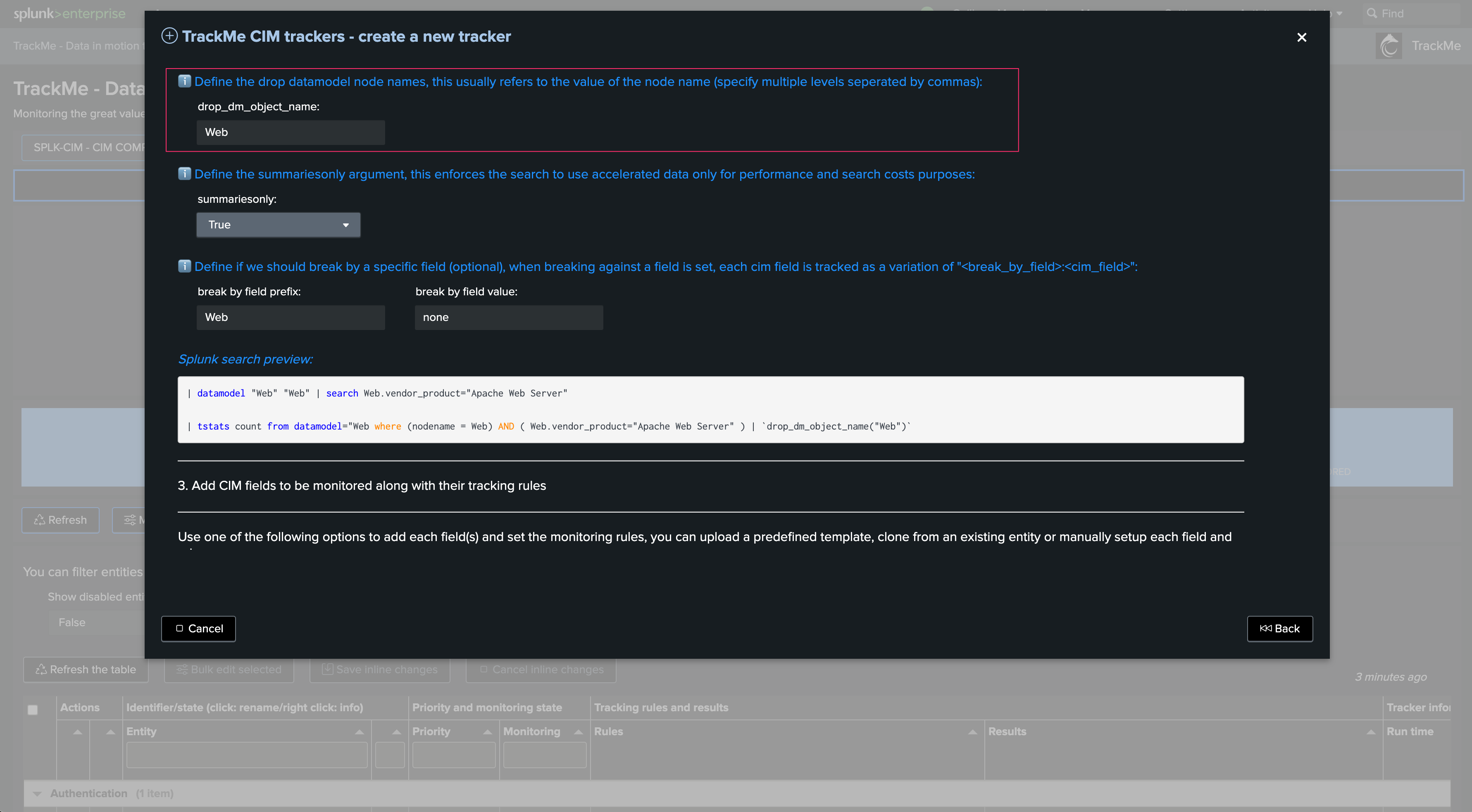
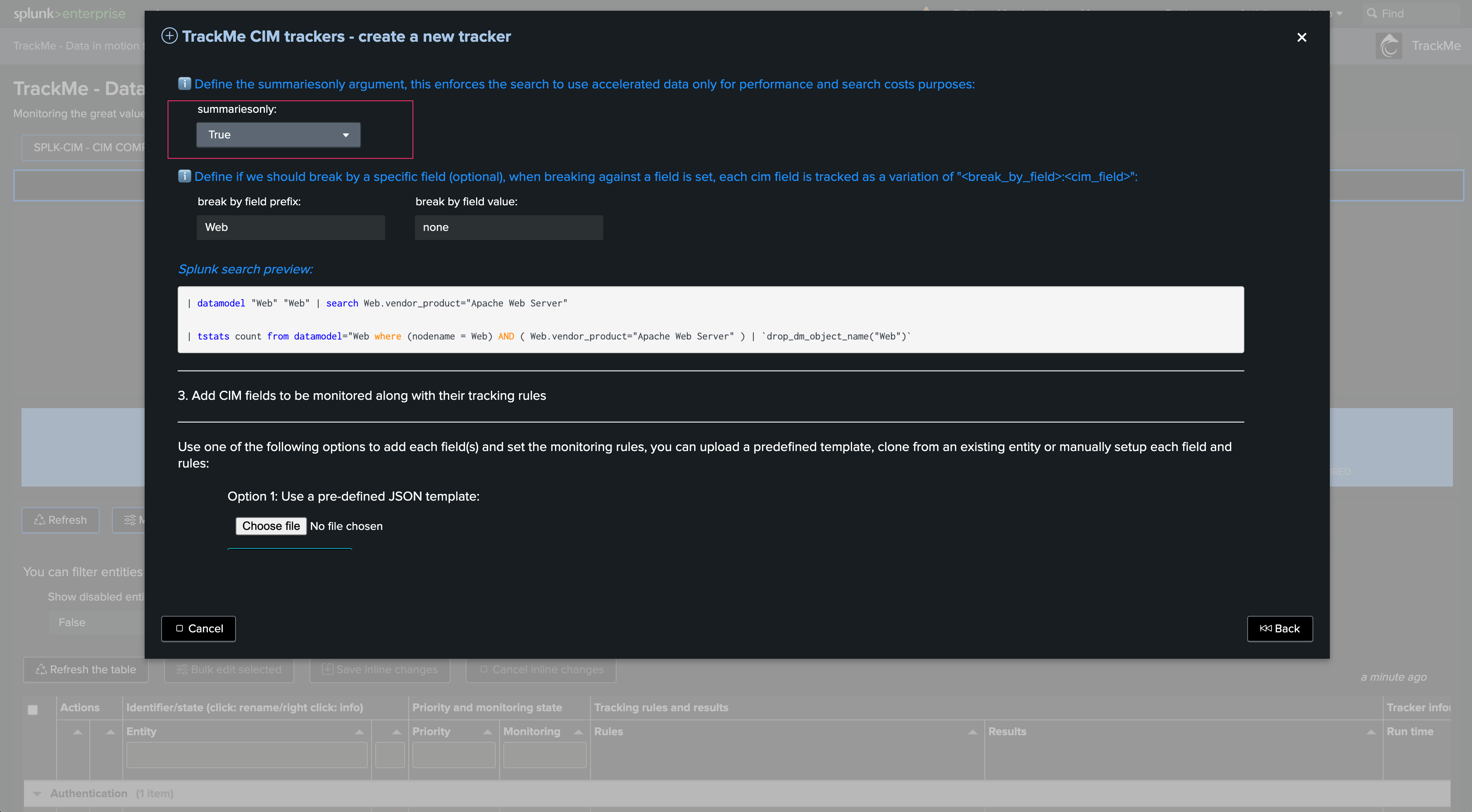
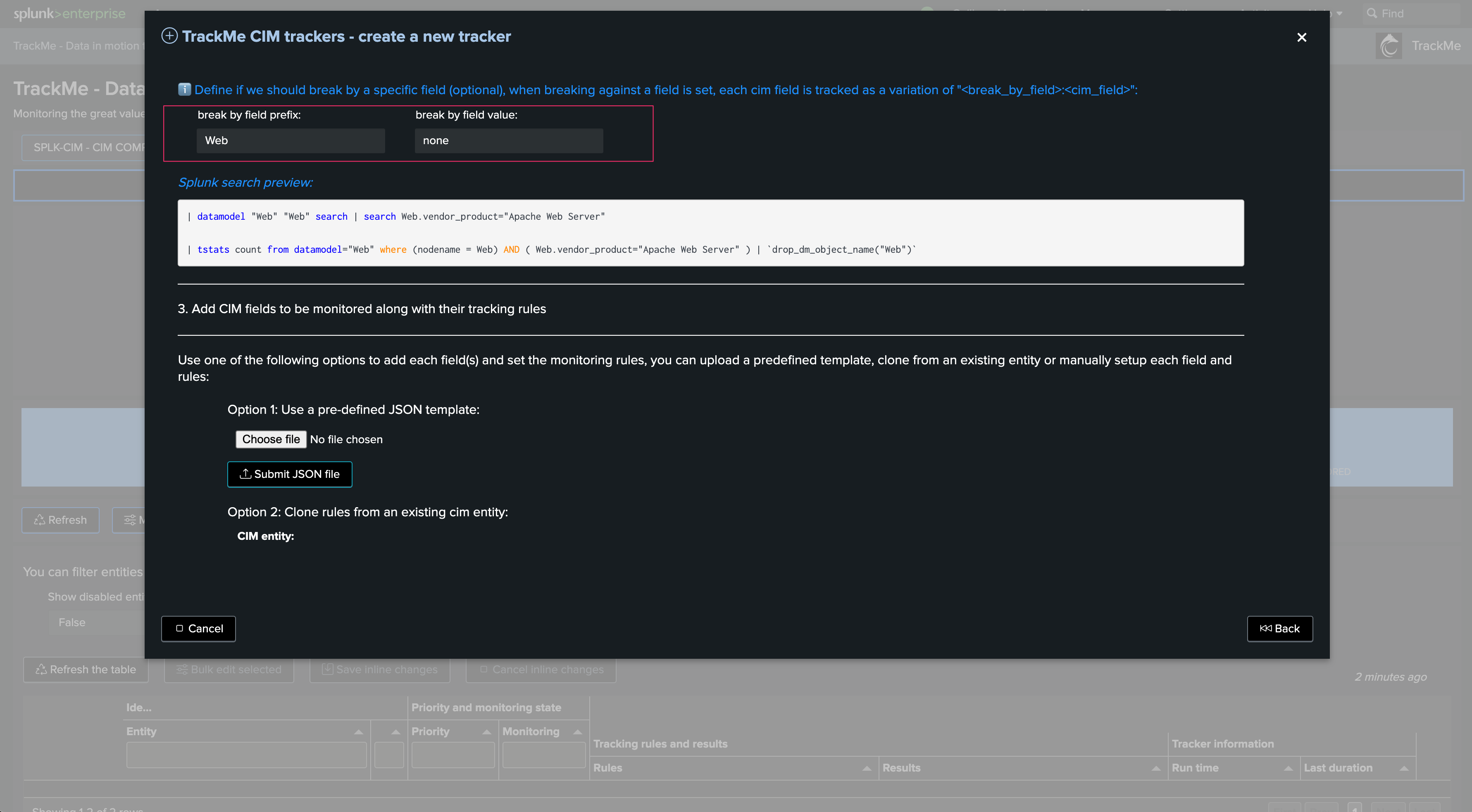
Define the search logic. The wizard shows the fields convention as well as their detailed usage, and several examples:
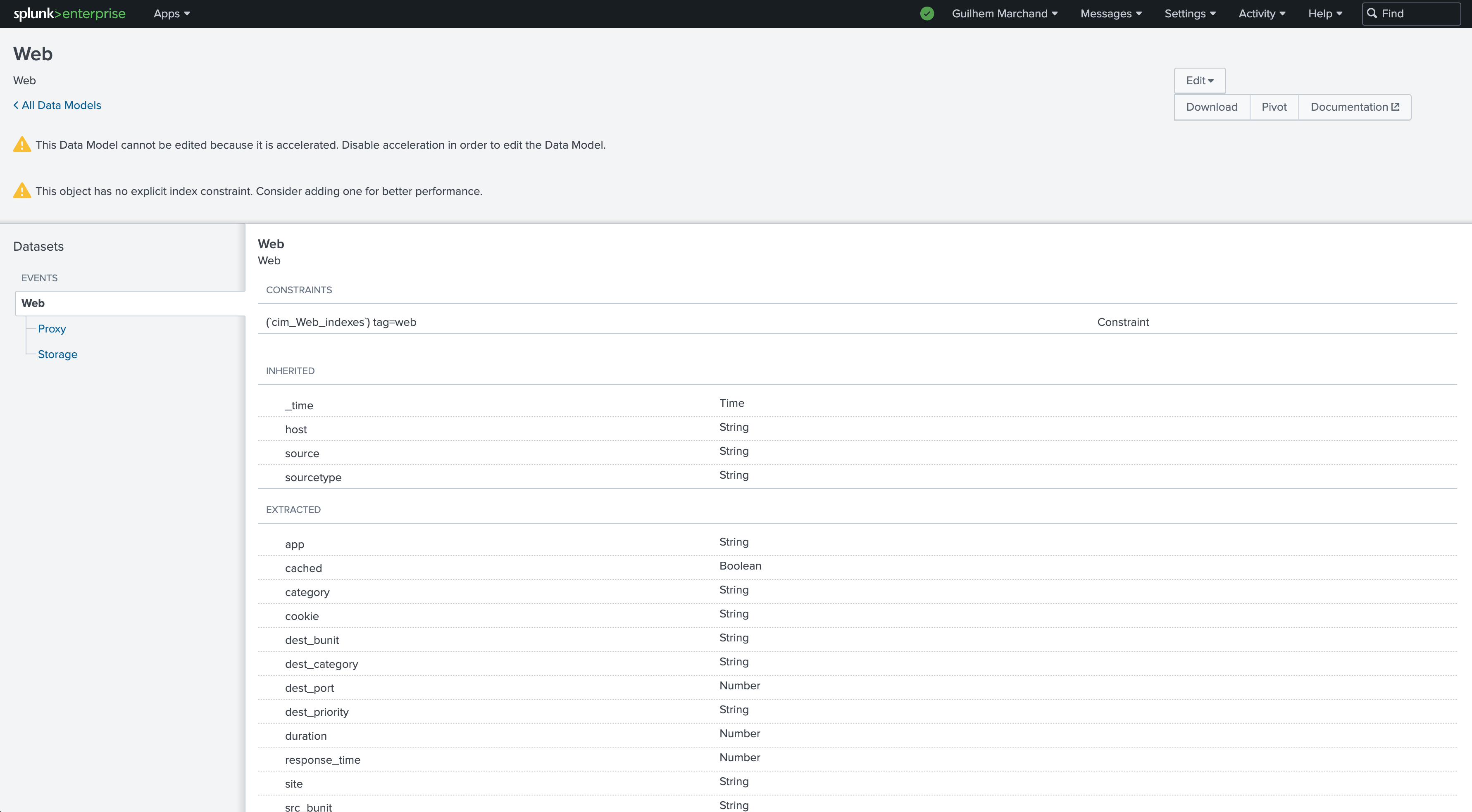
The following example tracks modular input statuses for the Splunk Okta Add-on on a remote Heavy Forwarder:
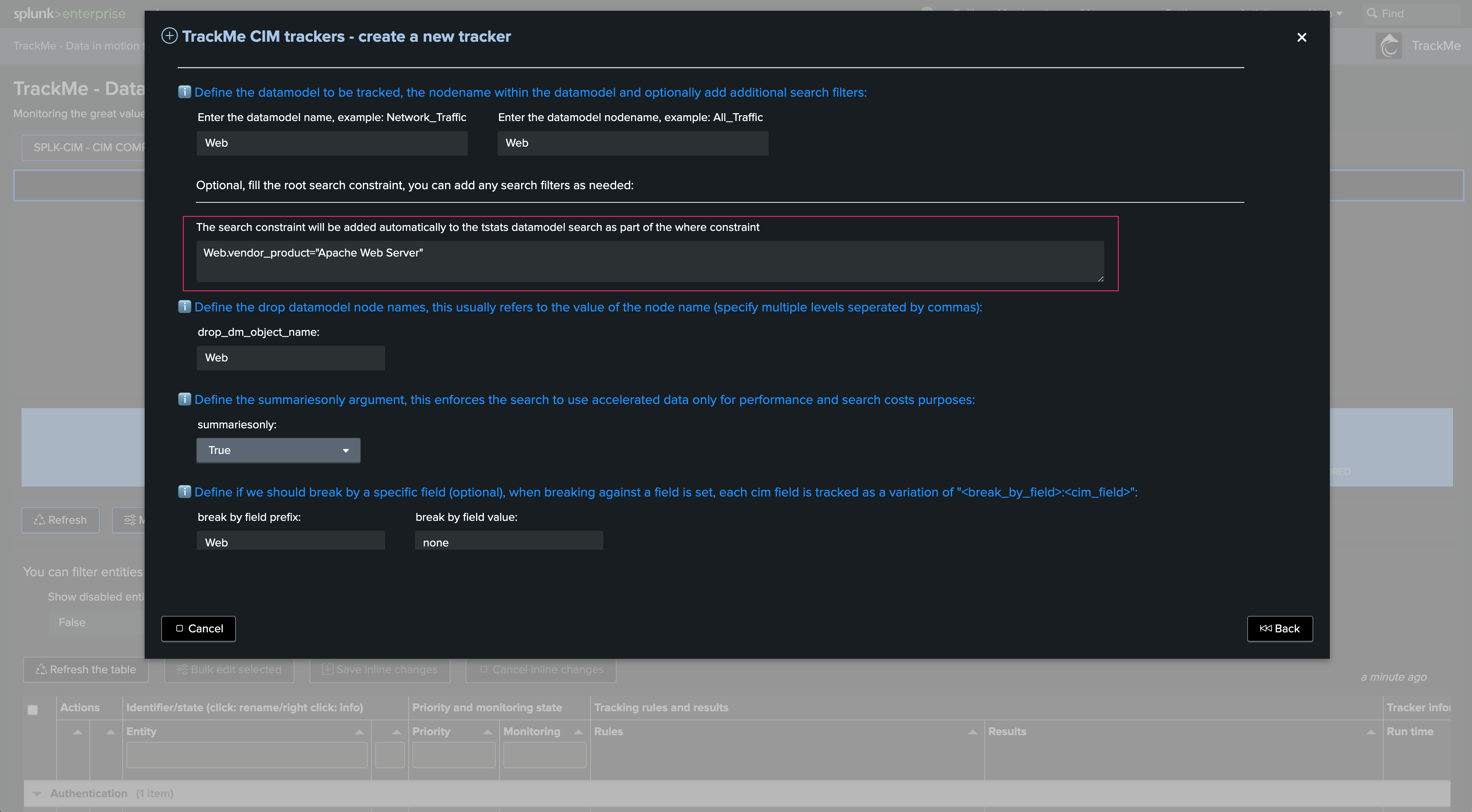
Another more advanced example that tracks Data Model Acceleration status on a remote Search Head:
Define the cron schedule. If the use case deals with REST-related searches, the time quantifiers generally do not matter:
Test and review, for instance, with the Okta modular input tracking:
Test and review with the Data Model example. As we specify metrics and outliers metrics, we can observe additional information:
Open in search if you wish to review manually the results in the Splunk Search UI:
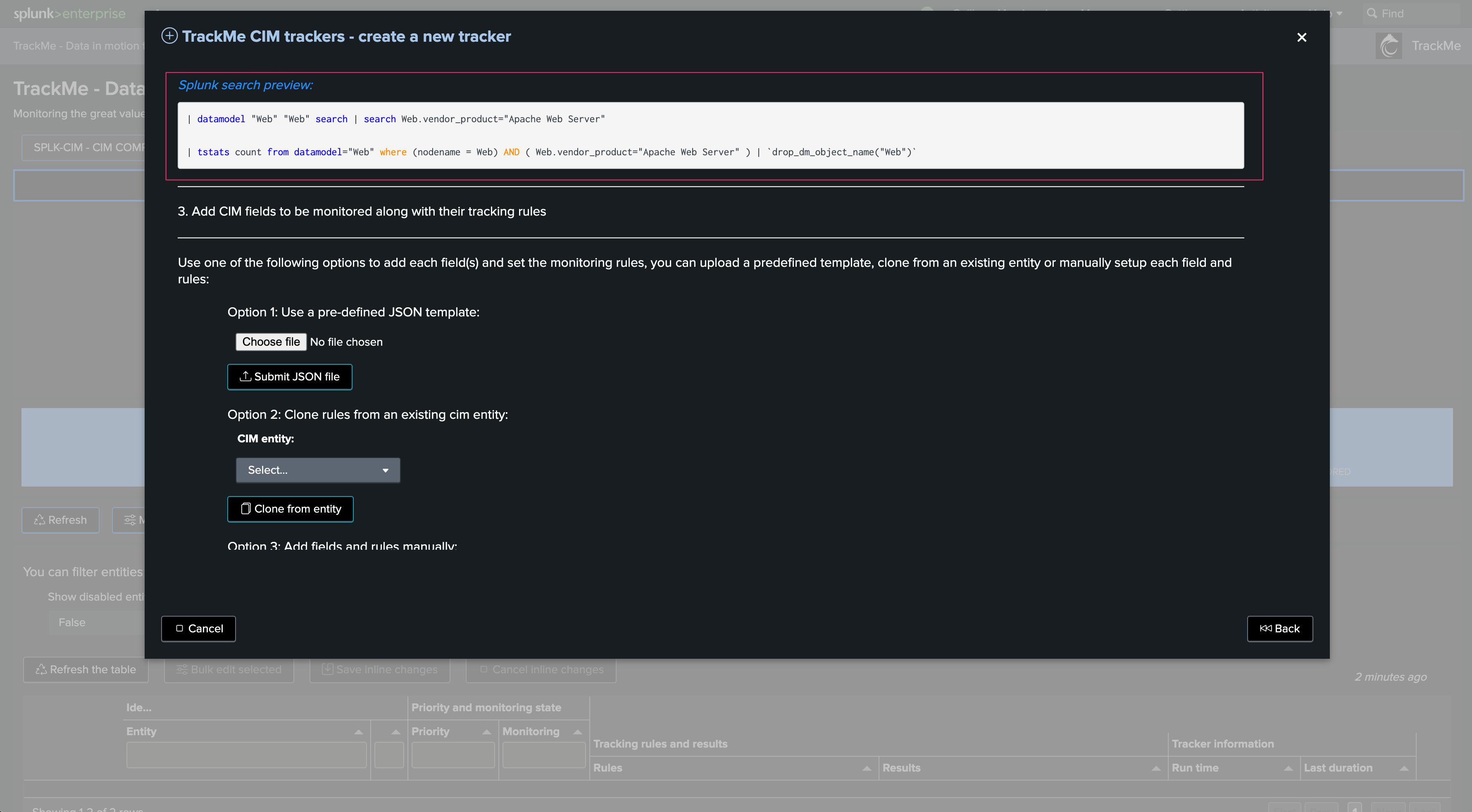
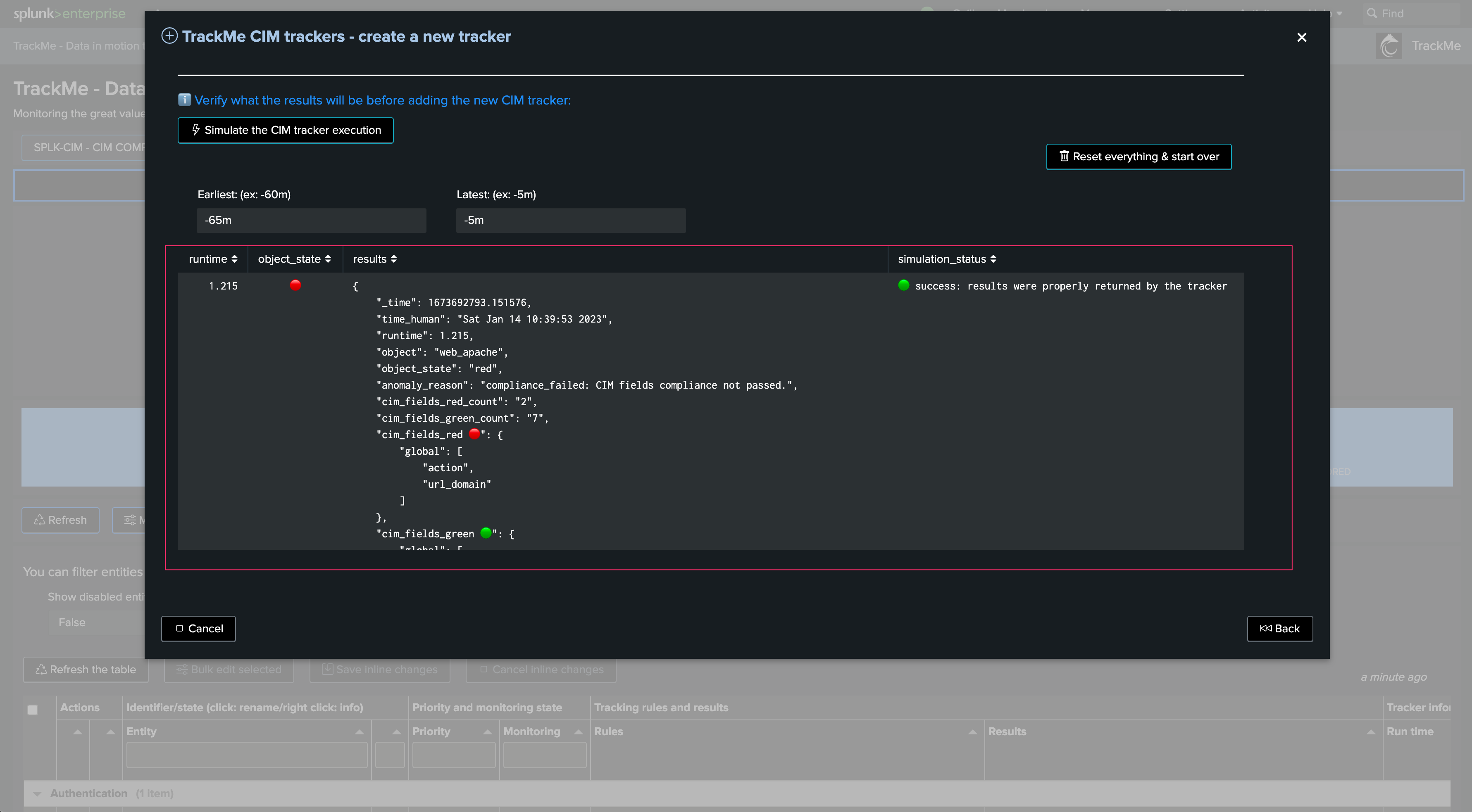
Once you are happy with the results, you can proceed to the tracker creation:
After the tracker creation, you can execute it now:
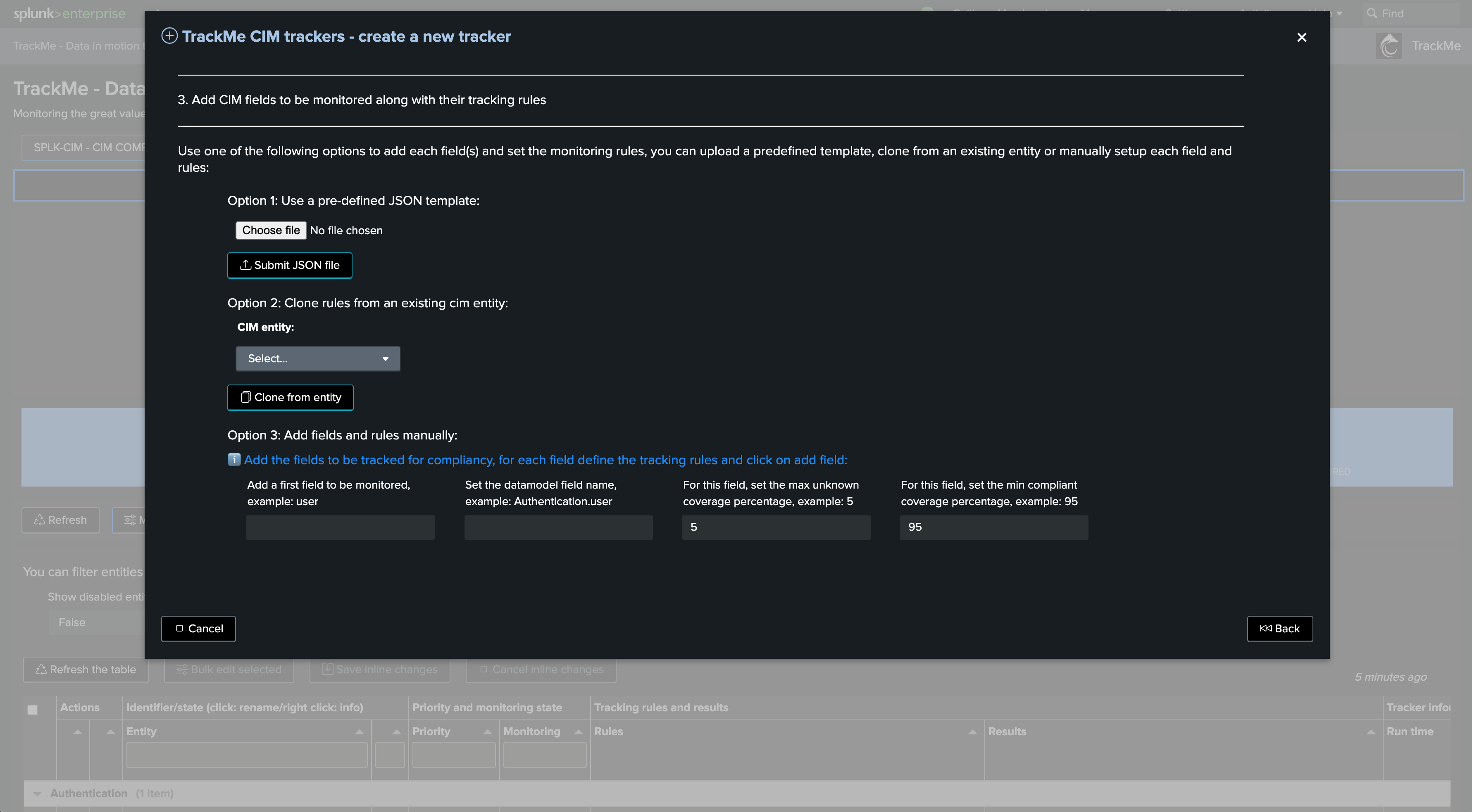
Managing Flex Trackers
Deleting a Flex Tracker through the UI
If you want to delete an existing Flex Tracker, this operation must be done via TrackMe.
The reason is that the application keeps track of all knowledge objects that were created for a given tenant to honor various features such as managing the lifecycle of the tenant (enabling/disabling, etc.) or the lifecycle of the tracker itself.
To manage Flex Trackers, click on:
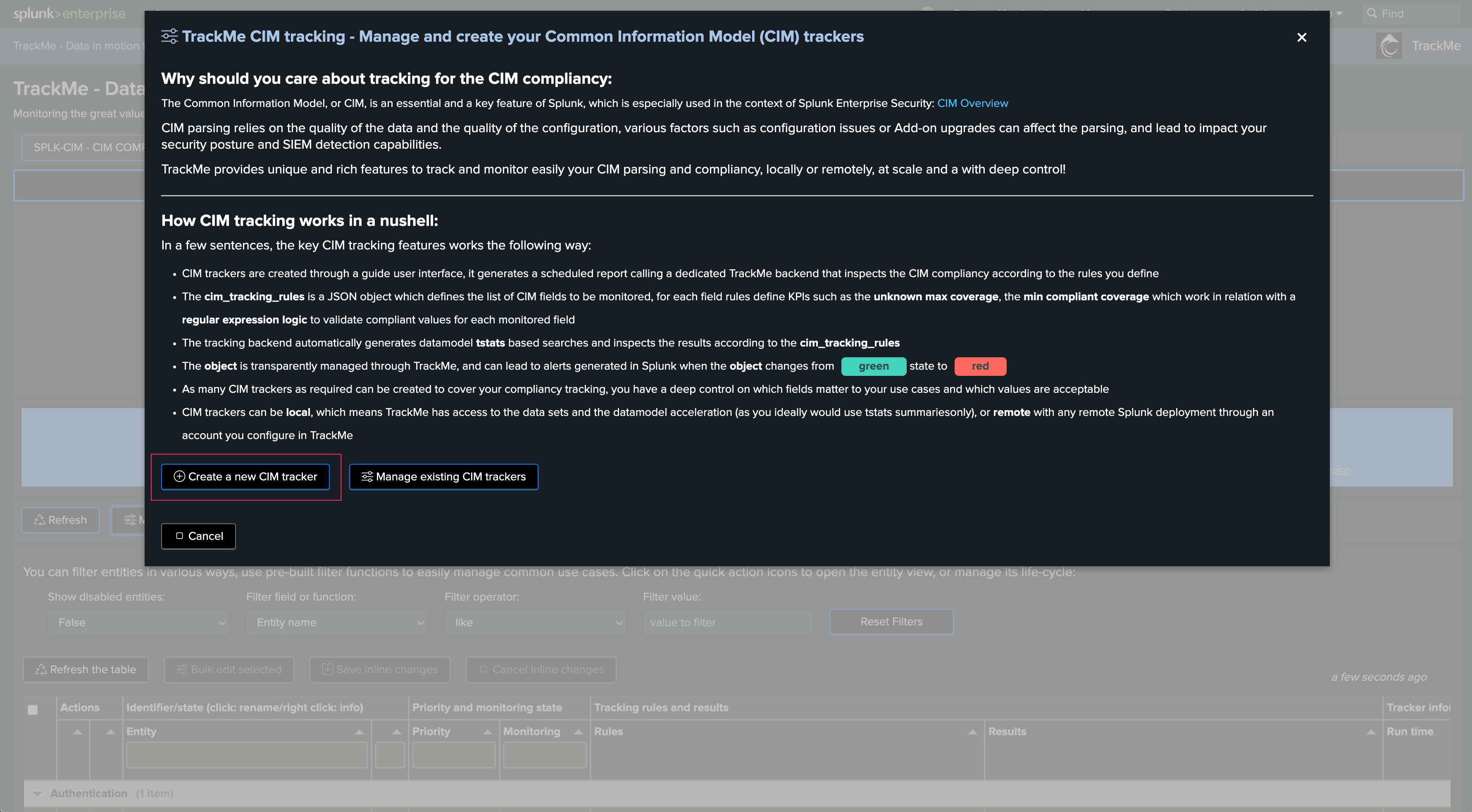
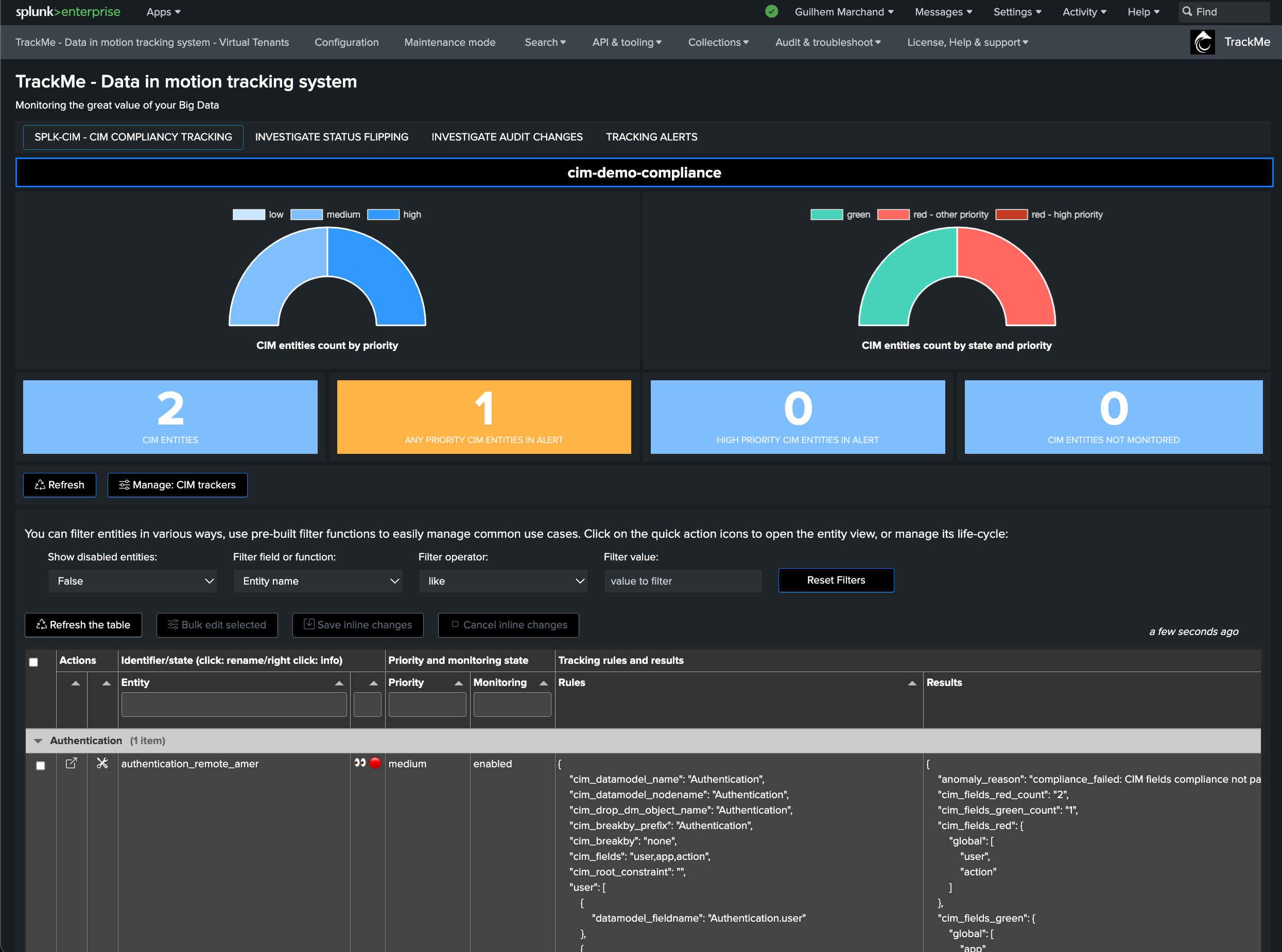
The user interface shows available trackers and their related objects:
Select one or more trackers to be deleted and proceed. TrackMe will call the related REST endpoint, knowledge objects will be purged, and TrackMe will also clean up the Virtual Tenant records.
TrackMe will not automatically purge the entities that were discovered and maintained when the originating tracker is deleted; however, these won’t be maintained anymore.
Deleting a Flex Tracker through REST
You can delete a Tracker through the following REST endpoint, example in SPL:
| trackme mode=post url="/services/trackme/v2/splk_flx/admin/flx_tracker_delete" body="{'tenant_id': 'mytenant', 'hybrid_trackers_list': 'Okta:prod'}"
Key Performance Indicators in Flex Trackers
When creating a Flex tracker, you can leverage any Key Performance Indicator resulting from the Flex search to generate metrics automatically through TrackMe.
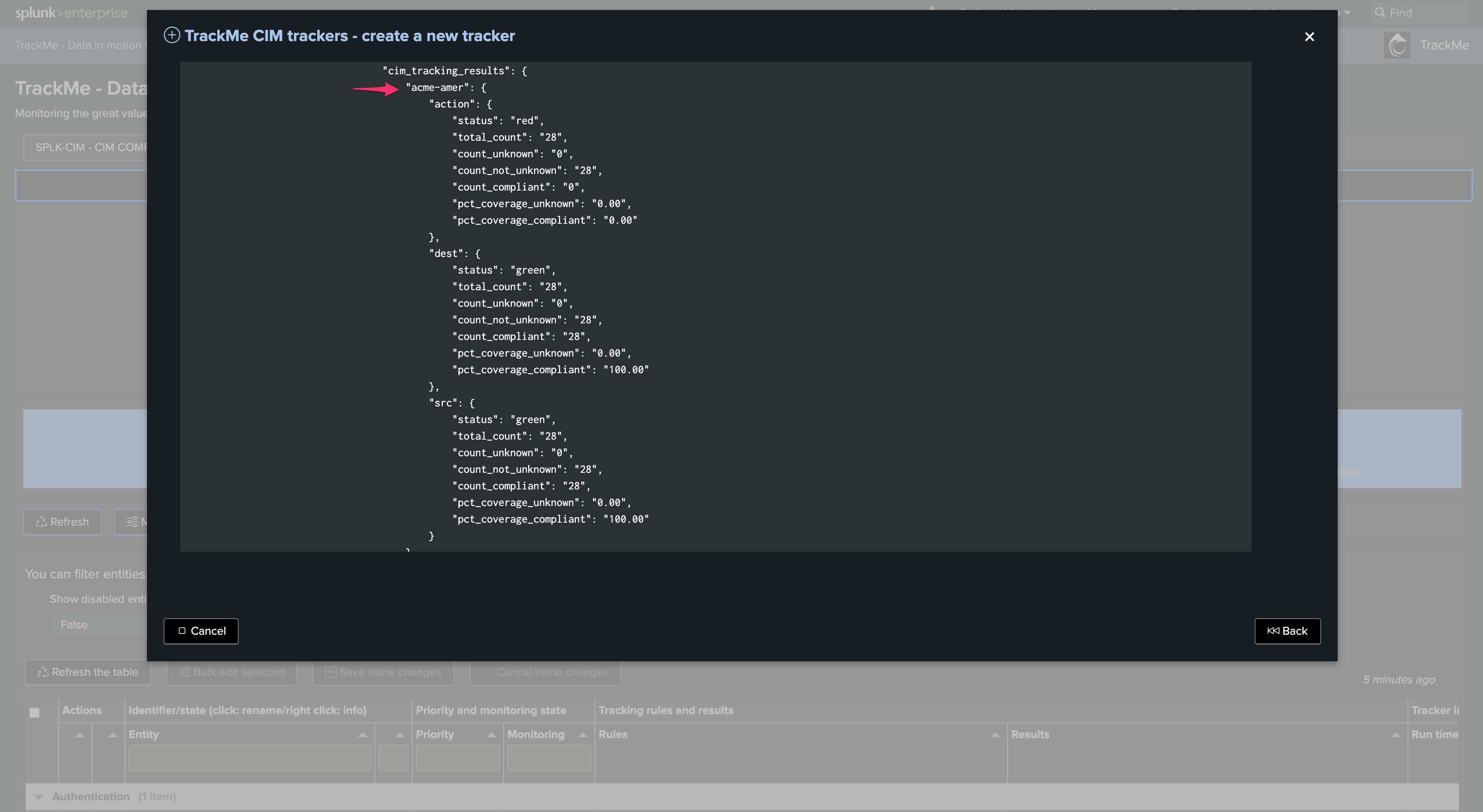
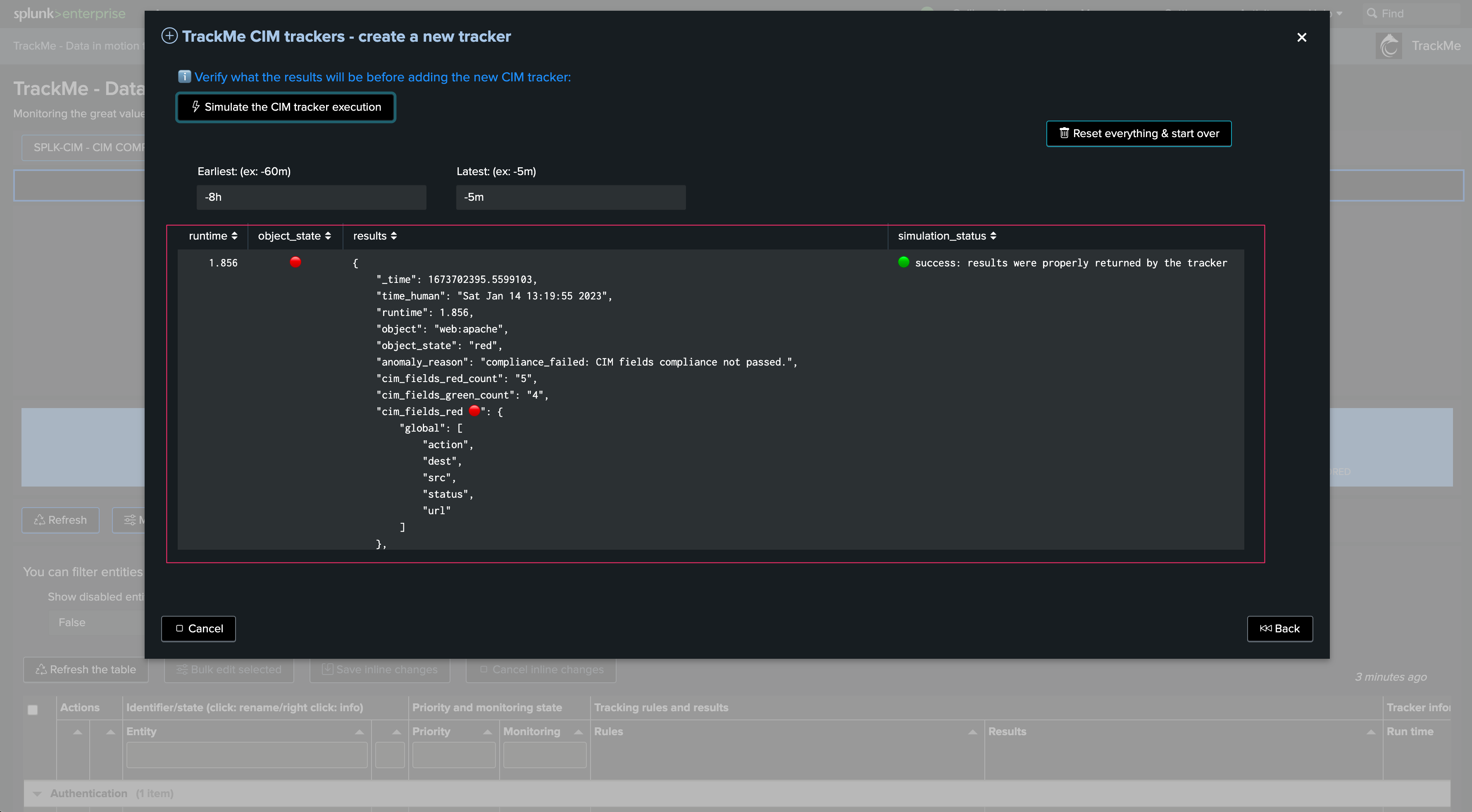
The following example tracks Data Model Acceleration (DMA) completeness and metrics. In short, the logic is the following:
TrackMe orchestrates and executes a Splunk REST search which returns various information per entity (in this case, a given Common Information Model)
The information is interpreted by TrackMe as Key Performance Indicators, leading to the generation and ingestion of metrics in the Splunk metric store
Optionally, these Key Performance Indicators are automatically handled via the Machine Learning Outliers detection engine. ML models will be generated and maintained automatically for these KPIs
Generating Key Performance Indicators, and therefore metrics, is optional. In some cases, this may not be relevant and is totally expected (such as monitoring statuses of modular inputs)
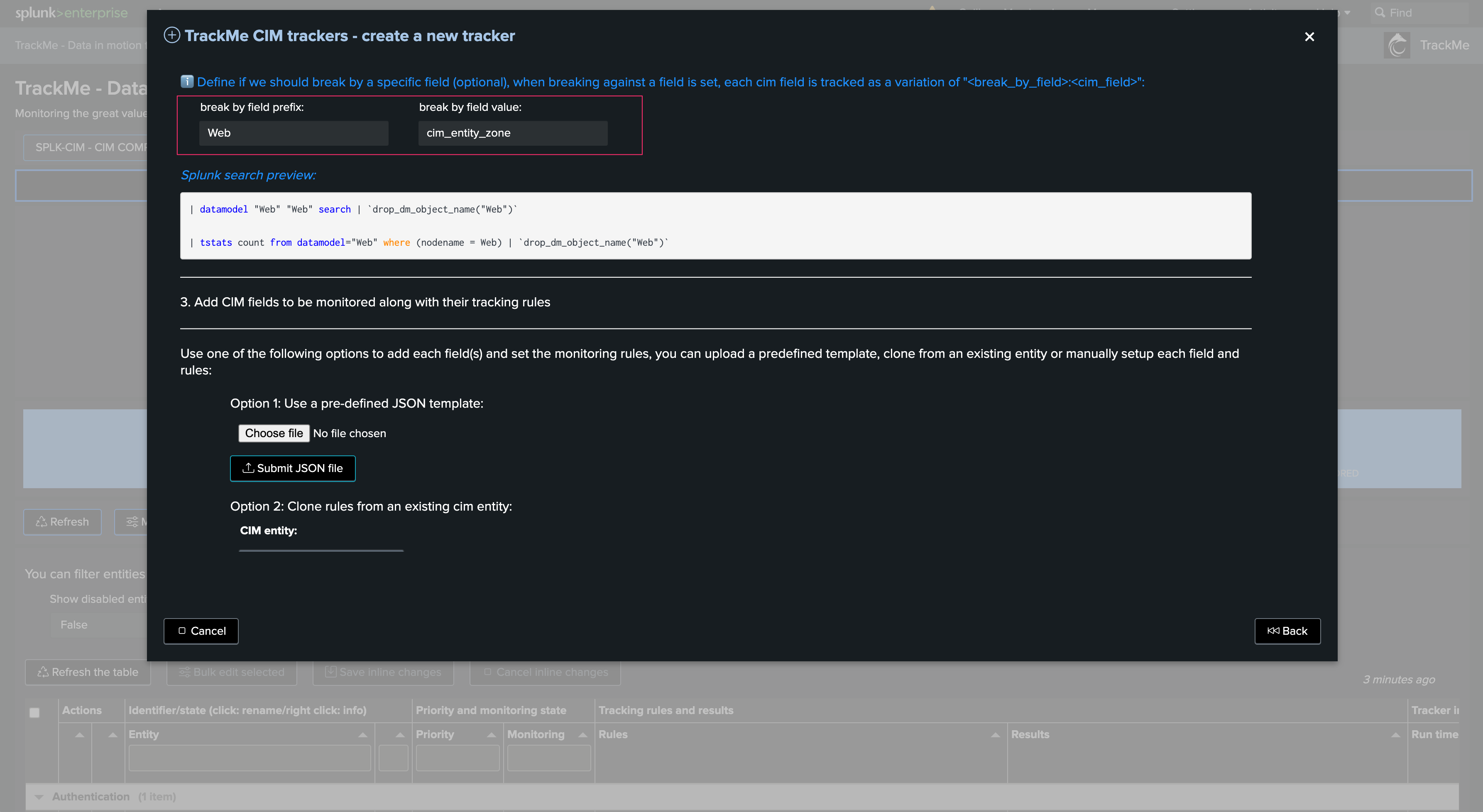
Example: When defining the DMA tracker, we enable various KPIs resulting from the Flex search:
To achieve this, all we need is to generate metrics from our resulting SPL query as a JSON object:
| eval metrics = "{'dma.complete_pct': " . complete_pct . ", 'dma.size_mb': " . size_mb . ", 'dma.runduration_sec': " . round(runDuration, 2) . ", 'dma.buckets_count': " . buckets . "}"
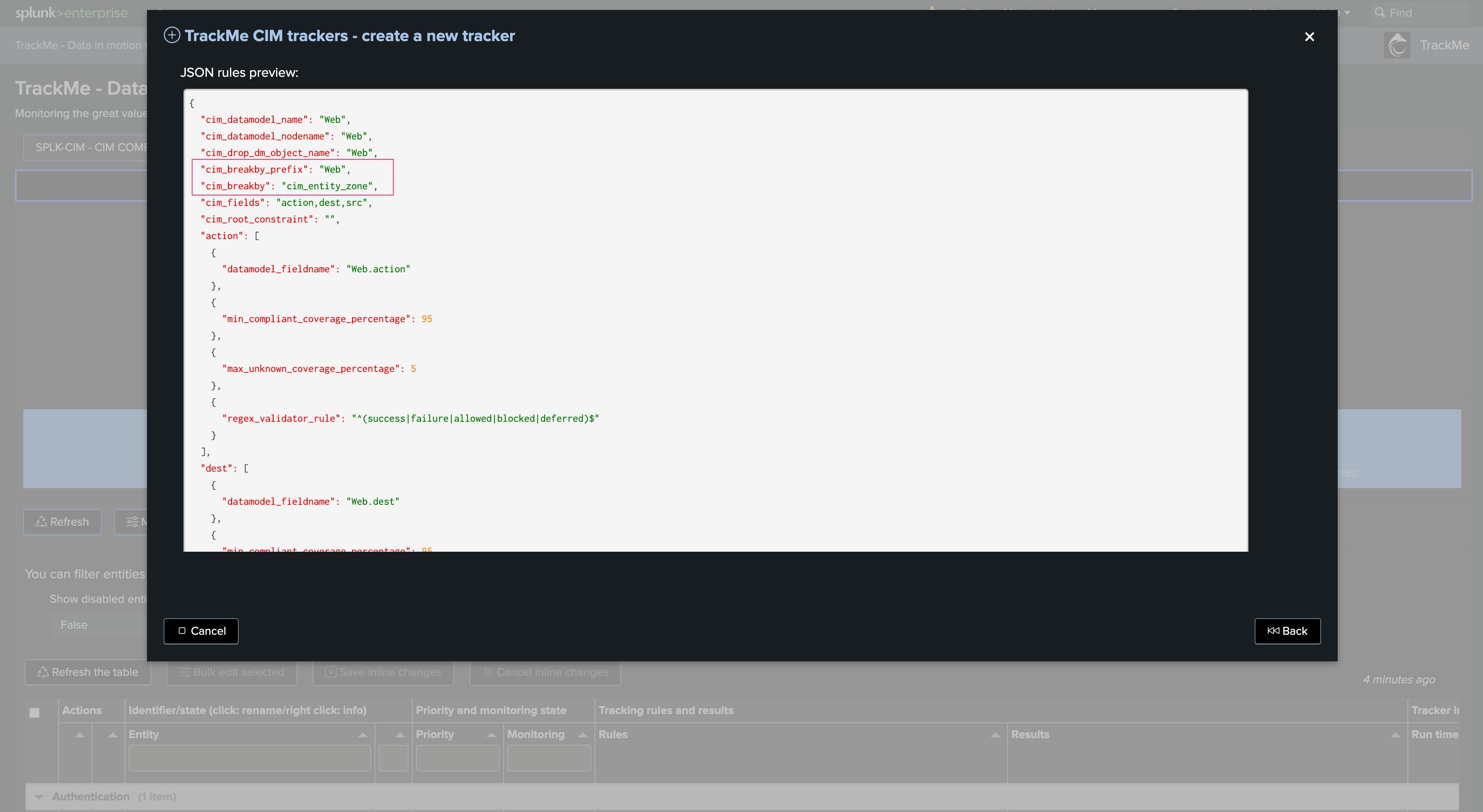
Optionally, you can choose which of these KPIs will be candidates for ML Outliers detection, and the basic parameters for the lower/upper threshold breached behavior:
This is also configured via the SPL query, in a resulting JSON formatted object:
| eval outliers_metrics = "{'dma.complete_pct': {'alert_lower_breached': 1, 'alert_upper_breached': 0}, 'dma.runduration_sec': {'alert_lower_breached': 0, 'alert_upper_breached': 1}}"
Once created, the Flex Tracker automatically generates and ingests these metrics in the metric store and starts to generate and maintain ML models for the purpose of Machine Learning Outliers detection:
Metrics are generated and indexed in the metric index of the Virtual Tenants:
Machine Learning models for Outliers detection will be created and maintained: