Large Scale Environment and Best Practices Configuration Guide
Introduction to High Scale in TrackMe
This documentation aims to provide best practice configuration steps for TrackMe, particularly in large-scale environments.
TrackMe is highly configurable, flexible, and designed for performance and efficiency at scale.
It scales from daily ingests in TB to dozens and much more, with limited and optimized computing costs when respecting good design practices.
However, adhering to best practices and considering specific design aspects are crucial for optimal results.
Scaling Concepts with TrackMe
TrackMe scaling concepts depend on various aspects of the solution, with some key points highlighted below.
TrackMe Virtual Tenants
Virtual Tenants are a core concept in TrackMe V2. In summary:
Virtual Tenants act as virtual instances of TrackMe within the application.
By using Virtual Tenants, you can define the scope and design of your TrackMe implementation.
A Virtual Tenant orchestrates the lifecycle of all TrackMe knowledge objects, from KVstore collections to TrackMe trackers.
Virtual Tenants are created on-demand by TrackMe administrators and can be disabled or deleted later.
This feature allows scoping of Splunk data and entities created by TrackMe, using technical or functional concepts tailored to your preferences and context.
Virtual Tenants support Role-Based Access Control (RBAC) and cater to a wide range of functional and business requirements.
Virtual Tenants offer capabilities beyond the “MSP” (Managed Service Provider) requirements, making TrackMe a unique Splunk application.
TrackMe Trackers
TrackMe implements a concept of Trackers, these are scheduled backend jobs created:
There are different types of Trackers, depending on the components
For Feeds tracking, for instance, you would create multiple Hybrid trackers to address the required data scope, with no overlap between trackers
Dedicated TrackMe Search Head Tiers
At very large scale, it is obviously beneficial to consider a dedicated Search Head tier for TrackMe, either standalone or dedicated:
Keep in mind that TrackMe can use its remote search capabilities; therefore, it technically can deal with any remote deployment, on-premise or Cloud
On-Premise Splunk customers at large scale should consider dedicating a Search Head tier for TrackMe
Cloud customers will leverage the ad-hoc Search Head tier; some customers can also have multiple ad-hoc Search Head tiers and therefore dedicate a specific Search Head tier to TrackMe
In any case, keep in mind that TrackMe should never be actively tracking in the same Search Head tier as a Splunk Premium application, and that we do not support this scenario (Enterprise Security, ITSI).
Requirements for High Scale
TrackMe Splunk Service Account
It is a best practice to use a service account; this allows, for instance, to easily identify related search workloads, investigate the costs related to TrackMe, and so forth.
Using a service account rather than the default admin user when assigning searches also facilitates the implementation of Splunk Workload Management (WLM).
TrackMe implements a least privileges approach, consult:
TrackMe Remote Accounts
With its unique capabilities, TrackMe allows transparent execution of searches against remote Splunk deployments or standalone instances, from Search Head Clusters to Heavy Forwarders, or utility nodes such as Deployment Servers, License Managers, etc.
Depending on the components and your context, you may need as a prerequisite to get service accounts created on remote systems, a bearer token to be created, and remote accounts to be configured in TrackMe.
Consult:
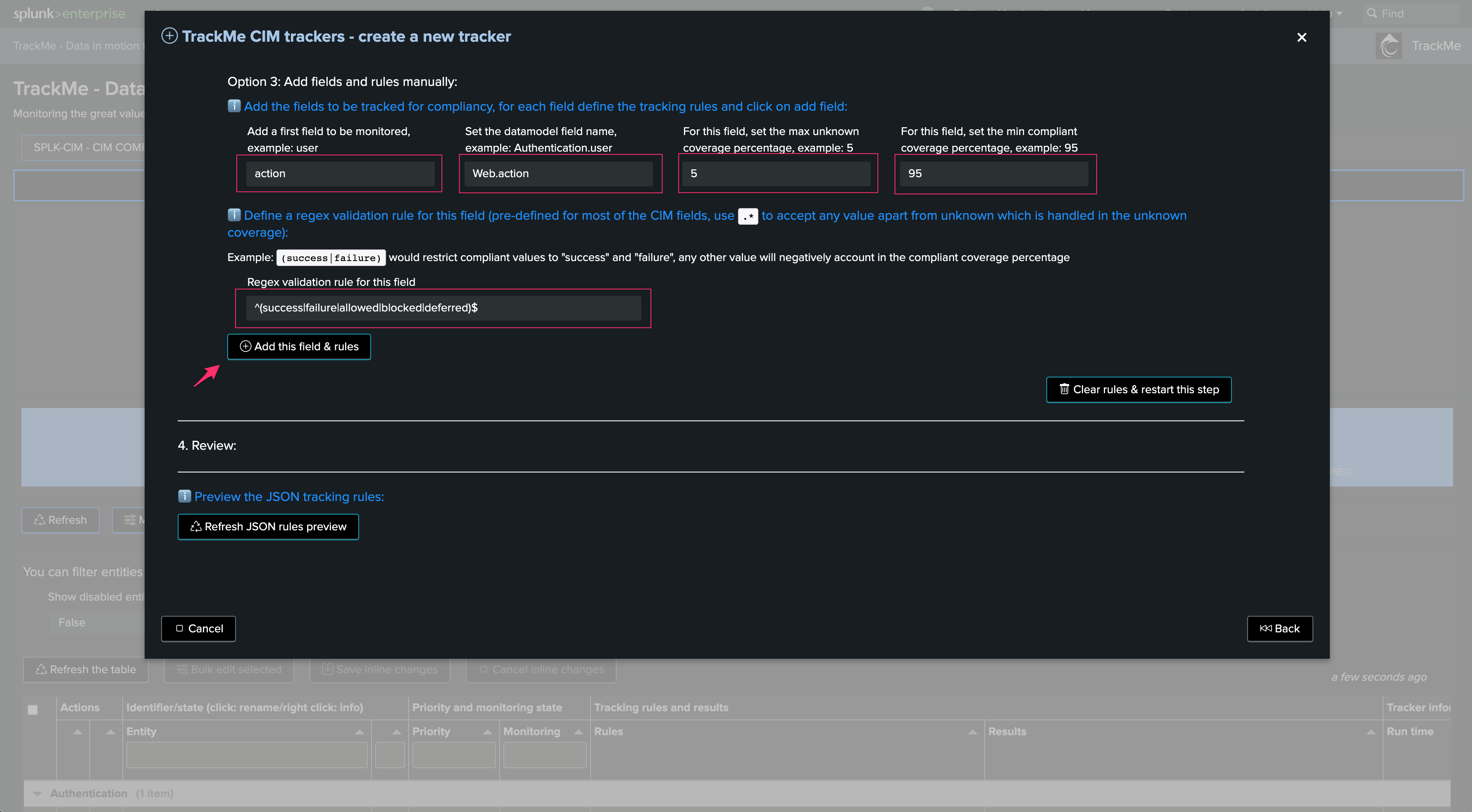
Feeds Tracking (splk-feeds components family)
Feeds tracking is the original core concept of TrackMe, this is covered by 3 components:
splk-dsmwhich is the main and most valuable component; we recommend focusing on this component firstsplk-dhmwhich tracks data by the event host; this is also a valuable component which can however be more expensive from a compute costs perspective, and requires more maturitysplk-mhmwhich tracks metrics from the metric endpoint perspective; this component is more specific to IT-Ops related use cases
Hint
Recommendations
Focus first on the Data Source tracking (splk-dsm)
Be specific and address in priority the most critical indexes in Splunk
For large scale environments, we recommend some preparation work to be performed; the indexes naming convention should be known and documented, as well as top priority indexes and perimeters
Create Tenants according to your needs taking into account perimeters, teams and permissions, etc.
Create empty tenant and proceed to the Hybrid Trackers configuration manually
Create concurrent Hybrid Trackers to address specific scope of your environment; it is more cost efficient to have multiple concurrent Hybrid Trackers addressing restricted scope of indexes than just a few dealing with a huge amount of data
Create an Empty Tenant
Open the tenant wizard creation, and create the first tenant:
Only enable the Data Source tracking component (splk-dsm)
Do not create Hybrid trackers at the phase of the Virtual Tenant creation; instead, create trackers progressively processing benchmarks in the same time
You can create a brand new virgin tenant in a single line of SPL:
Replace the name of the tenant, the service account and roles as needed
| trackme url="/services/trackme/v2/vtenants/admin/add_tenant" mode="post" body="{ 'tenant_desc': 'Feeds Tracking', 'tenant_name': 'feeds-tracking', 'tenant_roles_admin': 'trackme_admin', 'tenant_roles_user': 'trackme_user', 'tenant_owner': 'svc-trackme', 'tenant_idx_settings': 'global', 'tenant_dsm_enabled': 'true', 'tenant_dsm_sampling_obfuscation': 'disabled'}"
Notes: this creates a brand new tenant only with the splk-dsm component; components can be later on added and removed from existing tenants without having to delete and re-create the tenant.
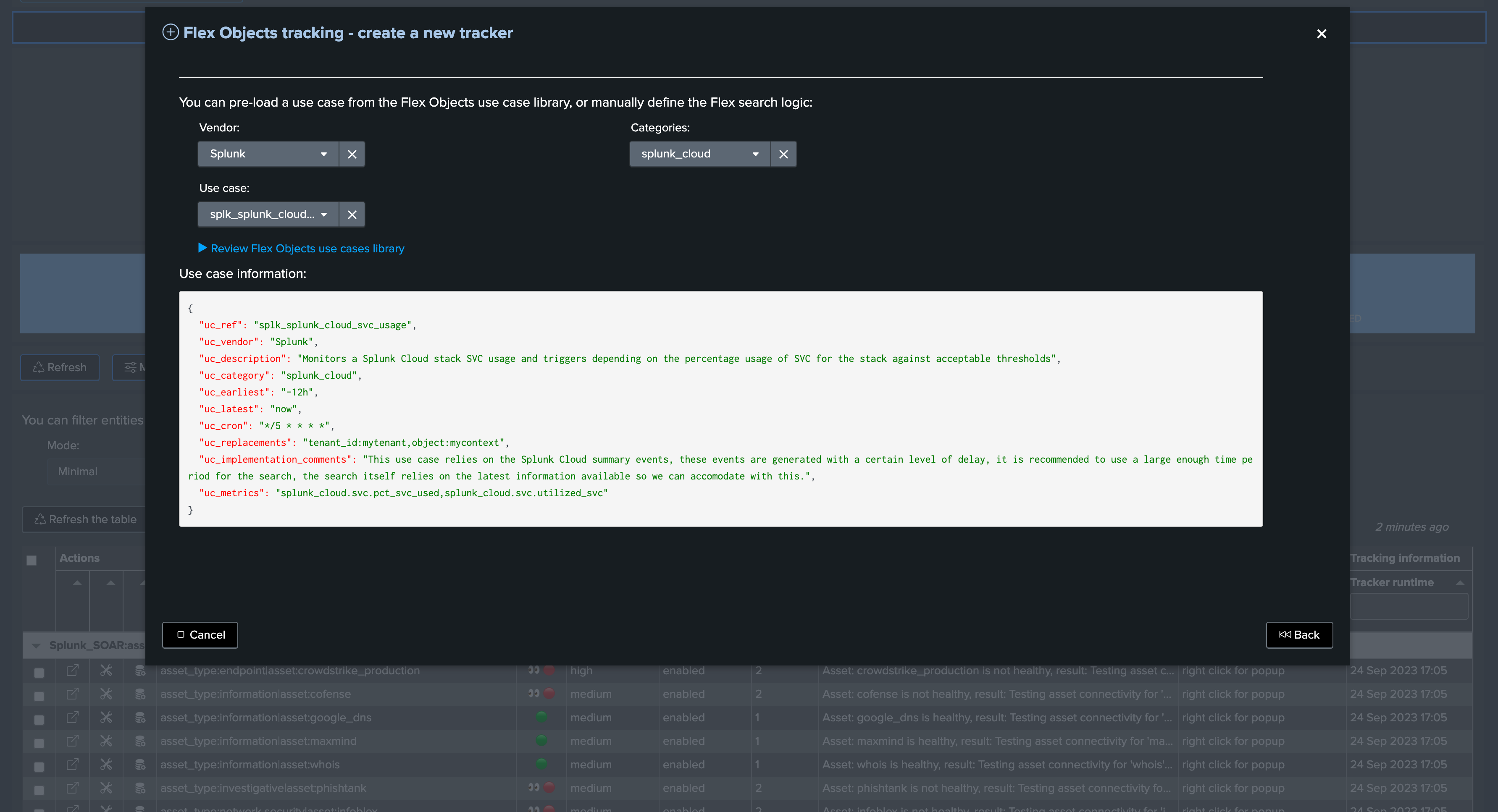
Enter the new tenant
Once the new Virtual Tenant is created, enter the tenant and click on Manage Hybrid Trackers:
Then click on Create new hybrid trackers:
This is where Hybrid Trackers will be defined, tested, benchmarked and finally created.
Open a Search tab in parallel
Have a search tab handy, and let’s run the following simple Splunk search:
indexes convention
In large scale environments, it is a best and right practice to have strong naming conventions
If for instance, your goal is to track security related data, perhaps all these indexes start by
sec_orsiem_Then, make sure to include these concepts in the searches thereafter
| tstats count where index=* earliest=-7d latest=now by index
| eventstats sum(count) as total_count
| eval percent=round(count/total_count*100, 2)
| fields - total_count
| sort - limit=0 percent
The point of this basic search is to identify the volume of events in each Splunk index, then calculate the percentage against the total number of events ingested in the past 7 days.
This in addition with the knowledge of your context and requirements should drive the creation of Hybrid Trackers.
For instance, let’s assume that majority of events is represented by
Firewall related data (Palo Alto, etc)
System logs related data (Windows eventlogs, etc)
Cloud security logs (such as AWS, GCP, etc)
Anything else
In a large scale environment, a likely scenario could be create 4 hybrid trackers, this could for instance results in basically 4 indexes constraints:
Role |
Indexes constraint |
|---|---|
Firewall |
|
System logs |
|
Cloud |
|
Other data |
|
This might well be a first shot that you can review and update while you are running into the configuration, this however provides a clear and easy picture of what to do.
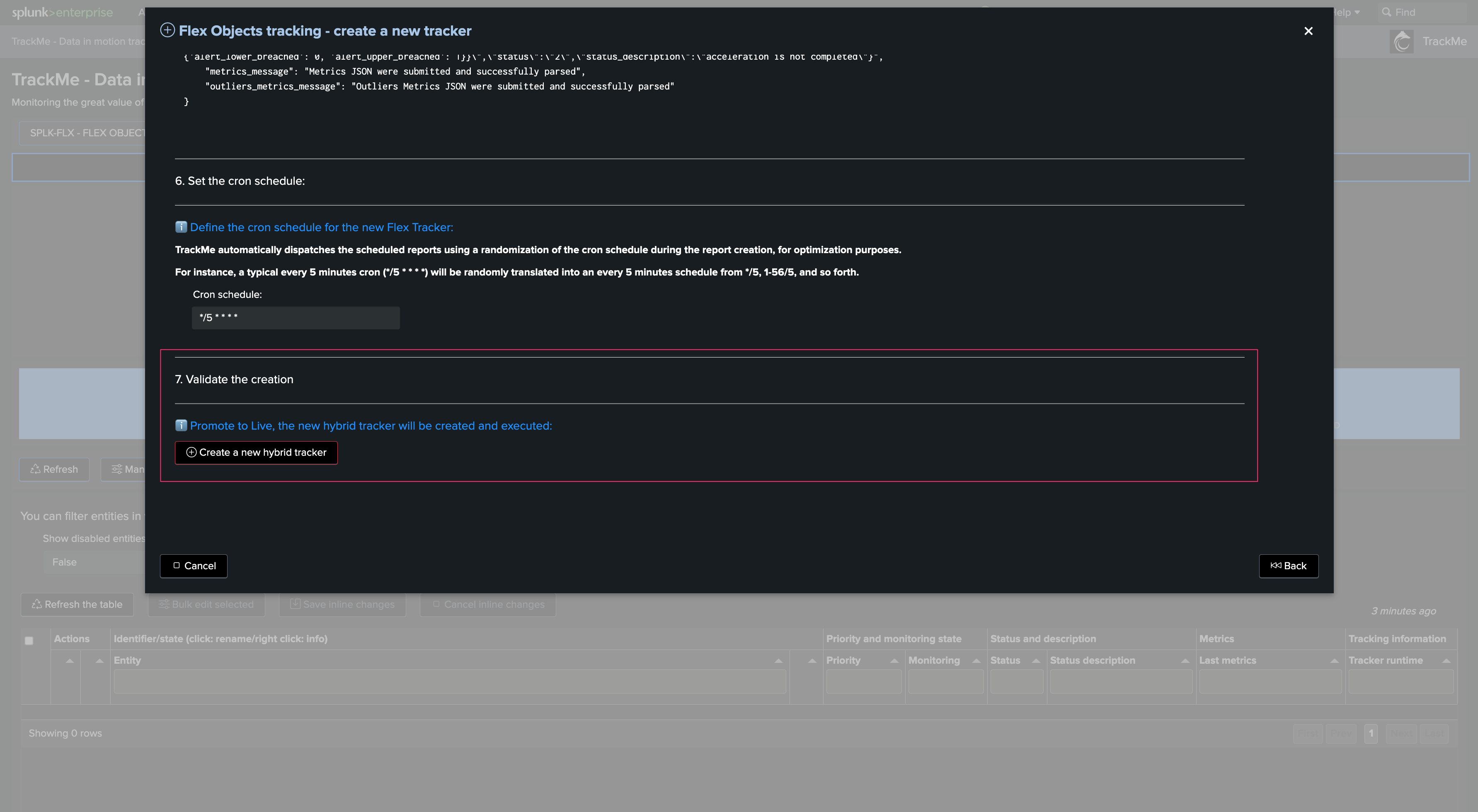
Define, test, benchmark and validate Trackers
Back in the Hybrid Tracker creation user wizard, let’s define our first Hybrid Tracker, test and benchmark:
Provide a meaningful name, this will ease the management over time:
Replace the entire search constraint, TrackMe will store this into a macro associated with the Hybrid Tracker which can be updated as needed later on:*
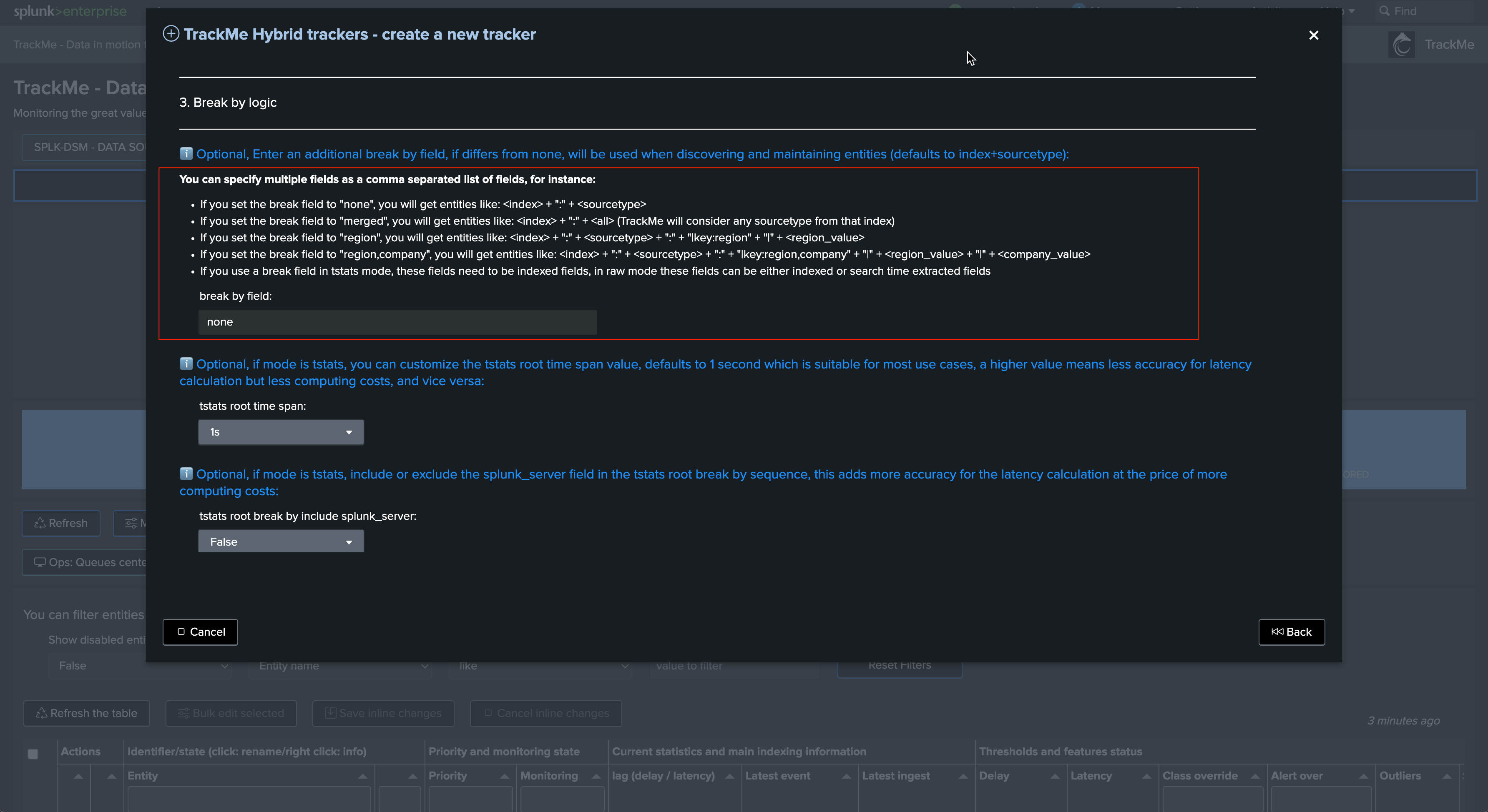
Review the break by statement, this all depends on your requirements, the default means index + “:” + sourcetype:
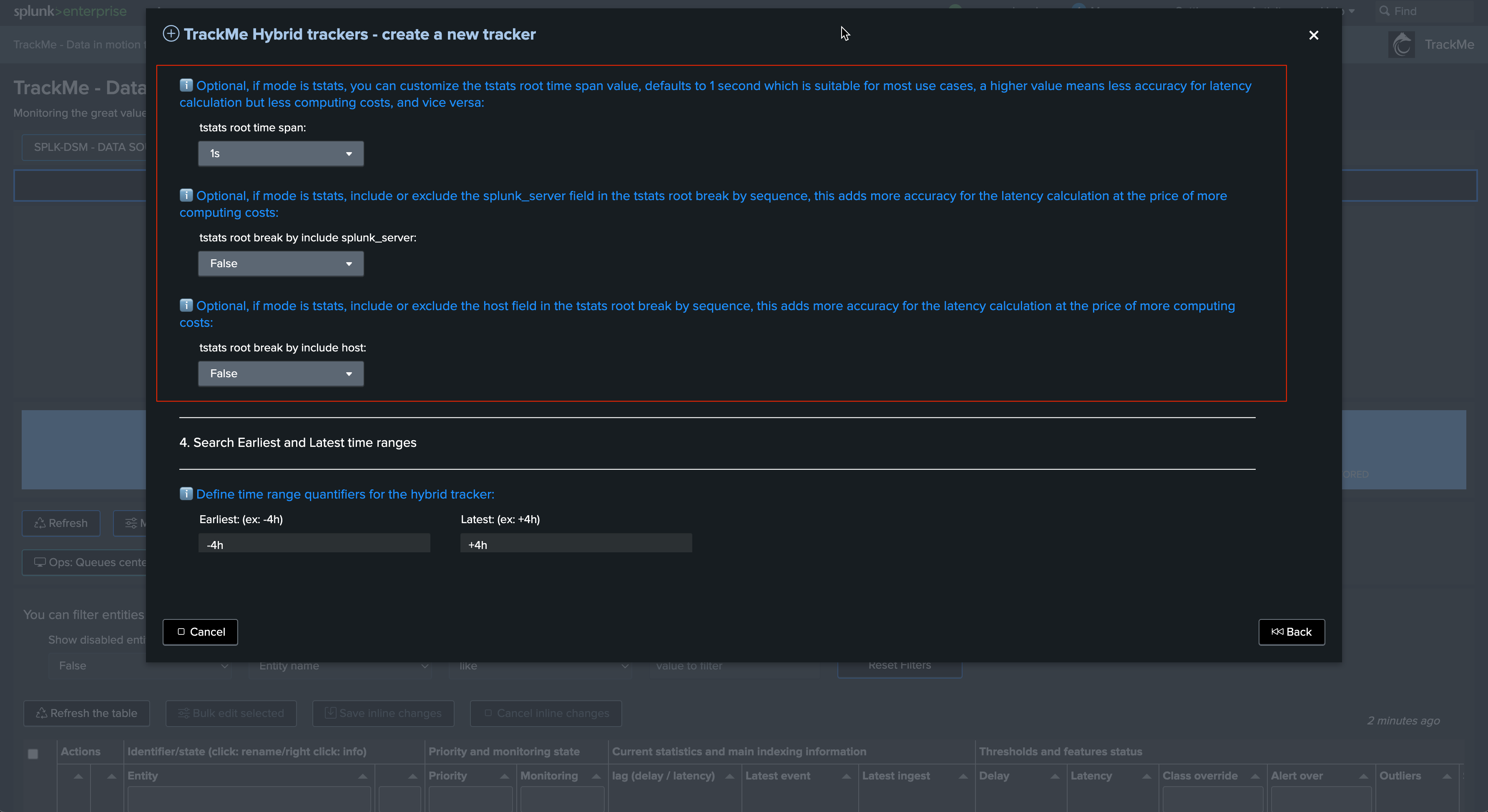
Review additional break by, earliest and latest time quantifiers, for high scale TrackMe licensed customers, these are generally the best cost efficient parameters, users using the Free Limited licence are limited to two Hybrid Trackers and can restrict these furthers to reduce the run time of the trackers:
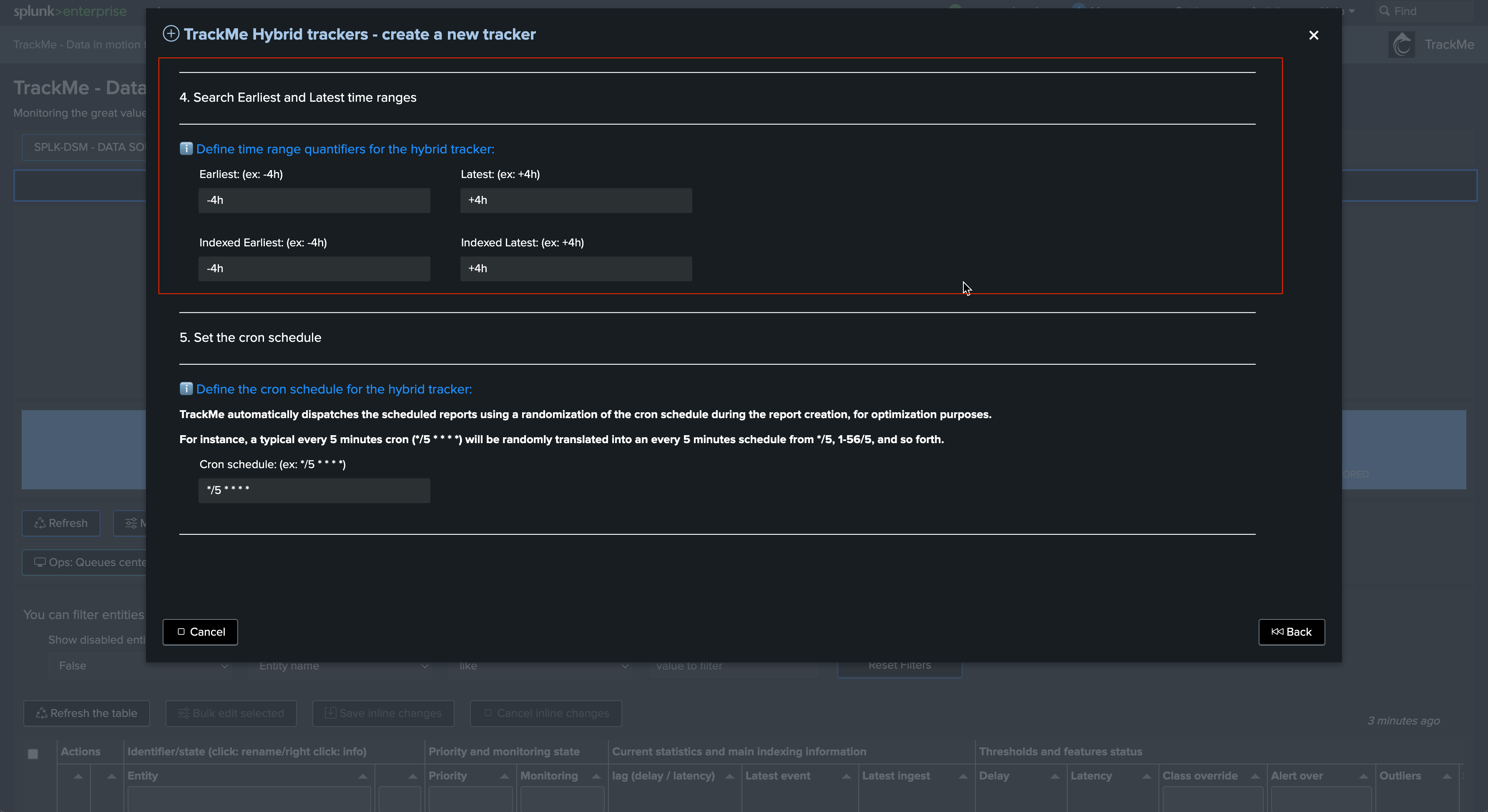
The cron by default is set to every 5 minutes, this is the recommended configuration also for high scale environments as long as the Hybrid Trackers are properly designed:
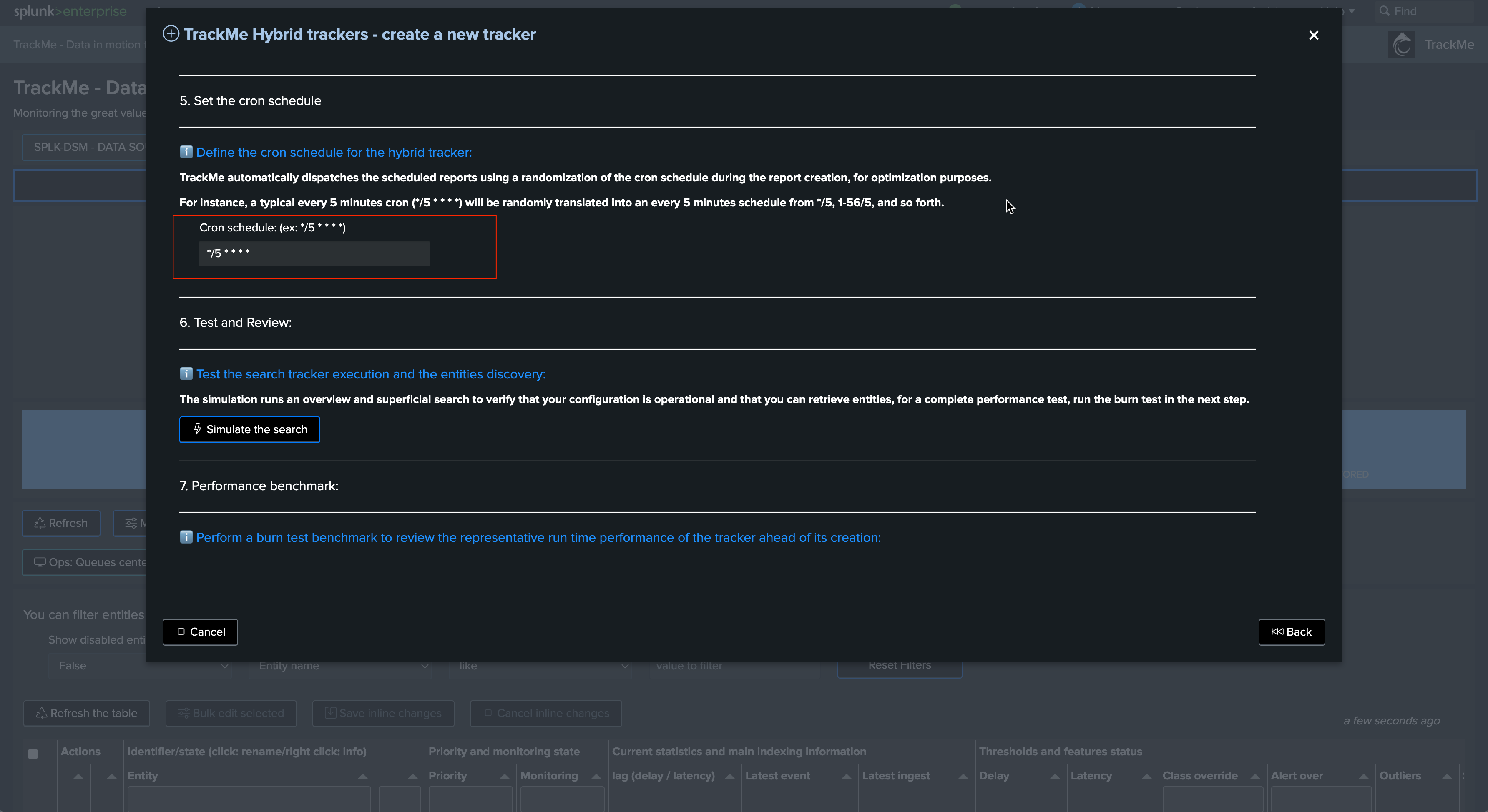
Notes:
A crontab of 5 minutes means we have 300 seconds for the tracker to be executed before starting to generate skipping searches
Skipping searches is the indicator that the configuration is not optimal and that the Hybrid Tracker has too much to be done for a single search instance
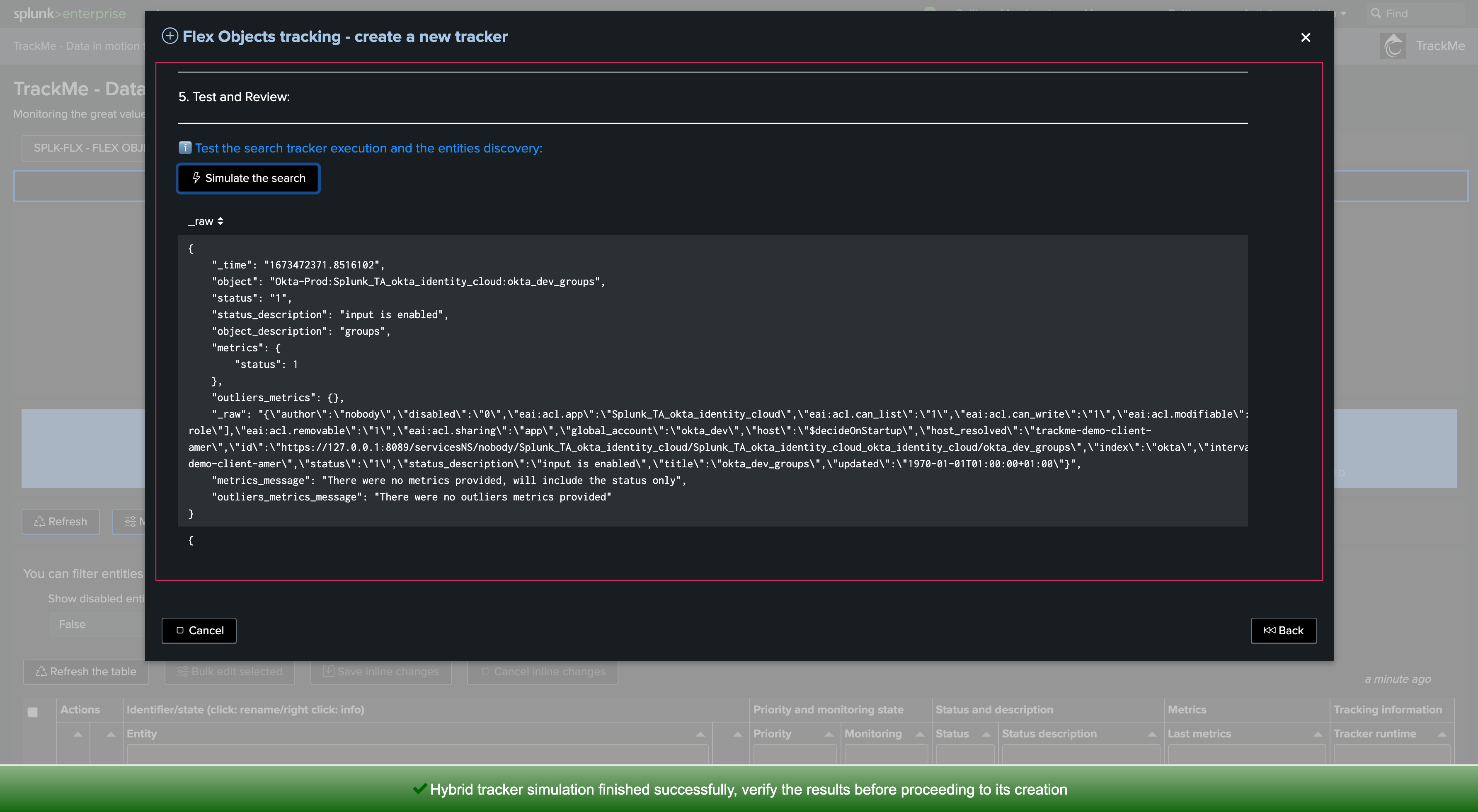
Finally, we can test the search, this test only returns a subset of entities found and gives us a first indication of the performance as well as the content that will be retrieved:
Now, let’s return the benchmark search and run the benchmark test, our search needs to complete in well less than 300 seconds according to our cron time, ideally max approximately 200 seconds:
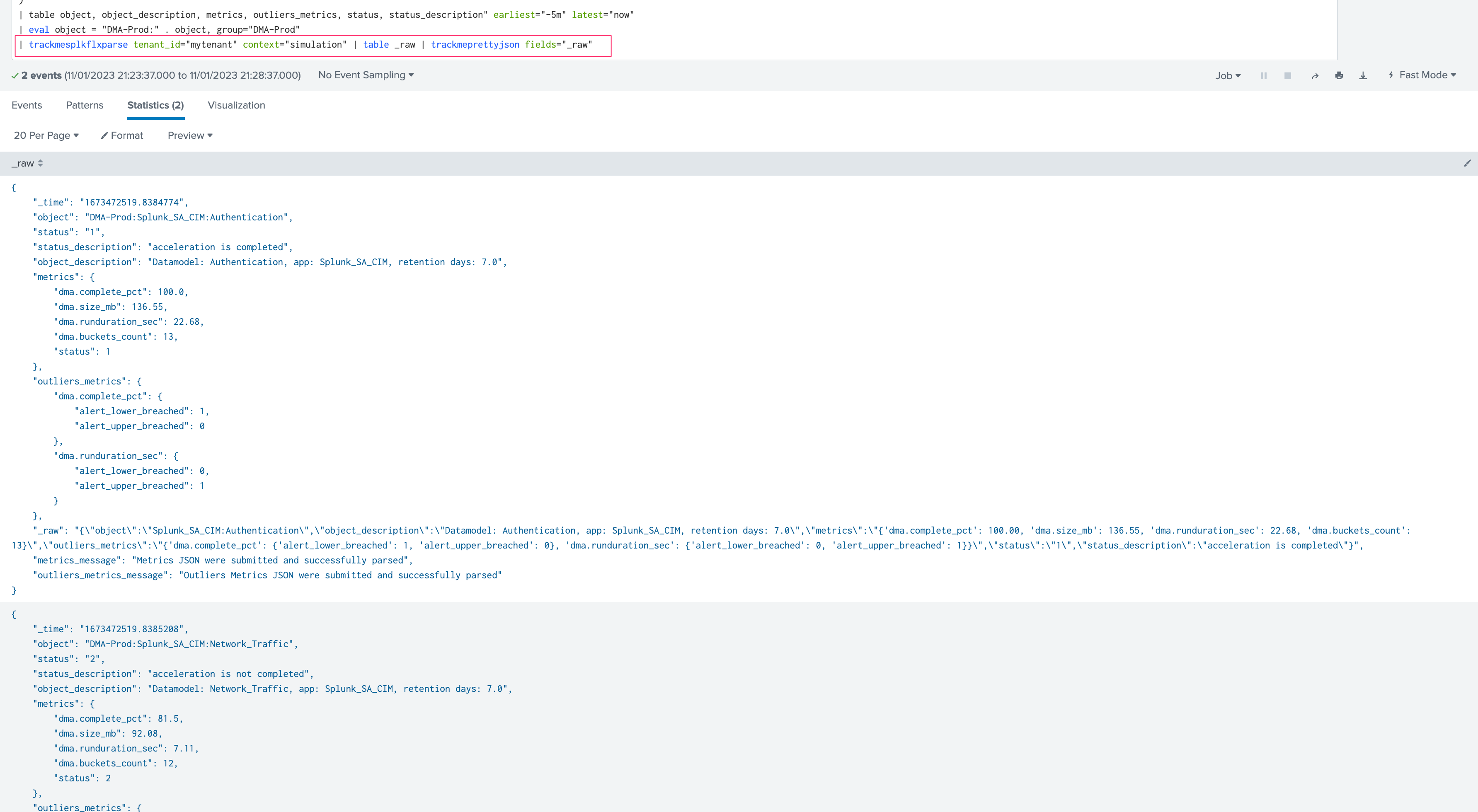
At this stage, if the search run time super fast, this means that the index scope can safety be increased so you can reduce the total number of Hybrid Trackers, but remember that is much more cost efficient to run concurrent smaller Hybrid trackers than just a few very large:*
Notes:
In some circumstances and in Splunk Cloud, the benchmark search can reach the Nginx timeout (which is picky picky)
In that case, you can simply take the benchmark search out and run it in in a search with associated earliest and latest quantifiers
The Benchmark search represents the most expensive part of the search logic that TrackMe will orchestrate
Once we are happy with the design and performance, we can validate the creation of the Hybrid Tracker:
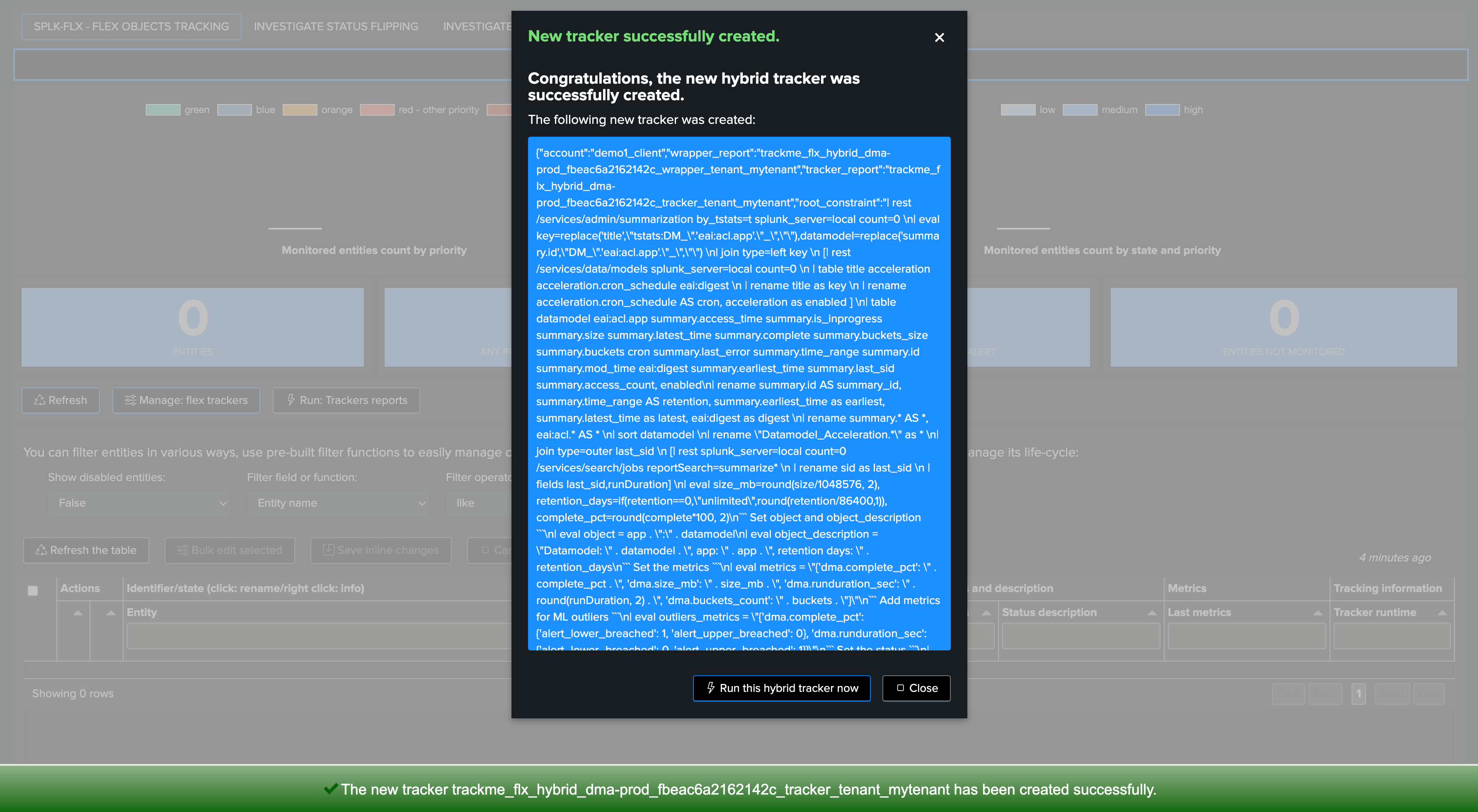
Review Hybrid Trackers Performance
After all Hybrid Trackers were created, and after a few executions, consult the Performance deepdive dashboard: (menu Audit & Troubleshoot)
Types of trackers
TrackMe has various types of trackers depending on the components and their mission
Not all share the same type of schedule; some trackers like the ML related trackers are designed to run over long periods of time on a less frequent schedule, dealing with TrackMe own metrics and automatically stopping as needed
You want to focus on the Hybrid Trackers
Other components and additional considerations
General Tracker Design
As a general rule, all TrackMe components and underneath associated trackers obey the same design:
Trackers should complete in a runtime that is consistent with their cron schedule
Trackers should not overlap; this means that for instance with feeds tracking, trackers should look at specific set of indexes but unless using a different break by, there are no reasons why these would share the same indexes
Trackers systematically report their runtime performance and report failures to the component register
Trackers are component specific; the activity of feeds tracking is not the same as Workload or Flex Trackers, but the philosophy remains similar
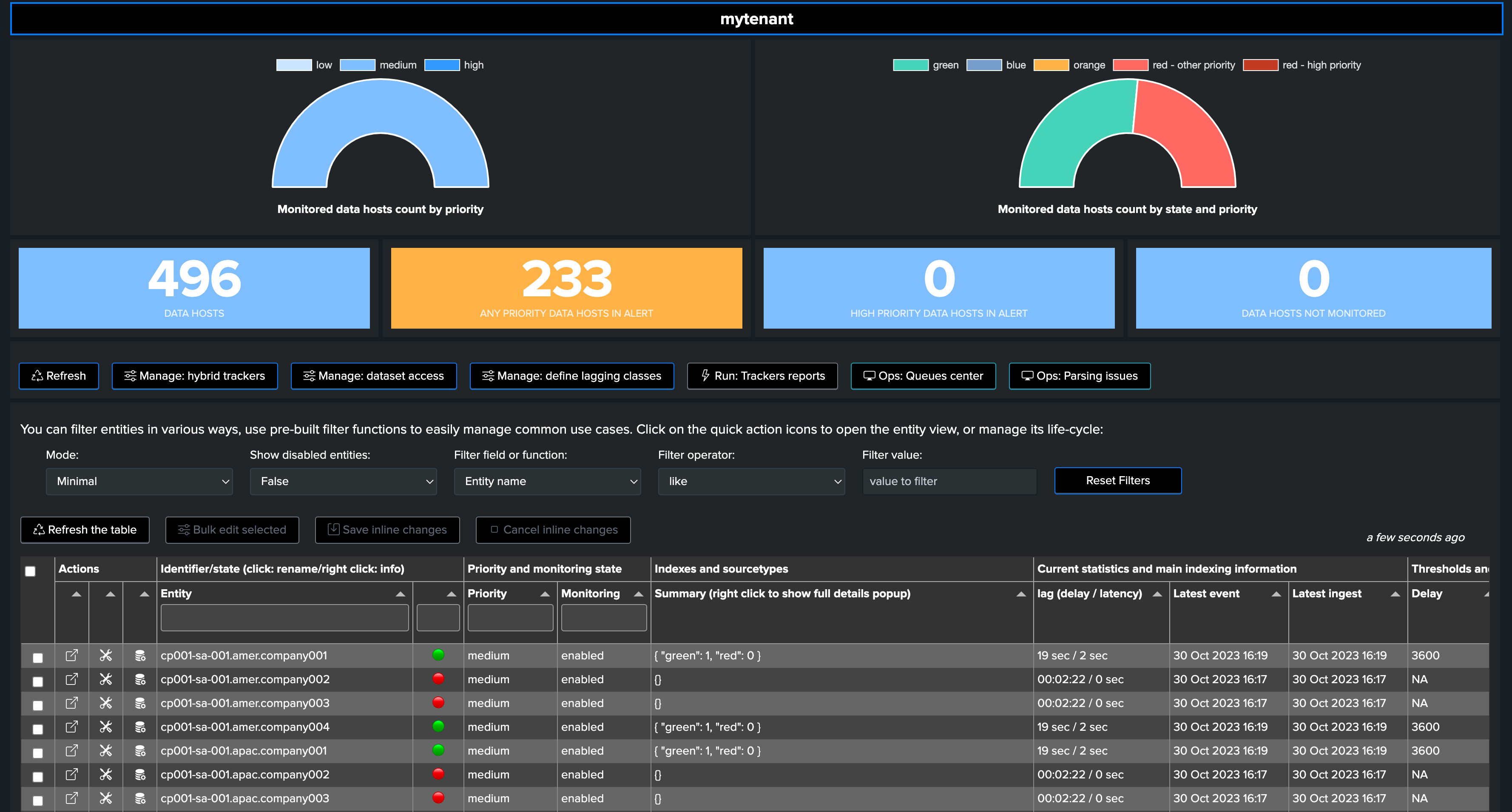
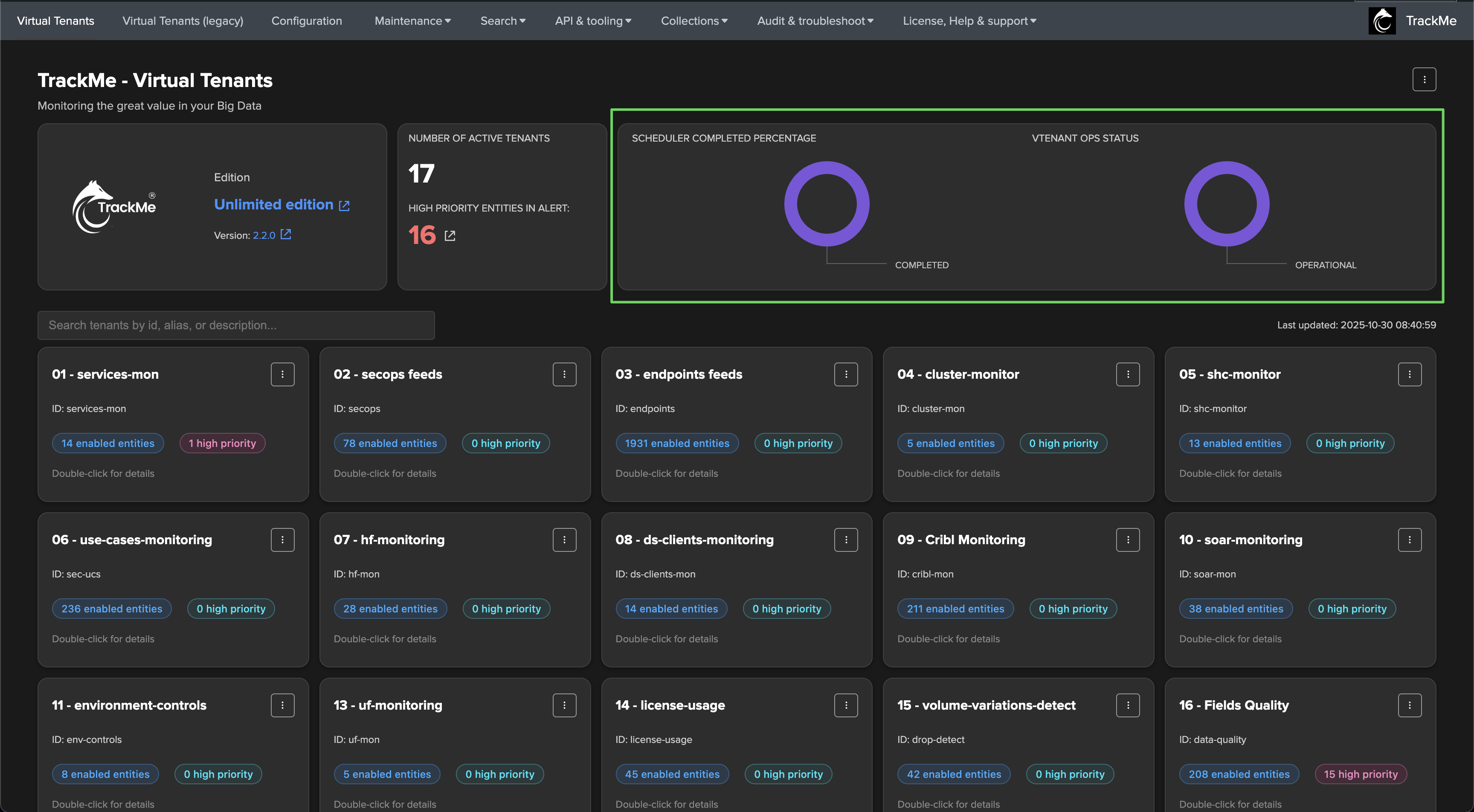
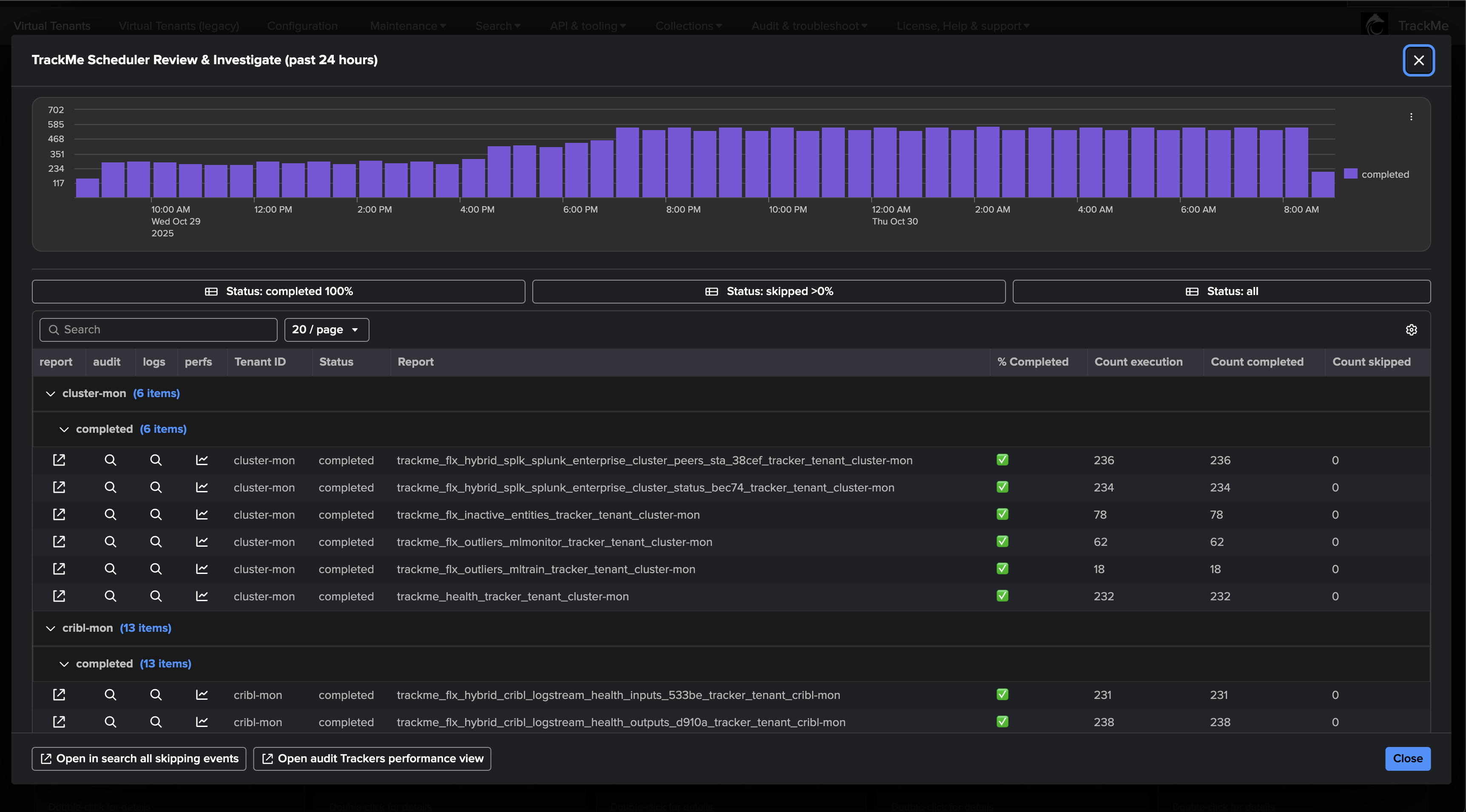
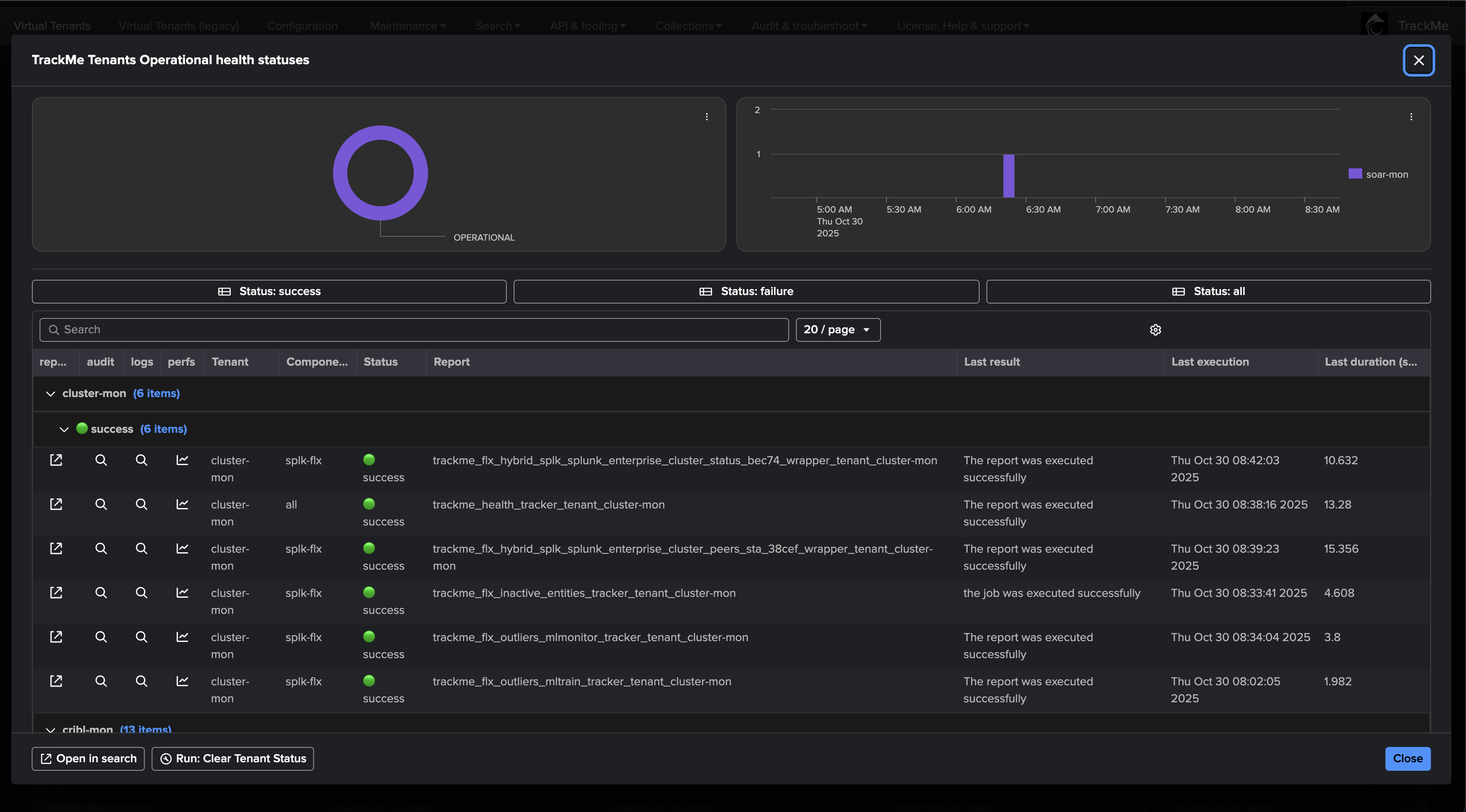
Review and Monitor Virtual Tenants Activity
TrackMe carefully reports any issue affecting the Virtual Tenants and trackers; for instance, concurrent execution being reached on the instance would lead to failures easily visible:
Alerting Architecture in TrackMe
We recommend defining an Alerting Architecture based on TrackMe Notable events which provides several advantages, especially at large scale:
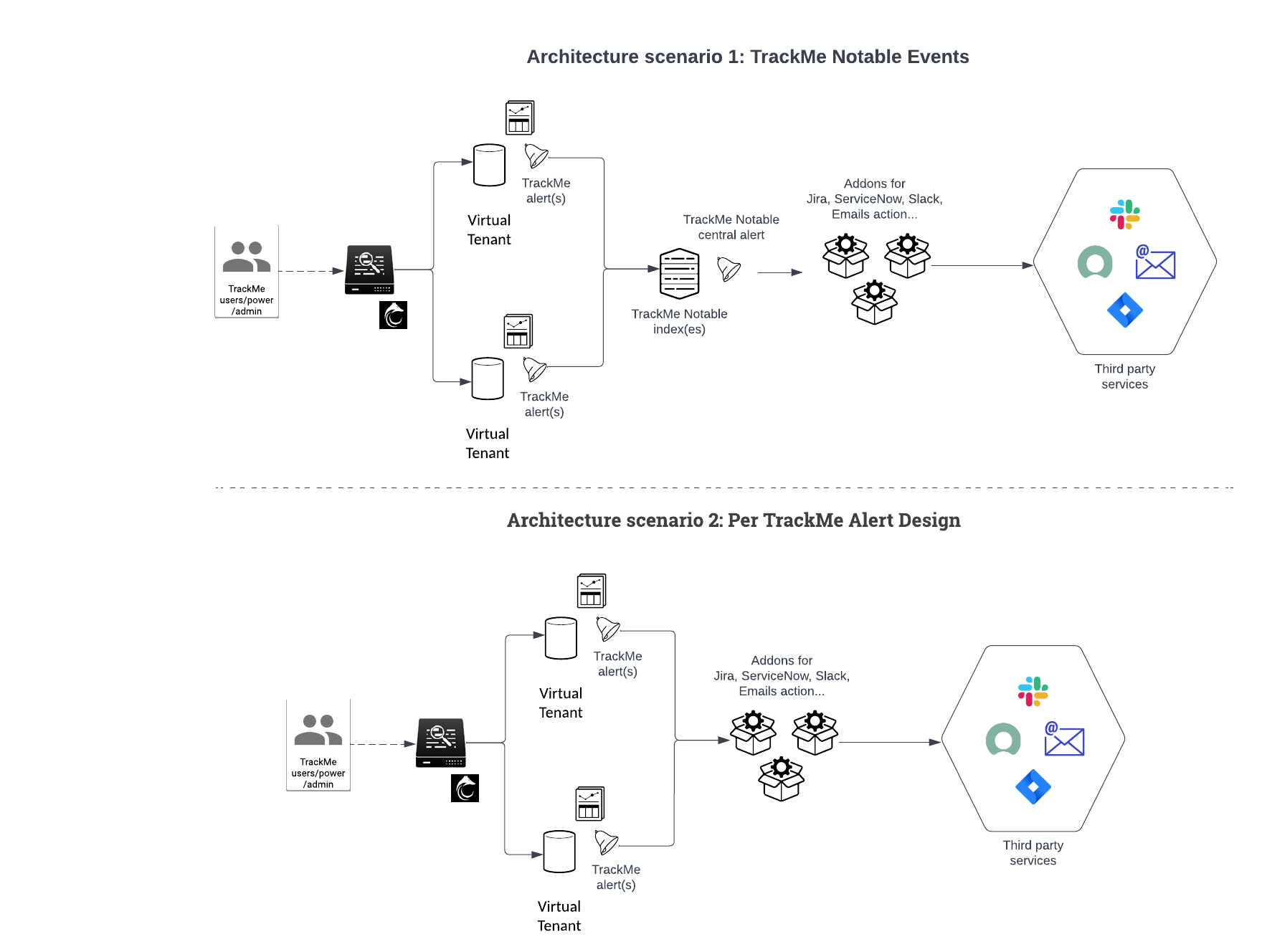
However, both options are valid design options, which can be implemented in TrackMe in a straightforward and flexible way.