Configuration
Hint
Looking for a Quickstart?
If you are looking for a quickstart, you can refer to the QUICK START - Starting with TrackMe: (feed tracking quickstart)
The quickstart guide provides a step-by-step guide to get started with TrackMe, focusing on feed tracking, the easy and simple way
Using a service account for TrackMe is not mandatory
It is not mandatory to use a service account for TrackMe, as described in the next steps, but it can be considered a good practice which provides several advantages in terms of management and monitoring
However, this is not required as such and not doing so will not prevent TrackMe from operating normally
By default, TrackMe will create knowledge objects and run searches as the “nobody” user (Splunk system account), which does not require any setup
Hint
Distinguishing permissions requirements between service accounts, TrackMe administrators, Power and read-only users
A service account is a Splunk user (internal or SAML) that is used by TrackMe to perform scheduled activities, such as the creation of knowledge objects, the execution of scheduled searches, the creation of Virtual Tenants, etc.
TrackMe users can have different levels of permissions. TrackMe comes with 3 built-in concepts for users: administrators, power users, and read-only users
TrackMe leverages sophisticated techniques to ensure that you can define minimal permissions, for both the service account and the TrackMe users
This allows for TrackMe users (TrackMe admins, power and read-only users) to avoid having to provide potentially dangerous capabilities such as list_settings, list_storage_passwords, etc.
TrackMe comes with 3 built-in roles, trackme_admin, trackme_power and trackme_user
trackme_user inherits from Splunk built-in user role, trackme_power inherits from trackme_user and trackme_admin inherits from trackme_power
Each TrackMe built-in role enables the associated TrackMe capability, for instance trackme_admin enables the trackmeadminoperations capability
Summary Requirements for the TrackMe Service Account
The following requirements are the minimal requirements for the TrackMe service account:
Indexes Access
The service account should be able to search all non-internal indexes and all internal indexes (or at least the indexes containing data to be monitored, as well as the _internal index)
Capabilities
The service account should have the following capabilities at the minimum:
Capability |
Note |
|---|---|
get_metadata |
|
get_typeahead |
|
list_accelerate_search |
|
list_all_objects |
|
list_inputs |
|
list_metrics_catalog |
|
output_file |
|
pattern_detect |
|
request_remote_tok |
|
rest_access_server_endpoints |
|
rest_apps_view |
|
rest_properties_get |
|
rest_properties_set |
|
run_collect |
|
run_custom_command |
|
run_dump |
|
run_mcollect |
|
schedule_search |
Required for running scheduled searches |
search |
|
trackmeadminoperations |
Can be inherited from the trackme_admin role |
trackmepoweroperations |
Can be inherited from the trackme_power role |
trackmeuseroperations |
Can be inherited from the trackme_user role |
Summary Requirements for TrackMe Administrators
Essentially, TrackMe administrators need to have the following capability:
Capability |
Note |
|---|---|
trackmeadminoperations |
Can be inherited from the trackme_admin role |
In addition, and to be able to access and update the configuration menu items (Menu Configuration), administrators need:
These are required capabilities by the Splunk UCC Framework, which is used by TrackMe for the purposes of the configuration level backend
This is in fact optional; however, lacking these capabilities will not allow using the configuration UI to create remote service accounts for instance
These capabilities would be required for users in charge of the highest level of administration of TrackMe; these are not required for the service accounts
These capabilities are required only for the configuration UI; these are not required for the creation and/or management of TrackMe knowledge objects (virtual tenants, trackers, …)
Capability |
Note |
|---|---|
list_settings |
Allows accessing the configuration UI |
list_storage_passwords |
Allows accessing the configuration UI |
admin_all_objects |
Allows updating the configuration items |
Service Account and Permissions
To operate, TrackMe allows and recommends defining a Splunk user that has the ownership of any knowledge objects created by TrackMe as part of the Virtual Tenant lifecycle:
Knowledge Objects (such as reports, alerts…) will be assigned to the user tagged as the owner of the Virtual Tenant
Scheduled activities will run on behalf of the service account owner
By default, TrackMe assigns the user “admin” as the default owner of the Virtual Tenant; it is best practice to create your own service account owner. The following minimal permissions and capabilities are required:
The service account needs to be a member of the built-in role
trackme_adminas this provides thetrackmeadminoperationscapability, or this capability needs to be granted explicitlyThe service account needs to be able to search all
non-internal indexesand allinternal indexesThe service account needs to be able to run scheduled searches; typically you can use the Splunk built-in
powerrole
TrackMe implements a strict least privileges approach; consult Role Based Access Control and ownership
Note
Local service account user or SAML service account
You can set up the service account user as a local user or a SAML user on the TrackMe Search Heads tier
For other Search Head tiers, TrackMe can interact with the Splunk API for various powerful use cases such as TrackMe Flex Object trackers or the Workload component
This requires a service account on the target Search Heads tier and a bearer token to be created
If you want to create a SAML service account for TrackMe’s remote search capabilities, you need to have the SAML AQR setup, and an Identity Provider (IDP) supported by Splunk
Reference: https://docs.splunk.com/Documentation/Splunk/latest/Security/Setupauthenticationwithtokens
Reference: https://docs.splunk.com/Documentation/SplunkCloud/latest/Security/SAMLConfigJWT
Creating a Service Account for TrackMe with Minimal Permissions
Warning
** permissions requirements for alert actions (stateful, notables…)**
Make sure to give the following capabilities to the service account:
Capability |
Note |
|---|---|
list_settings |
Allows accessing the configuration UI |
list_storage_passwords |
Allows accessing the configuration UI |
admin_all_objects |
Allows updating the configuration items |
Note
Version 2.0.48 and later required for minimal permissions
TrackMe version 2.0.48 and later is required for the following procedure allowing a strict minimalist service account
Before this version, the service account needs to have extended capabilities such as list_settings and list_storage_passwords capabilities; therefore, the recommendation was for the service account to be a member of admin/sc_admin
Some advanced use cases such as Flex Object trackers dealing with the Splunk
| restcommand or SOAR-related use cases may need additional capabilities to be granted to the service account user
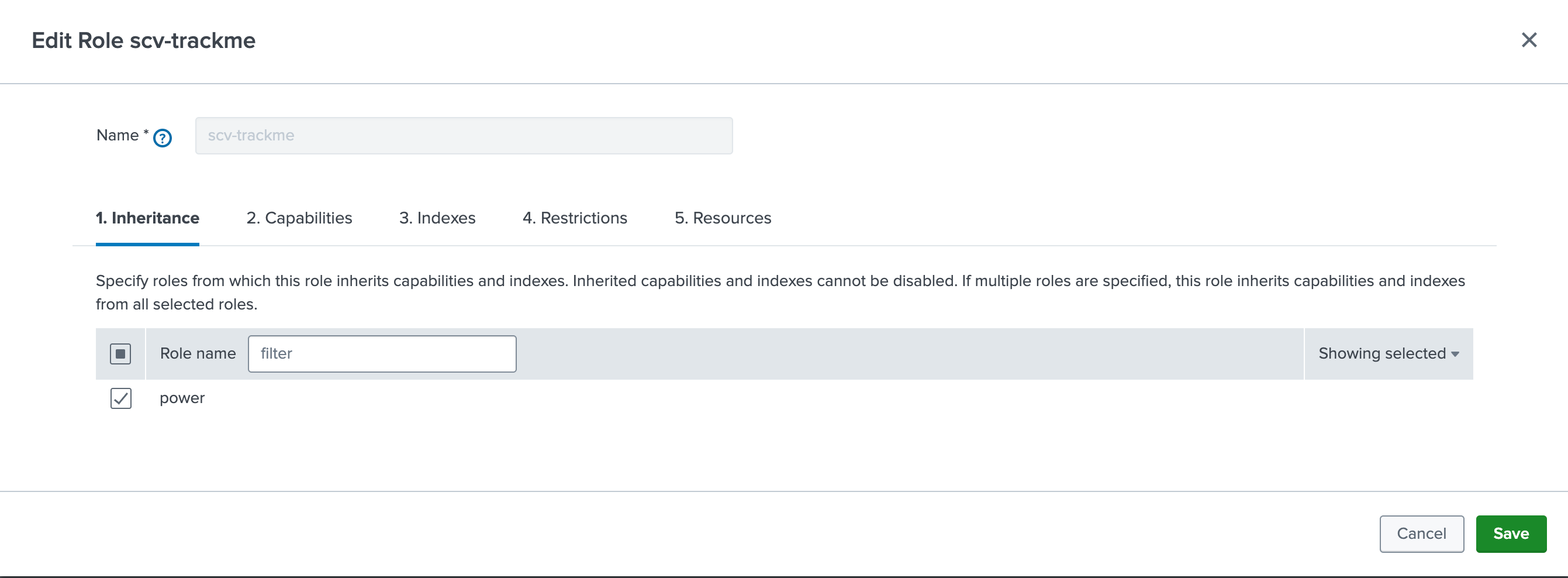
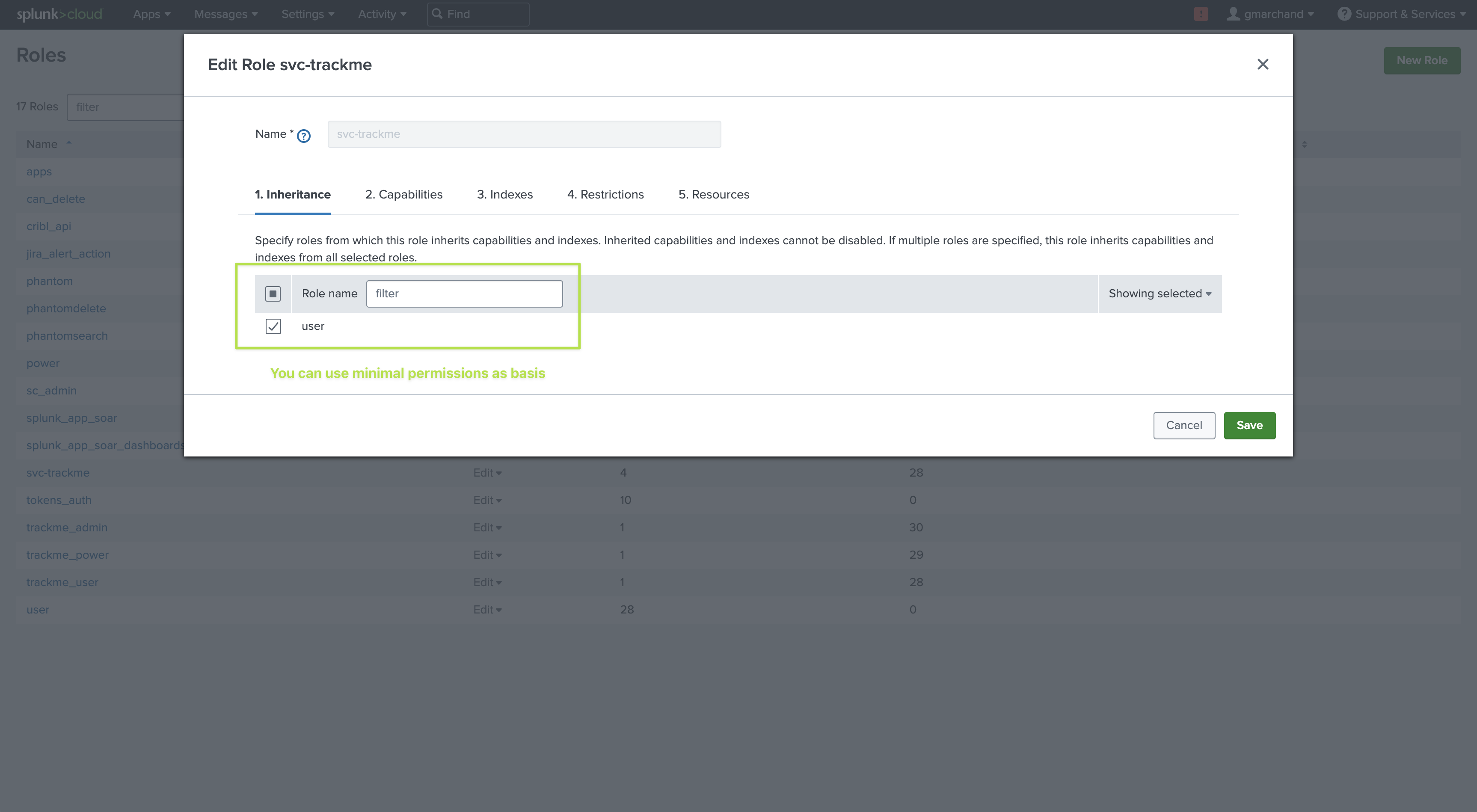
One option is to create a specific role for the TrackMe service account with:
Inheritance roles:
powerRole membership:
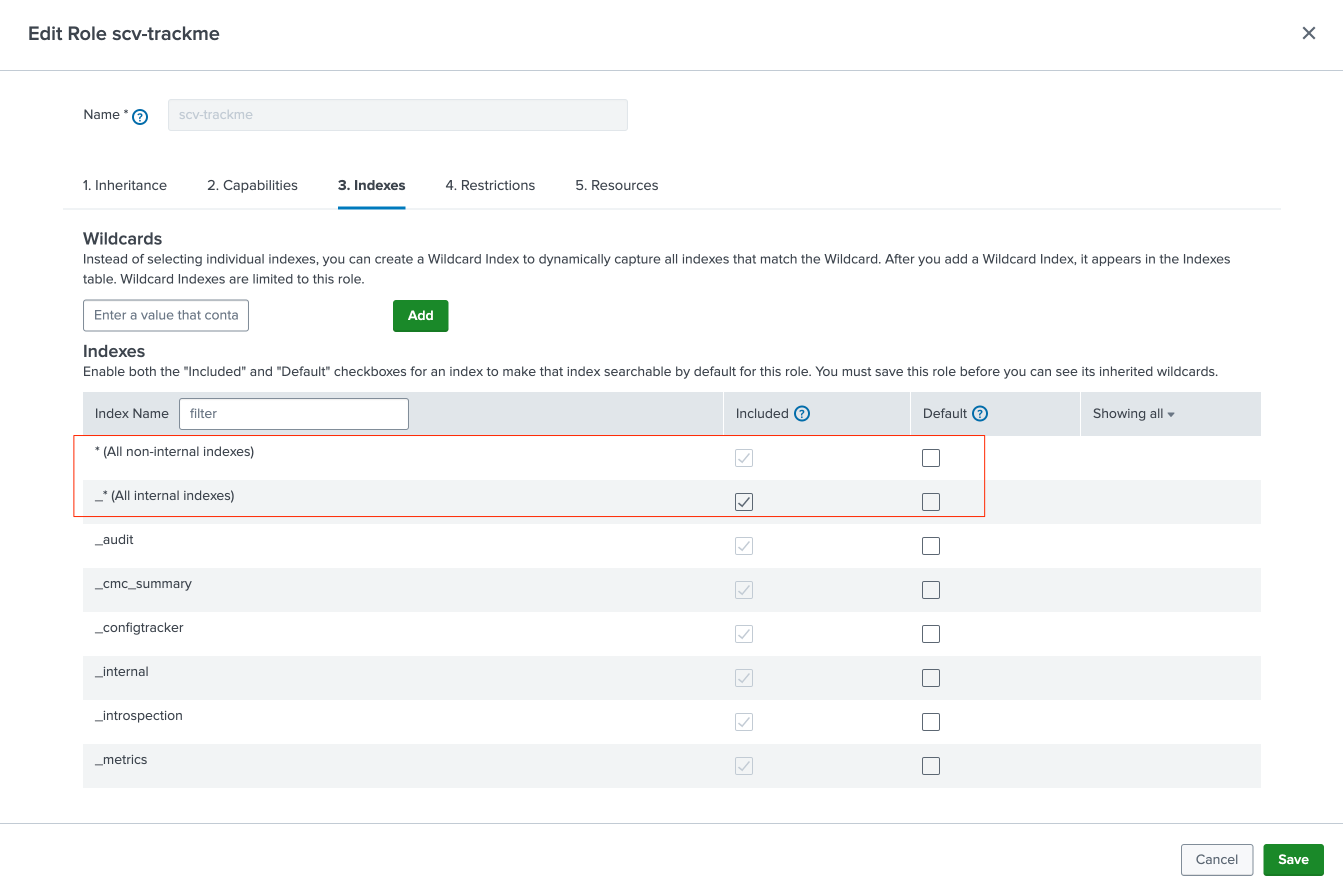
trackme_adminIndexes:
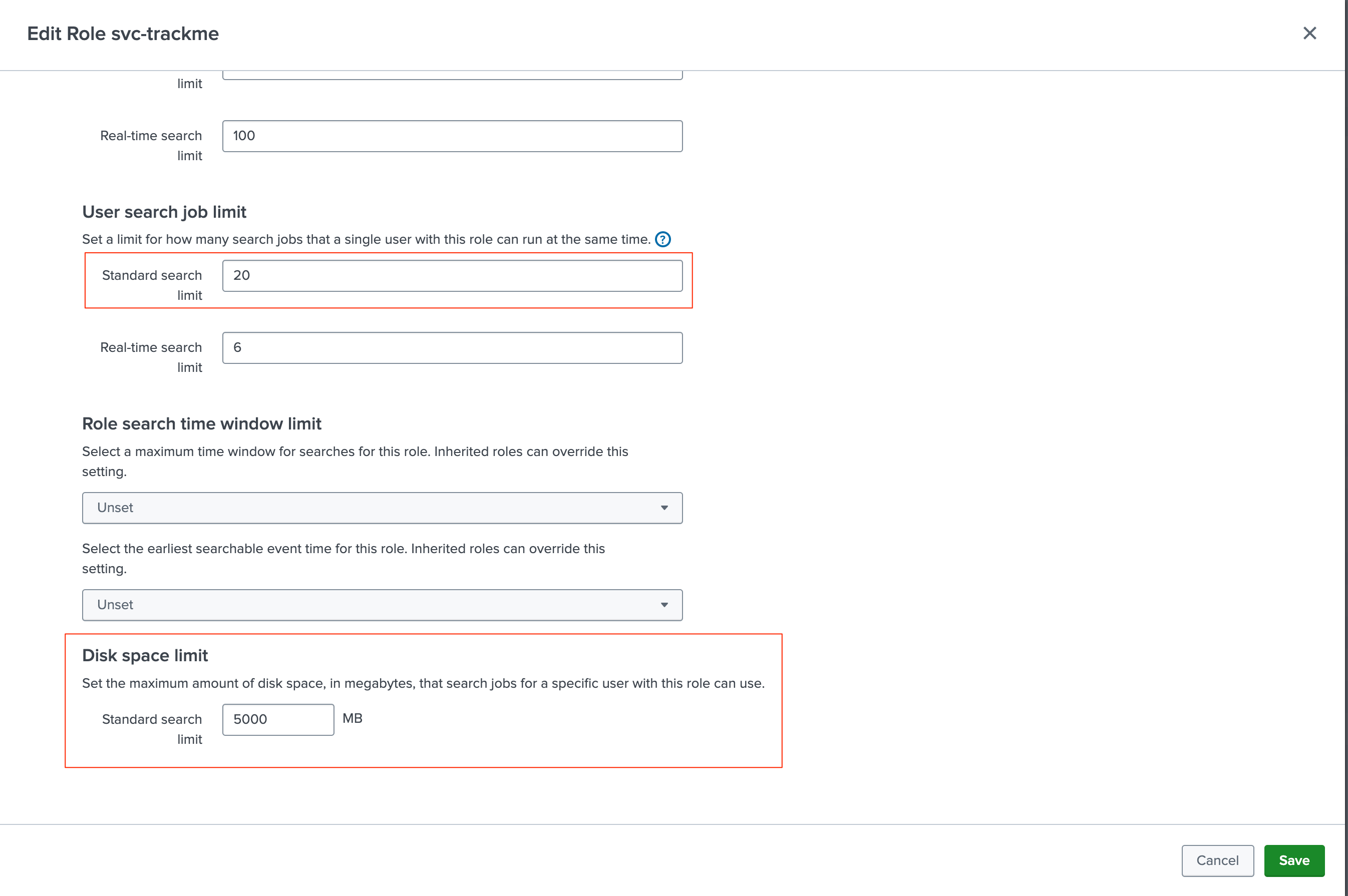
all non-internalandall internalindexesResources: While TrackMe is optimized to distribute scheduled searches, it should be capable of running sufficient concurrent searches and it requires a large file quota to avoid issues
Hint
trackme_admin membership for the service account
Before version 2.0.61, the service account needs to be an explicit member of the
trackme_adminrole (or the admin role in the tenants); this is needed because TrackMe requires explicit role membership (opposed to inheritance) to grant access to the Virtual TenantsFrom version 2.0.61, all RBAC dimensions in TrackMe support inheritance transparently
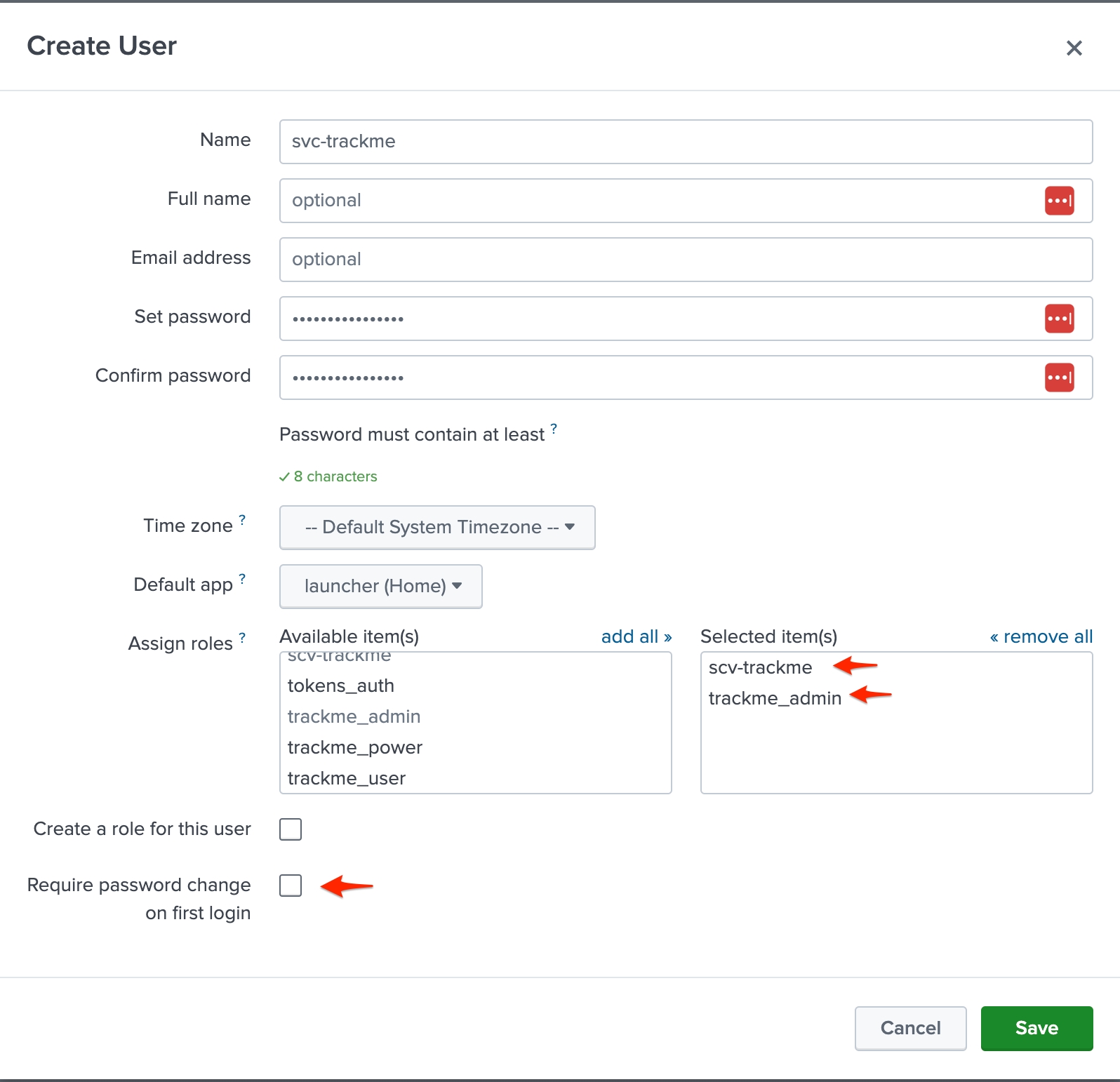
You can can then create the service account itself, example:
The user is a member of the
svc-trackmeroleAs mentioned above, it is also a member of
trackme_adminto be granted access to the Virtual TenantsUncheck the box “Require password change on first login”
When you create a Virtual Tenant, you will specify the service account as the owner of the Virtual Tenant:
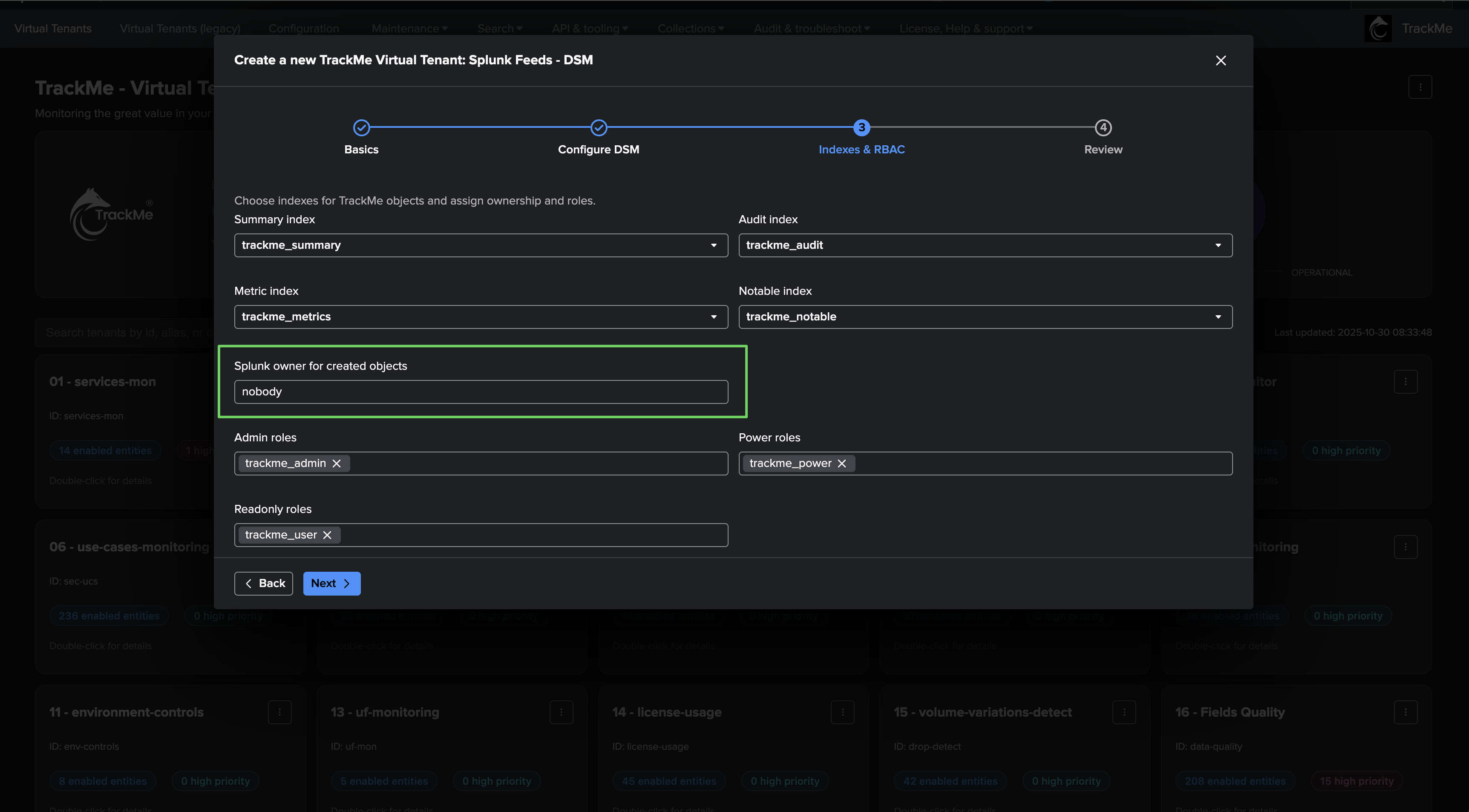
Hint
preset RBAC for the tenant creation UI
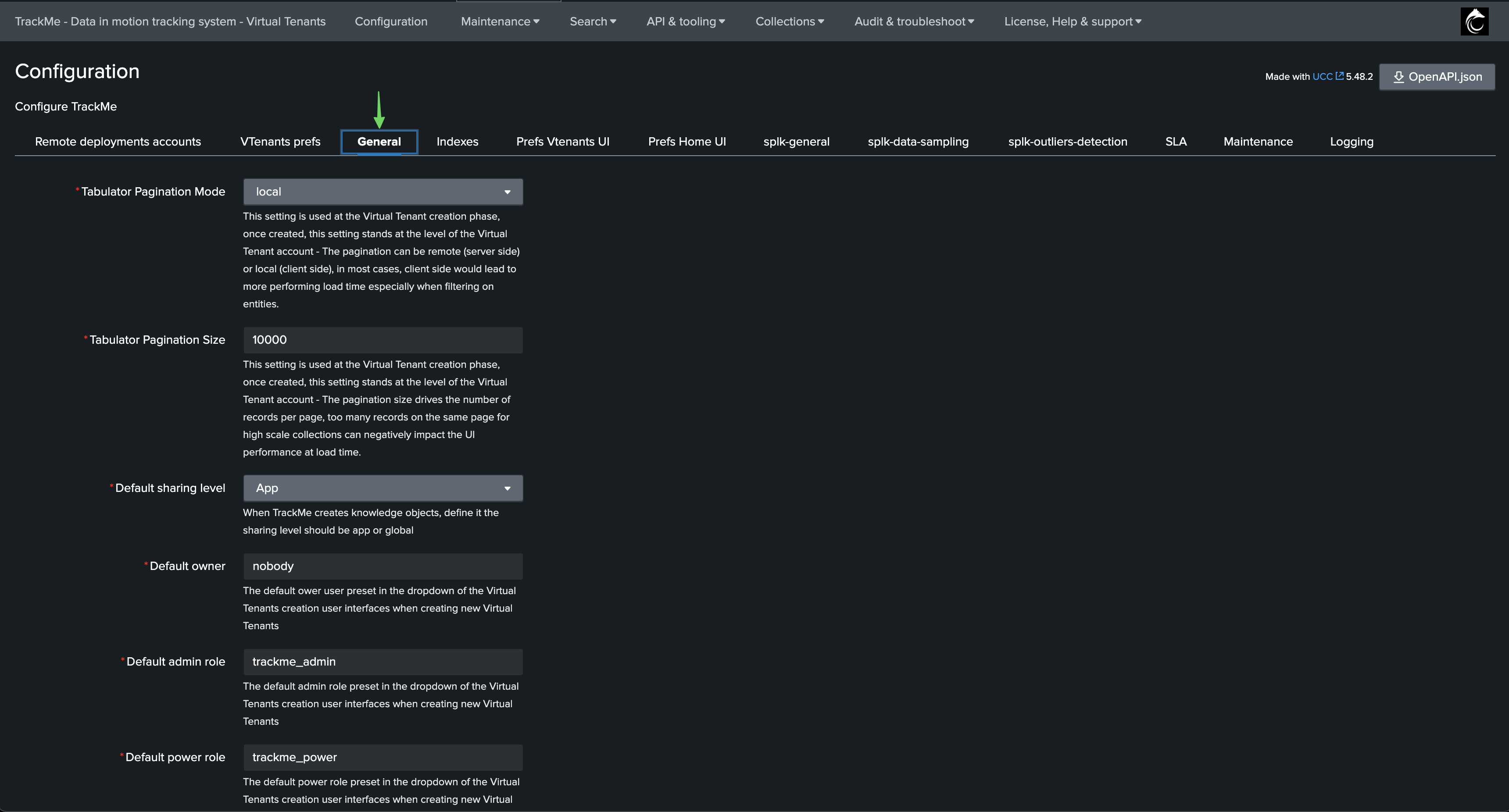
Since the version 2.0.52, you can preset values for the owner and roles when creating a new Virtual Tenant from the UI
Go in the Configuration then General Configuration
Minimal capabilities and resources for Remote Accounts and the user associated with the bearer token
TrackMe remote capabilities rely on a Splunk bearer token authentication, this token is associated with a Splunk user on the remote side which itself is associated with specific roles, capabilities, permissions and resources restrictions:
Roles and capabilities: The user can be created with minimal permissions using the Splunk
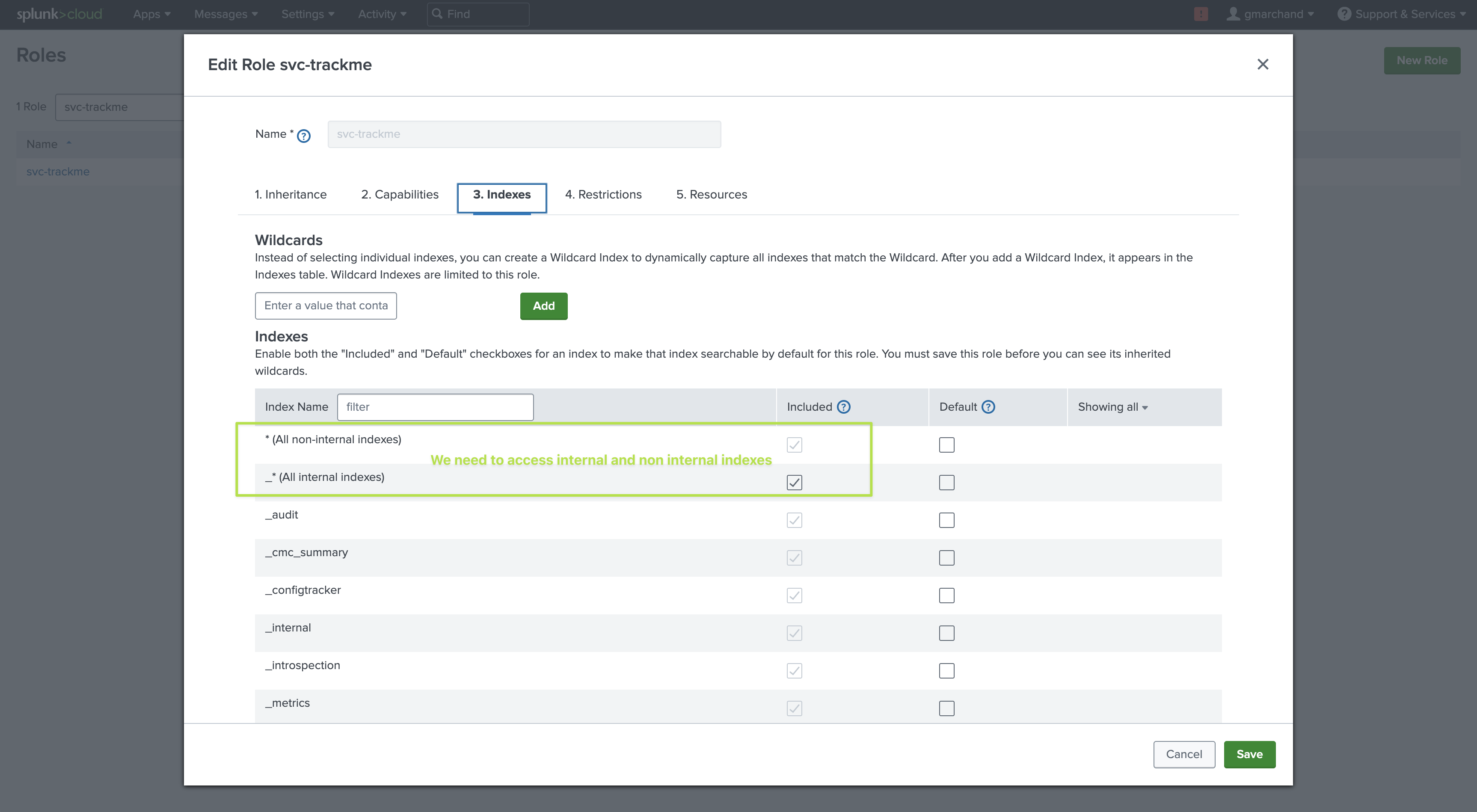
userrole out of the box role. (you can inherit from user or a role providing the same capabilities than power)Indexes: Make sure the user can access to both normal and
internalindexes.Restrictions: The user for TrackMe should not have any time limits restrictions, there are use cases which require long term searches.
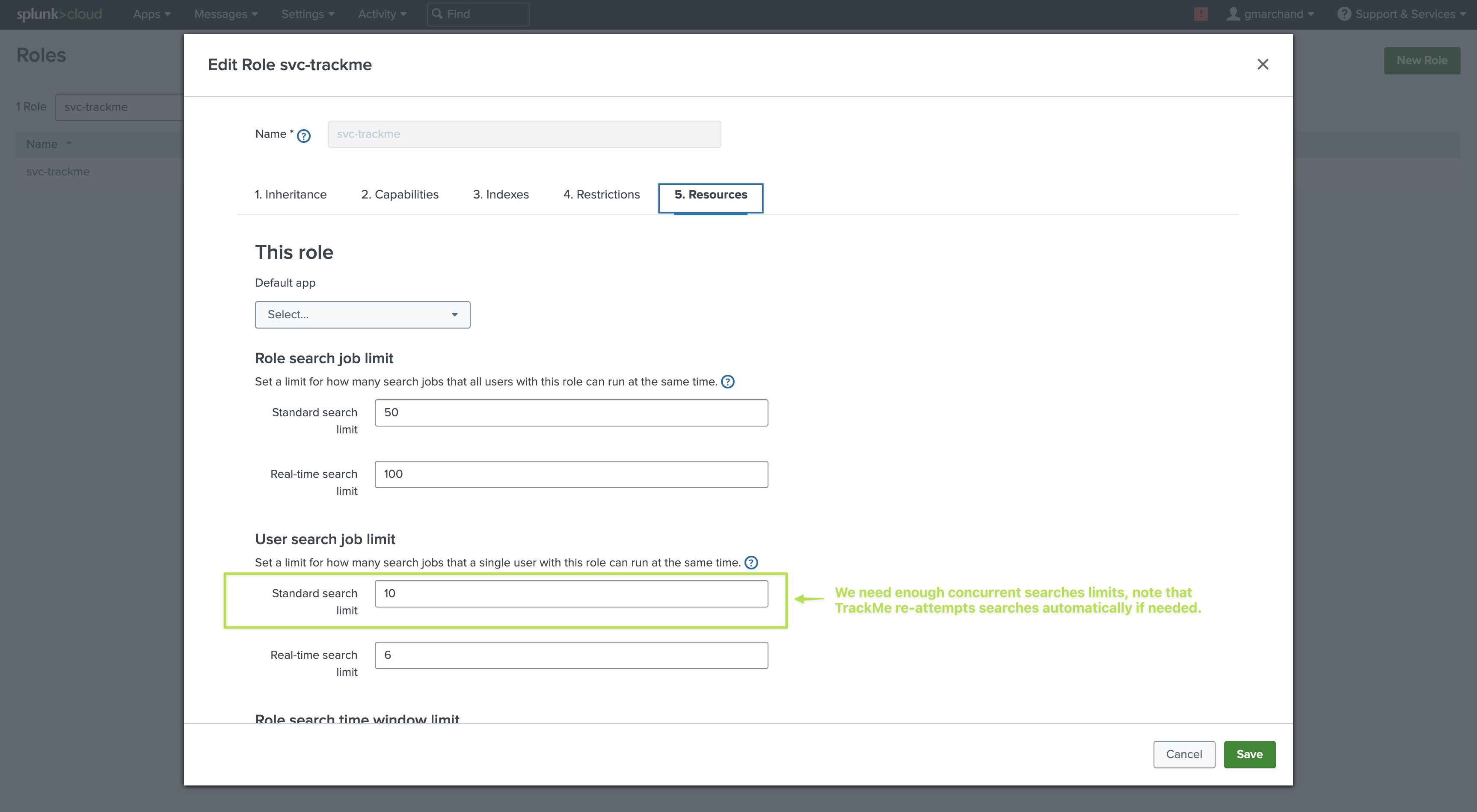
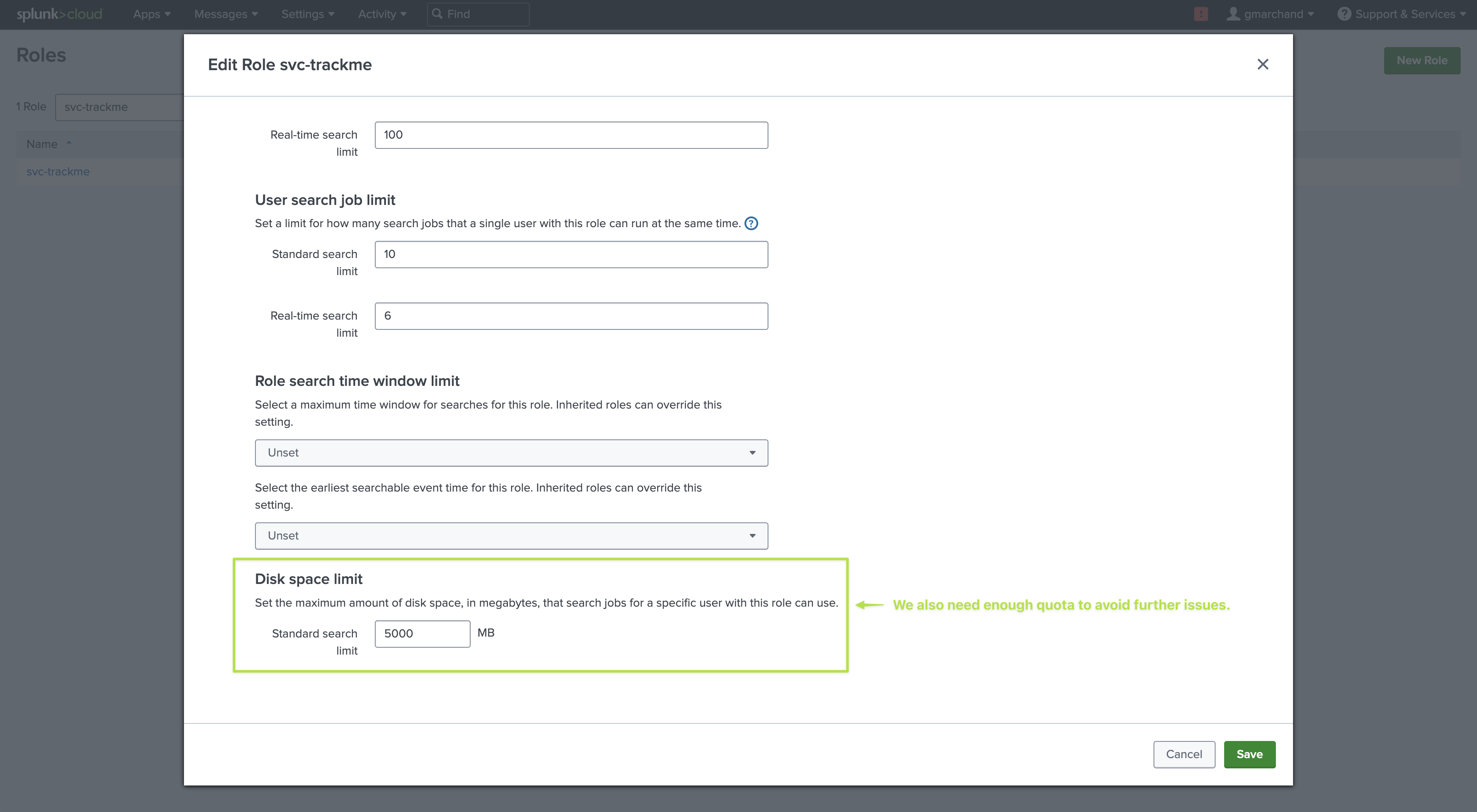
Resources: It is recommended to give to this user
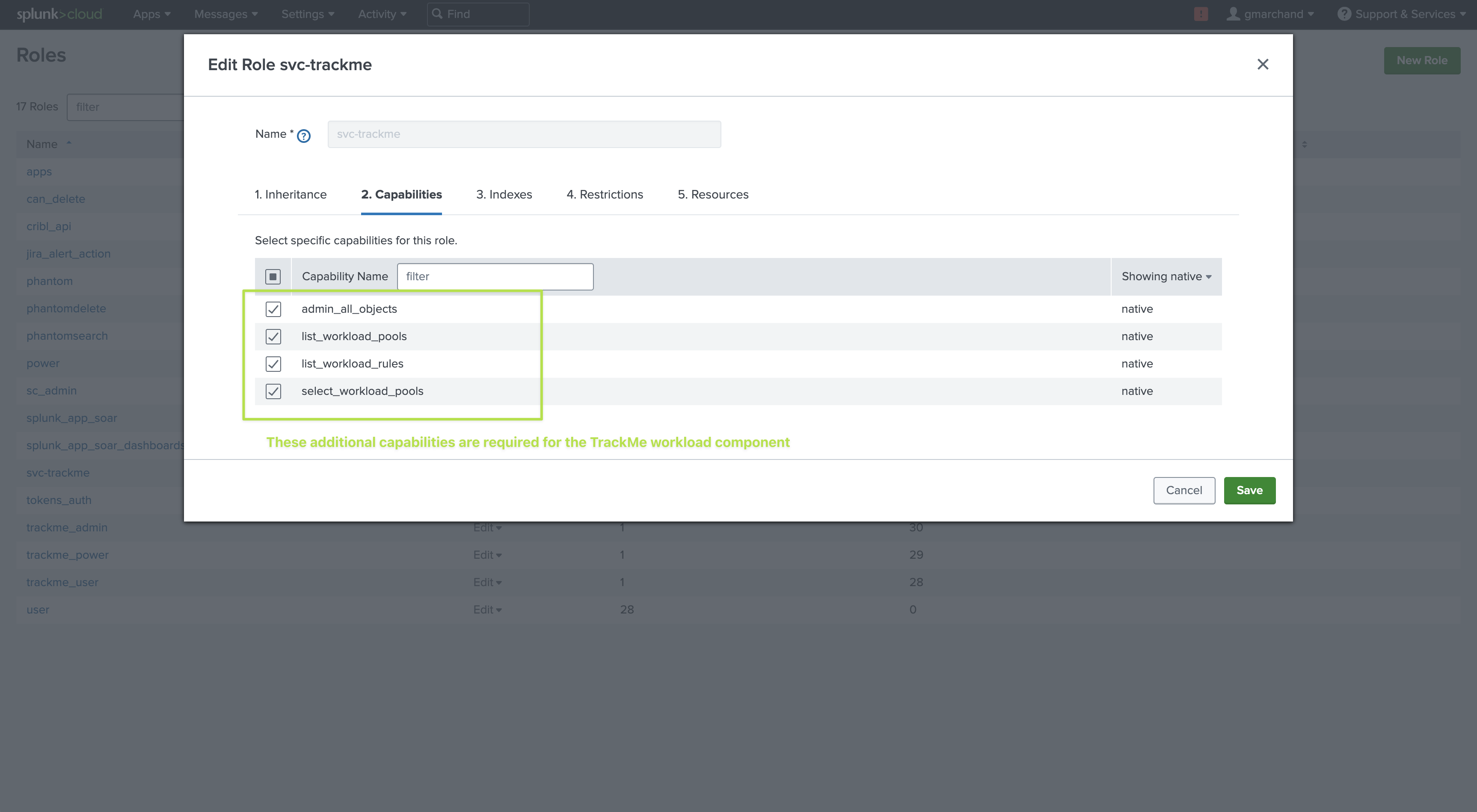
enough concurrent searches(unlike very basic or minimal user) as well as asufficient quota. (5GB or 10Gb for instance)Additional capability required: Finally, for the purposes of the Workload, this user also needs to have the following capabilities granted
admin_all_objects,select_workload_pool,list_workload_poolsandlist_workload_ruleswhich are required for TrackMe’s backend to access to all objects of all applications in a remote manner. (for the Metadata in the Workload component)
Capability |
Comment |
|---|---|
admin_all_objects |
Required |
select_workload_pool |
Required |
list_workload_pools |
Required |
list_workload_rules |
Required |
Users and roles
TrackMe is deeply RBAC capable, consult the following documentation to configure users accesses for TrackMe:
Web Browsers and system compatibility
TrackMe should work fine with most Web Browsers and systems; however, if you experience icon issues due to the lack of support of ASCII emojis, you can enable the Bootstrap compatibility mode:
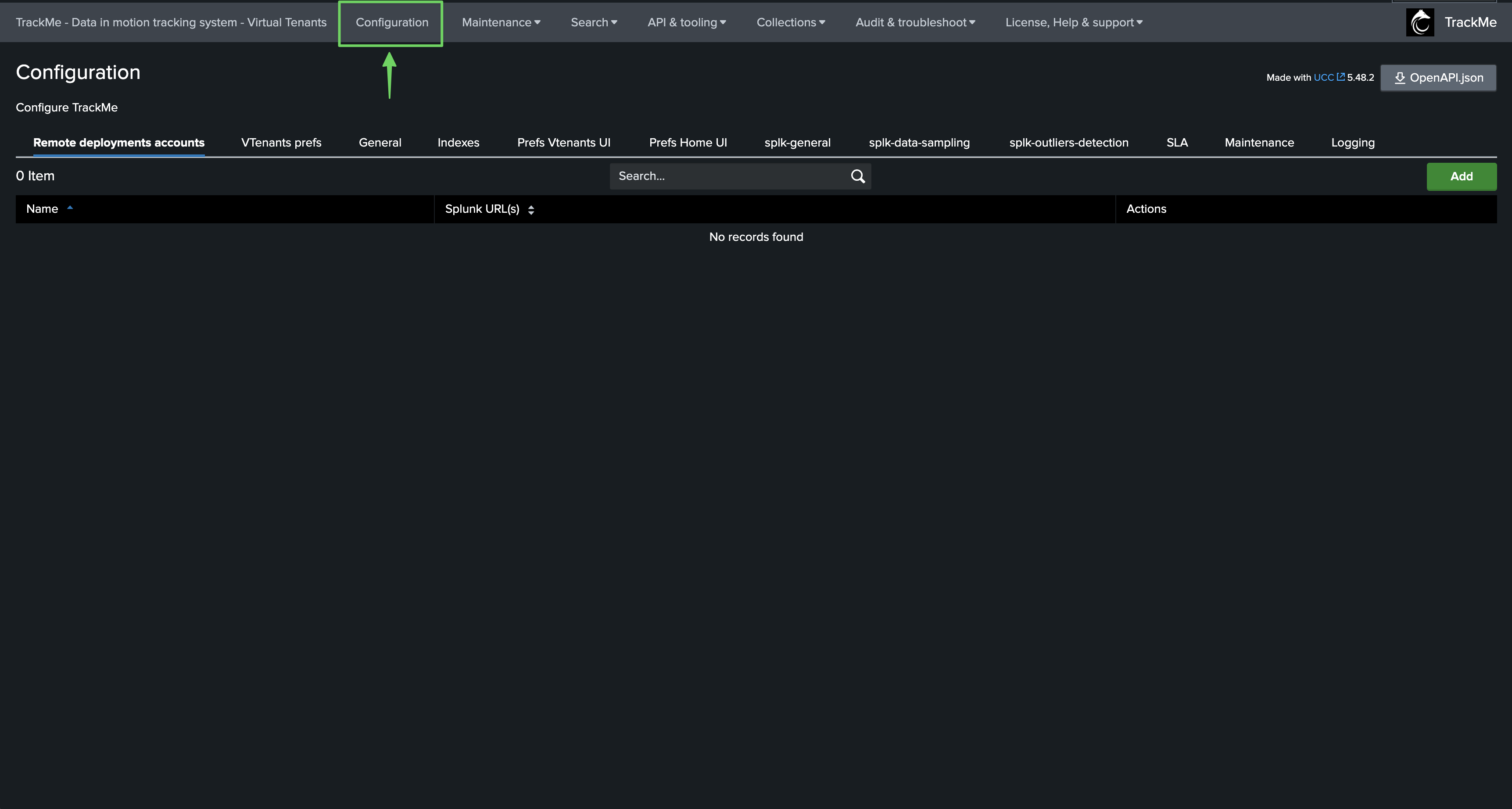
Accessing TrackMe Configuration
TrackMe relies on the Splunk UCC Framework for the purposes of the configuration level backend:
The Splunk UCC framework provides various powerful features which are leveraged notably for the purposes of handling the application-level configuration; for these purposes, a configuration user interface is available:
Default configurations are located in the following configuration file:
trackme/default/trackme_settings.conf
The configuration can therefore be performed via:
The configuration user interface: this creates a local/trackme_settings which is automatically replicated among the members when running in a Search Head Cluster
By deploying a local/trackme_settings.conf accordingly (if running in Search Head Cluster, this file would be located in shcluster/apps/trackme/local/trackme_settings)
However, the recommended method as a basis is to configure TrackMe through the intended configuration user interface.
Remote Splunk deployments accounts
The Splunk remote deployments accounts tab is where you will configure any remote Splunk environment you will monitor with TrackMe, if any,
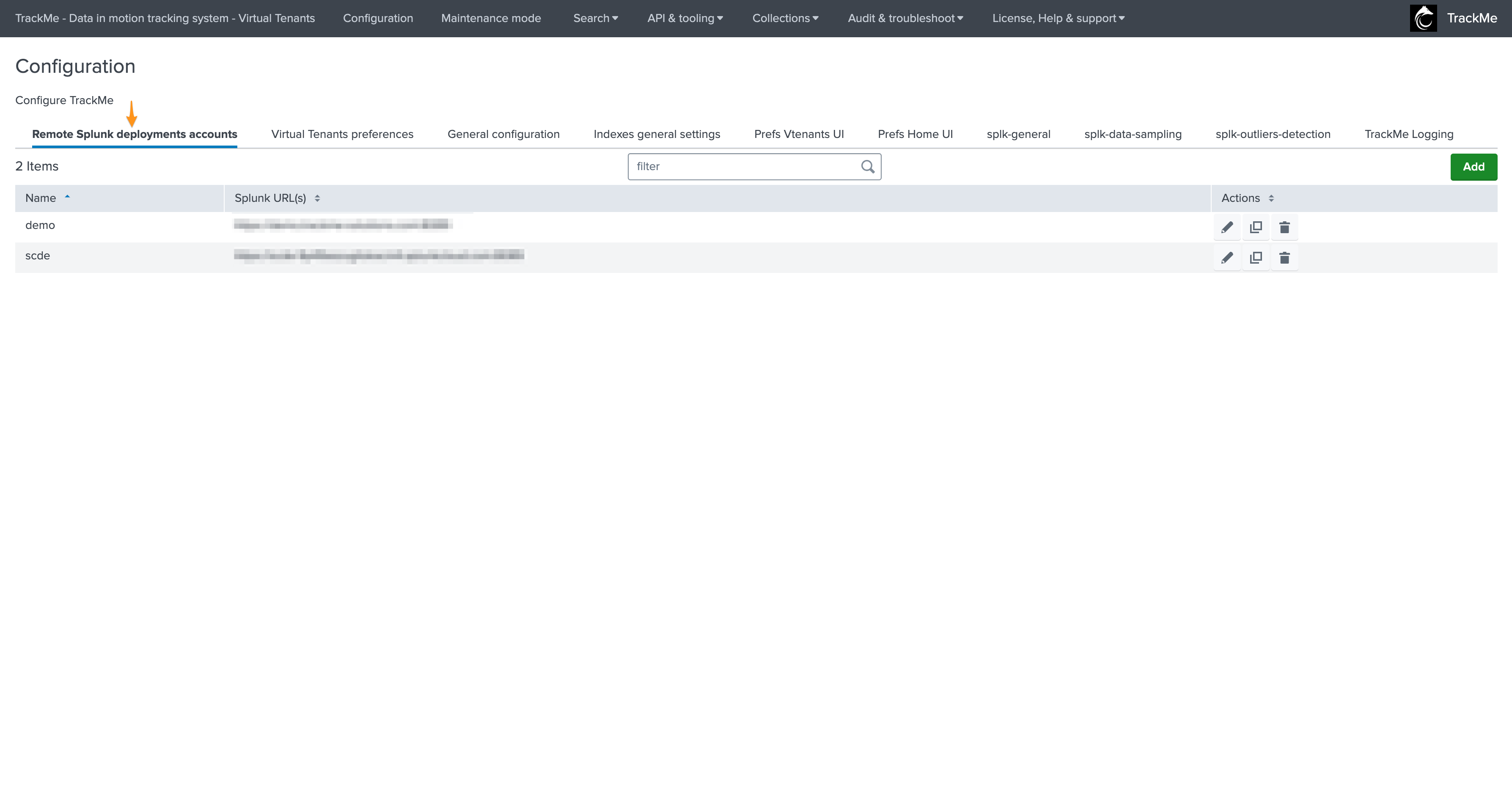
Splunk remote deployment accounts are documented here: Splunk Remote Deployments (splunkremotesearch)
Field |
Default Value |
Description |
|---|---|---|
name |
Enter a unique name for this Splunk remote environment. Must be 1 to 50 characters, begin with a letter, and consist of lower case alphanumeric characters and underscores. |
|
splunk_url |
A list of comma-separated targets, e.g., https://splunk1:8089,https://splunk2:8089 (SSL is enforced and URLs will be prefixed with https:// if not set). The URL can be based on IP or FQDN. |
|
bearer_token |
Set the bearer token used for remote access to the KVstore instance (client instances only). |
|
app_namespace |
search |
The Splunk application namespace on the remote system where searches will be executed. Defaults to the “search” app. |
rbac_roles |
admin,sc_admin,trackme_user,trackme_power,trackme_admin |
A comma-separated list of Splunk roles that are allowed to access this account, either by direct membership or inheritance. |
timeout_connect_check |
15 |
The maximal timeout value in seconds for the health check connection test. If the health check fails, the next target in the pool is used (if applicable). Defaults to 15 seconds. |
timeout_search_check |
600 |
The maximal timeout value in seconds for the remote search connection. Increase this value if the target responds slowly. Defaults to 600 seconds. |
token_rotation_enablement |
1 |
Automatically attempt to rotate the bearer token for this account based on the submitted frequency in days. This requires the account to have the edit_tokens_own capability. (Yes = 1, No = 0) |
token_rotation_frequency |
7 |
The frequency in days at which the bearer token should be rotated. Once this value is reached, TrackMe will attempt to rotate the token. Defaults to 7 days. |
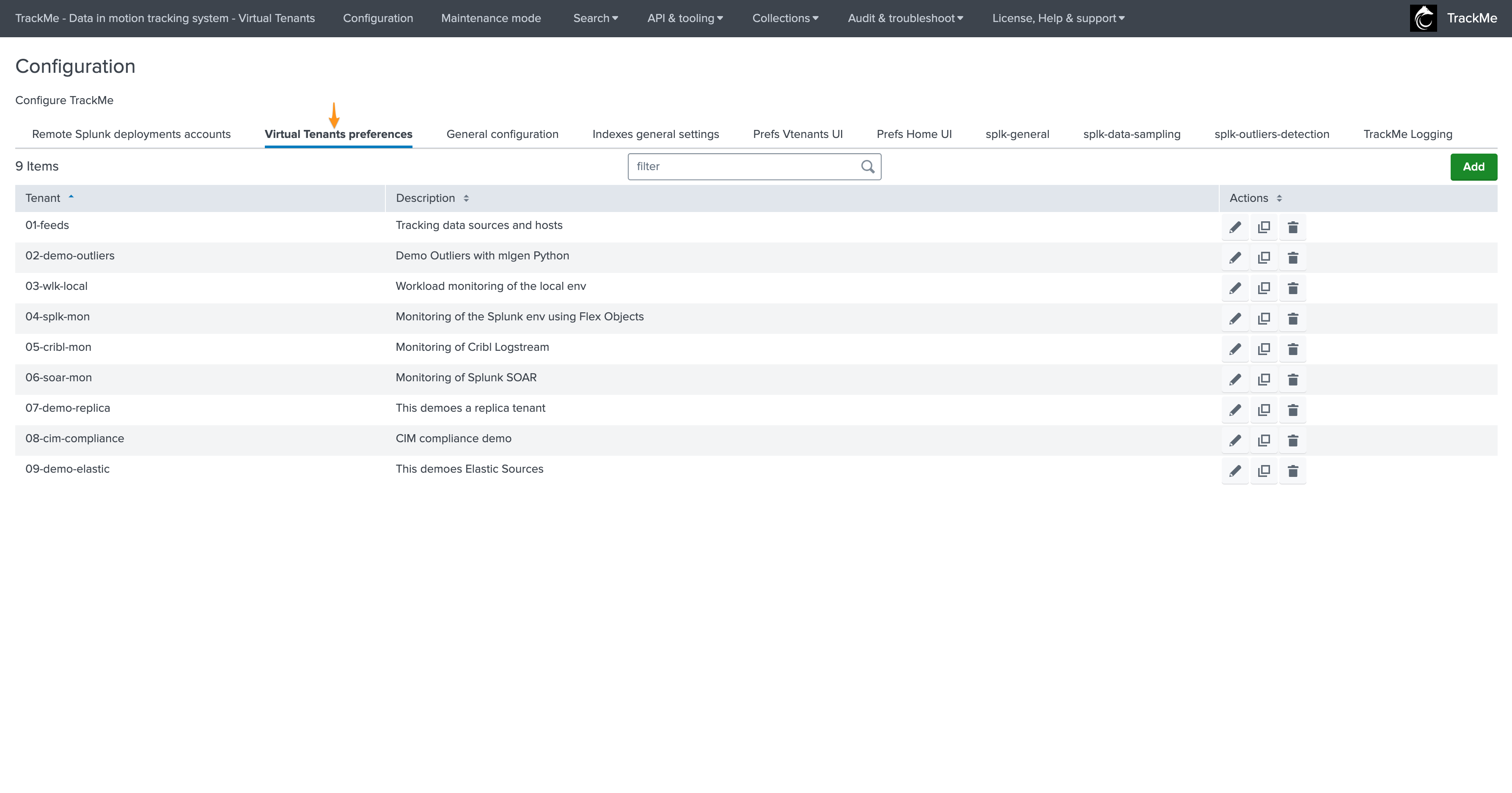
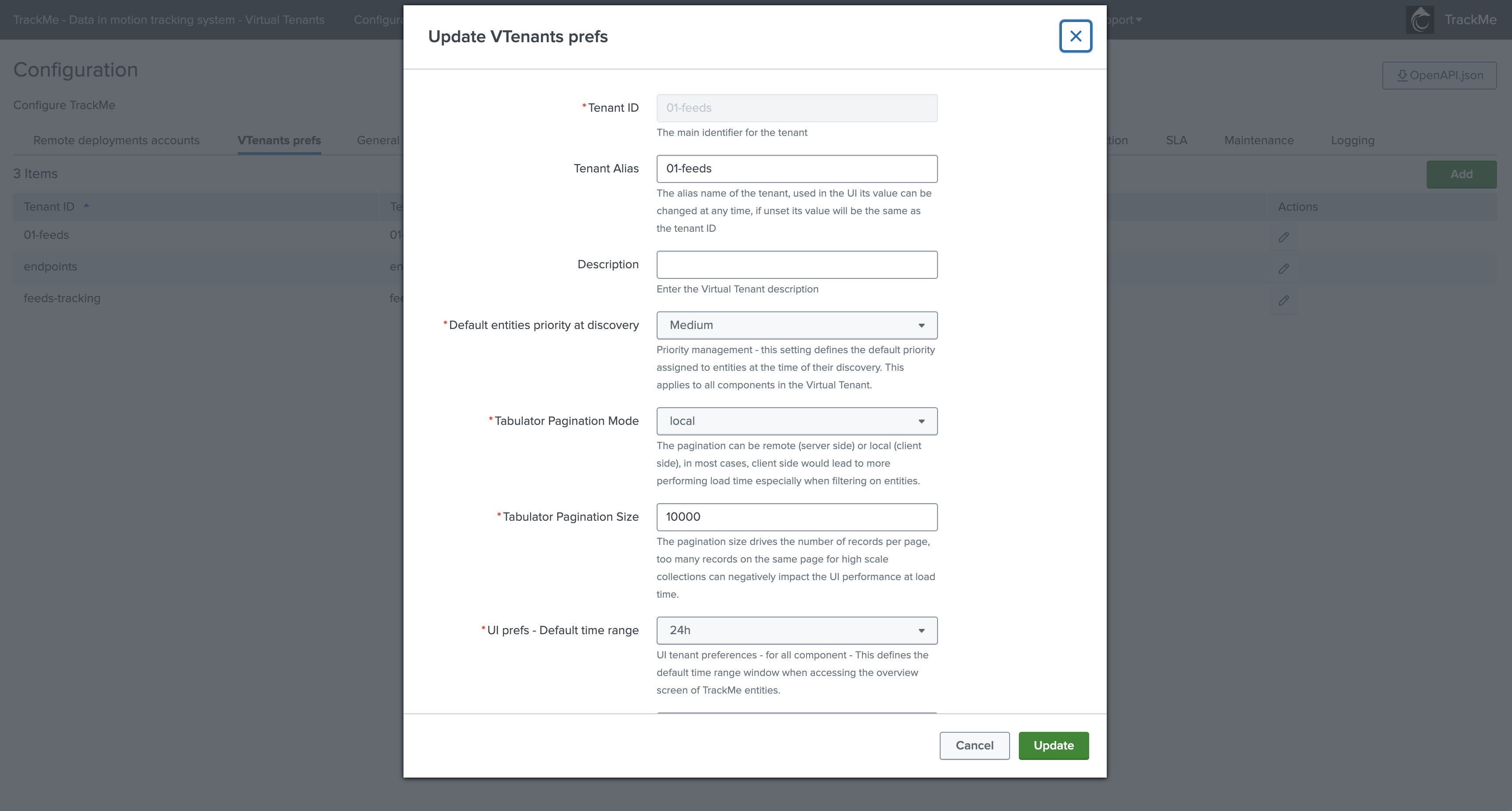
Virtual Tenants Accounts
Virtual Tenants Accounts are created and deleted automatically by TrackMe when managing Virtual Tenants through the Web or REST API; you can update the tenant-level configuration in this screen:
Field |
Label |
Default Value |
Description |
|---|---|---|---|
name |
Tenant ID |
The main identifier for the tenant (Tenant ID). Must only contain alphanumeric characters, hyphens, and underscores. |
|
alias |
Tenant Alias |
The alias name of the tenant, used in the UI. Its value can be changed at any time; if unset, it will default to the tenant ID. |
|
description |
Tenant Description |
A description of the virtual tenant, must be between 1 and 100 characters long. |
|
default_priority |
Default entities priority at discovery |
medium |
Defines the default priority assigned to entities at the time of their discovery (Critical, High, Medium, Low). |
pagination_mode |
Tabulator Pagination Mode |
local |
Defines pagination as either remote (server side) or local (client side). In most cases, client-side pagination improves performance. |
pagination_size |
Tabulator Pagination Size |
10000 |
Determines the number of records per page. Too many records per page may negatively impact UI performance. |
ui_default_timerange |
UI prefs - Default time range |
24h |
Defines the default time range for the tenant’s overview screen (options include 30m, 60m, 2h, etc.). |
ui_min_object_width |
UI prefs - Object min width |
300 |
Minimum width (in pixels) for the object field in the UI, to accommodate longer entity names. |
ui_expand_metrics |
UI prefs - expand metrics |
0 |
Whether to expand metrics information by default (Yes = 1, No = 0). |
ui_home_tabs_order |
UI prefs - Home tabs visibility and order |
dsm,flx,dhm,mhm,wlk,fqm,flip,audit,alerts |
List of tabs to be displayed in the Home UI in a comma-separated list. The order of the tabs is defined by the order in the list. |
default_disruption_min_time_sec |
Default minimal disruption period |
0 |
Defines the default minimal disruption period in seconds. If enabled with a positive value, this defines the minimal period of continuous disruption before the entity can transition to red state if in anomaly. Use 0 to disable the default period, which can also be set at the entity level. |
monitoring_time_policy |
Default monitoring time policy |
all_time |
The default monitoring time policy for this tenant. This is a string value that represents the monitoring time policy. Accepts: all_time, business_days_all_hours, monday_saturday_all_hours, business_days_08h_20h, monday_saturday_08h_20h or a JSON dictionary. |
outliers_set_state |
Red on Outliers |
1 |
Allows outliers to influence entity status (Yes = 1, No = 0). |
data_sampling_set_state |
Red on sampling |
1 |
For splk-dsm only: allows data sampling to influence entity status (Yes = 1, No = 0). |
data_sampling_obfuscation |
Sampling obfuscation |
0 |
For splk-dsm only: enables obfuscation of sampled events to avoid storing clear-text copies (Yes = 1, No = 0). |
adaptive_delay |
Adaptive delay |
1 |
Enables the adaptive delay feature, adjusting thresholds using Machine Learning and historical data (Yes = 1, No = 0). |
mloutliers |
Enable Machine Learning |
1 |
Enables ML-based outlier detection (Yes = 1, No = 0). |
mloutliers_allowlist |
Enable Machine Learning allowlist |
dsm,dhm,flx,wlk,fqm |
Comma separated list of components for which ML Outliers enablement applies. |
sampling |
Enable Data Sampling (spl-dsm only) |
1 |
Enables event and format recognition via data sampling for splk-dsm (Yes = 1, No = 0). |
splk_feeds_delayed_inspector_24hours_range_min_sec |
Delayed Inspector: 24 hours range min time between inspections |
14400 |
For splk-dsm/splk-dhm only, the minimum time in seconds between inspections for the 24 hours range delayed inspector. Defaults to 14400 seconds (4 hours). If set to 0, the delayed inspector will be disabled for that range. |
splk_feeds_delayed_inspector_7days_range_min_sec |
Delayed Inspector: 7 days range min time between inspections |
43200 |
For splk-dsm/splk-dhm only, the minimum time in seconds between inspections for the 7 days range delayed inspector. Defaults to 43200 seconds (12 hours). If set to 0, the delayed inspector will be disabled for that range. |
splk_feeds_delayed_inspector_until_disabled_range_min_sec |
Delayed Inspector: until disabled range min time between inspections |
172800 |
For splk-dsm/splk-dhm only, the minimum time in seconds between inspections for the until disabled range delayed inspector. Defaults to 172800 seconds (48 hours). If set to 0 or auto disablement period is set to 0d, the delayed inspector will be disabled for that range. |
splk_feeds_auto_disablement_period |
Auto disablement period |
60d |
Defines the period in relative days after which inactive entities (not sending data) get automatically disabled. Use 0d to disable this feature. |
indexed_constraint |
Global indexed fields constraint |
Defines a custom set of indexed fields used in auto-generated searches such as SmartStatus searches for this tenant. |
|
cmdb_lookup |
Enable CMDB integration |
1 |
Enables CMDB integration for the tenant (Yes = 1, No = 0). |
splk_dsm_cmdb_search |
CMDB lookup search splk-dsm |
If set, overrides the global config value. The CMDB lookup search for this component. You can refer using tokens to any field that TrackMe maintains in the KVstore collection. |
|
splk_dhm_cmdb_search |
CMDB lookup search splk-dhm |
If set, overrides the global config value. The CMDB lookup search for this component. You can refer using tokens to any field that TrackMe maintains in the KVstore collection. |
|
splk_mhm_cmdb_search |
CMDB lookup search splk-mhm |
If set, overrides the global config value. The CMDB lookup search for this component. You can refer using tokens to any field that TrackMe maintains in the KVstore collection. Use the token $tenant_id$ to make this search tenant specific. |
|
splk_flx_cmdb_search |
CMDB lookup search splk-flx |
If set, overrides the global config value. The CMDB lookup search for this component. You can refer using tokens to any field that TrackMe maintains in the KVstore collection. Use the token $tenant_id$ to make this search tenant specific. |
|
splk_fqm_cmdb_search |
CMDB lookup search splk-fqm |
If set, overrides the global config value. The CMDB lookup search for this component. You can refer using tokens to any field that TrackMe maintains in the KVstore collection. Use the token $tenant_id$ to make this search tenant specific. |
|
splk_wlk_cmdb_search |
CMDB lookup search splk-wlk |
If set, overrides the global config value. The CMDB lookup search for this component. You can refer using tokens to any field that TrackMe maintains in the KVstore collection. Use the token $tenant_id$ to make this search tenant specific. |
|
splk_dsm_tabulator_groupby |
splk-dsm Tabulator GroupBy |
data_index |
Tabulator GroupBy configuration for splk-dsm, defaulting to data_index. Can also include multiple levels like data_index,priority. |
splk_dhm_tabulator_groupby |
splk-dhm Tabulator GroupBy |
tenant_id |
Tabulator GroupBy configuration for splk-dhm, defaulting to tenant_id. |
splk_mhm_tabulator_groupby |
splk-mhm Tabulator GroupBy |
tenant_id |
Tabulator GroupBy configuration for splk-mhm, defaulting to tenant_id. |
splk_flx_tabulator_groupby |
splk-flx Tabulator GroupBy |
group |
Tabulator GroupBy configuration for splk-flx, defaulting to group. |
splk_fqm_tabulator_groupby |
splk-fqm Tabulator GroupBy |
metadata_datamodel,metadata_index,metadata_sourcetype |
Tabulator GroupBy configuration for splk-fqm, defaulting to metadata_datamodel,metadata_index,metadata_sourcetype. |
splk_wlk_tabulator_groupby |
splk-wlk Tabulator GroupBy |
overgroup |
Tabulator GroupBy configuration for splk-wlk, defaulting to overgroup. |
General
This tab defines various general configuration:
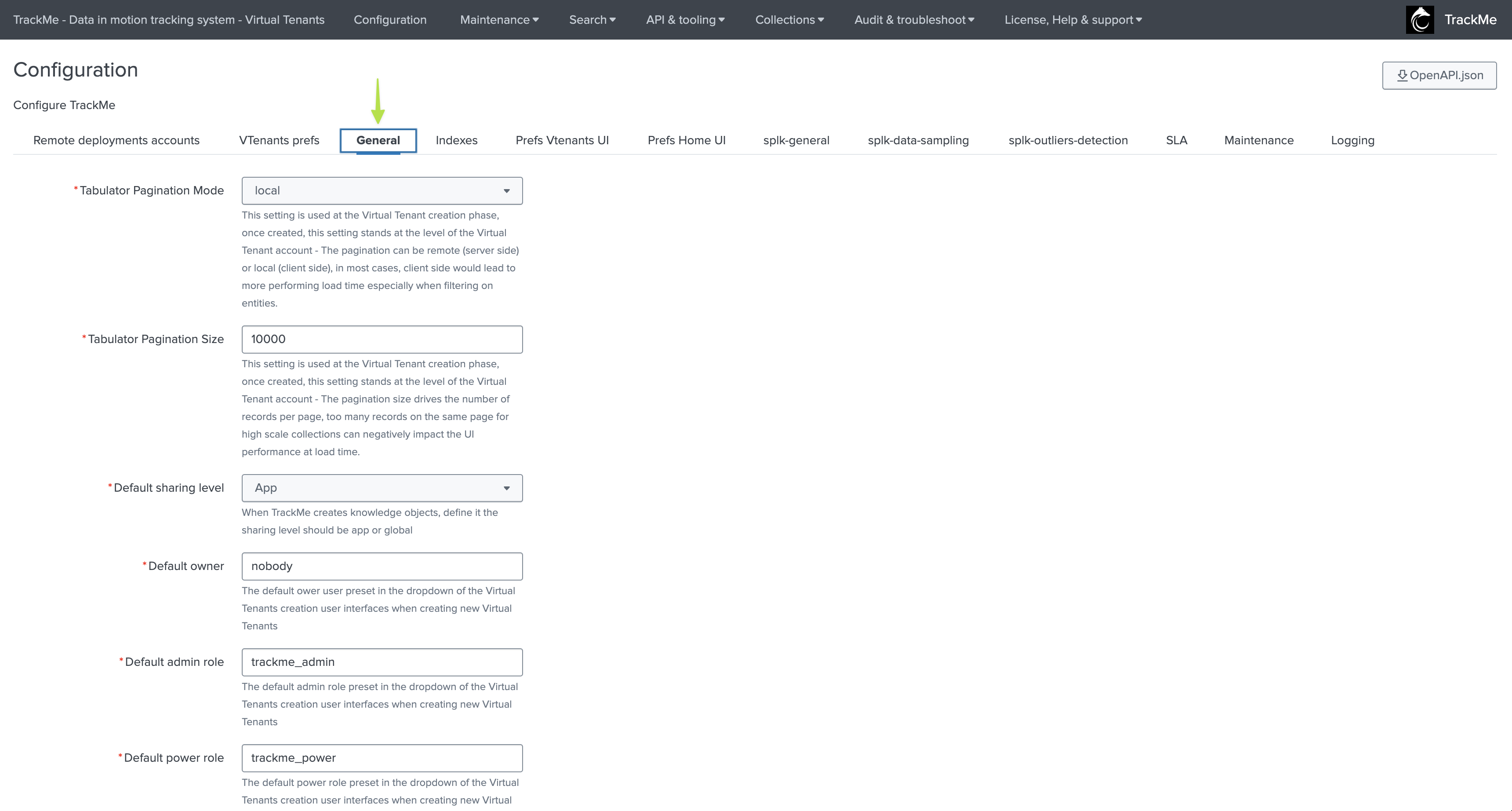
Field |
Label |
Default Value |
Description |
|---|---|---|---|
max_multi_thread_workers |
Max multi thread workers |
16 |
For backends that use multi threading such as trackmepersistentfields, this setting defines the maximum number of workers that can be used to process the data in parallel. The number of workers is calculated based on the number of CPU cores available on the system and capped at this value. (formula: max_workers = cpu_cores * 2, but never more than this value) - Set to 1 to disable multi threading. |
pagination_mode |
Tabulator Pagination Mode |
local |
This setting is used at the Virtual Tenant creation phase. Once created, this setting stands at the level of the Virtual Tenant account. Pagination can be remote (server-side) or local (client-side), with client-side offering better performance in most cases. |
pagination_size |
Tabulator Pagination Size |
10000 |
Drives the number of records per page. Too many records can negatively impact the UI performance. |
trackme_default_sharing |
Default sharing level |
app |
Defines whether knowledge objects should be shared at the app or global level when created. |
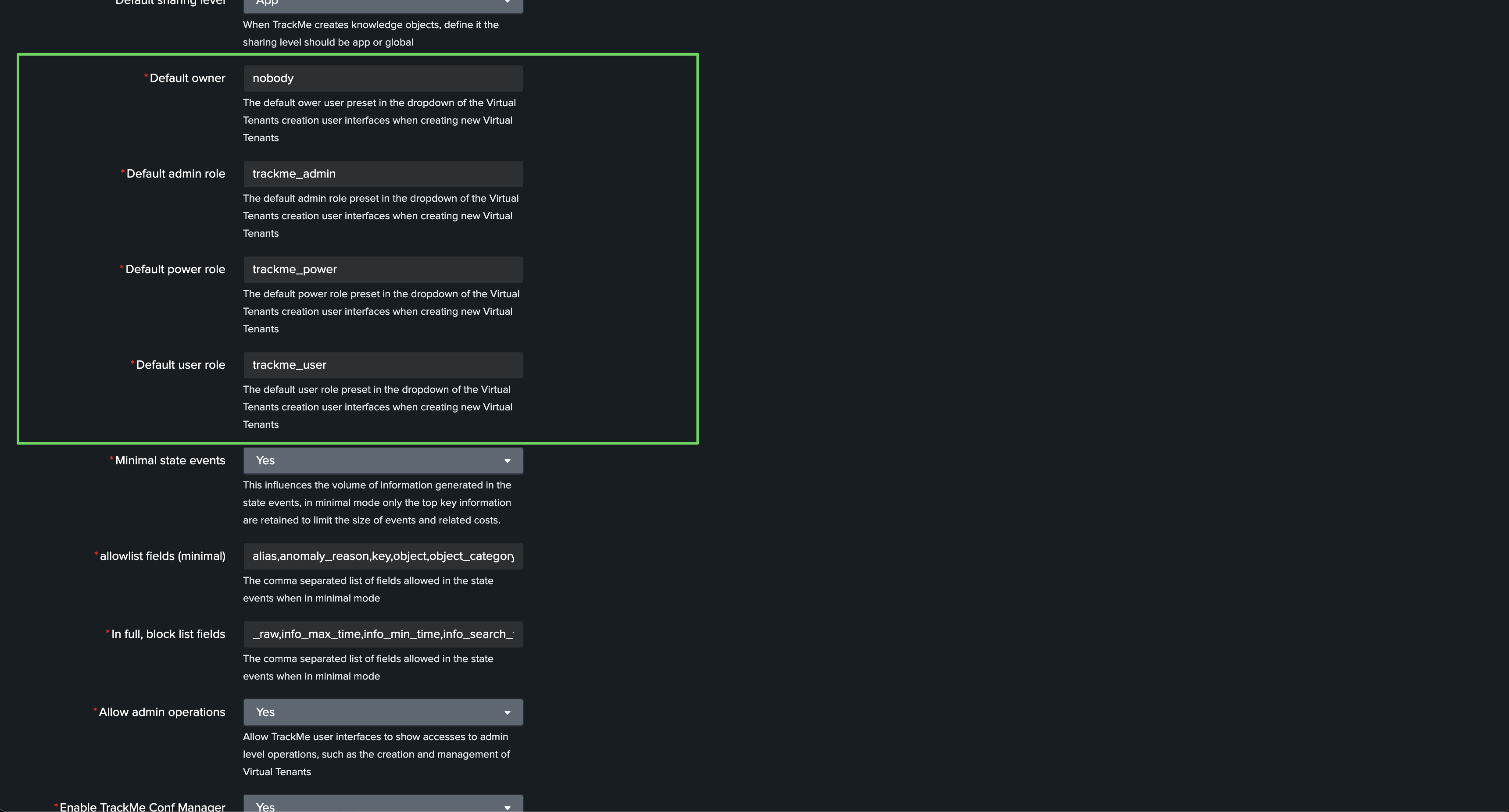
trackme_owner_default |
Default owner |
admin |
The default owner user preset in the dropdown of the Virtual Tenants creation UI. |
trackme_admin_role_default |
Default admin role |
trackme_admin |
The default admin role preset in the dropdown of the Virtual Tenants creation UI. |
trackme_power_role_default |
Default power role |
trackme_power |
The default power role preset in the dropdown of the Virtual Tenants creation UI. |
trackme_user_role_default |
Default user role |
trackme_power |
The default user role preset in the dropdown of the Virtual Tenants creation UI. |
state_events_minimal |
Minimal state events |
1 |
Influences the volume of information in state events. In minimal mode, only key information is retained to limit size and costs. |
state_events_allowlist |
Allowlist fields (minimal) |
alias,anomaly_reason,keyid,object,object_category,priority,state,status_message,tags,tenant_id |
Comma-separated list of fields allowed in state events when in minimal mode. |
state_events_blocklist |
Blocklist fields (full mode) |
_raw,info_max_time,info_min_time,info_search_time,info_sid,splk_dhm_st_summary,splk_dhm_st_summary_compact,splk_dhm_st_summary_full,metric_details,object_state,tracker_runtime,previous_tracker_runtime |
Comma-separated list of fields blocked in state events when in full mode. |
enable_conf_manager_receiver |
Enable TrackMe Conf Manager |
0 |
Enables the TrackMe conf manager receiver, allowing admin-level operations to be sent to the receiver for replay in the target environment. |
trackme_stateful_records_expiration_days |
StateFul closed records expiration |
30 |
The number of days after which closed records in the StateFul KVstore collections are expired and deleted. |
trackme_stateful_charts_records_expiration_days |
StateFul charts records expiration |
2 |
The number of days after which charts records in the StateFul KVstore collections are expired and deleted (charts records do not need to be preserved for a long time). |
trackme_ack_duration_default |
Default Ack duration |
86400 |
Default duration (in seconds) for the acknowledgment action for entities in alert. |
trackme_ack_remove_on_reason_change |
Expire Ack on anomaly reason change |
1 |
Automatically removes an Ack when the anomaly reason changes. |
trackme_ack_remove_on_reason_change_min_time_sec |
Expire Ack on anomaly reason change min time |
3600 |
Minimum time in seconds between the creation of an Ack and its expiration due to an anomaly reason change. |
trackme_ack_remove_on_reason_change_auto_ack_only |
Expire Ack on anomaly reason change (auto Ack only) |
1 |
Restricts Ack expiration due to anomaly changes to automatic Acks only. User Acks are not impacted. |
trackme_ack_remove_when_green |
Remove Ack on green state |
1 |
Automatically removes an Ack when the entity returns to green state, unless sticky Ack is enabled. |
Indexes general settings
This tab defines the indexes by default for Virtual Tenants:
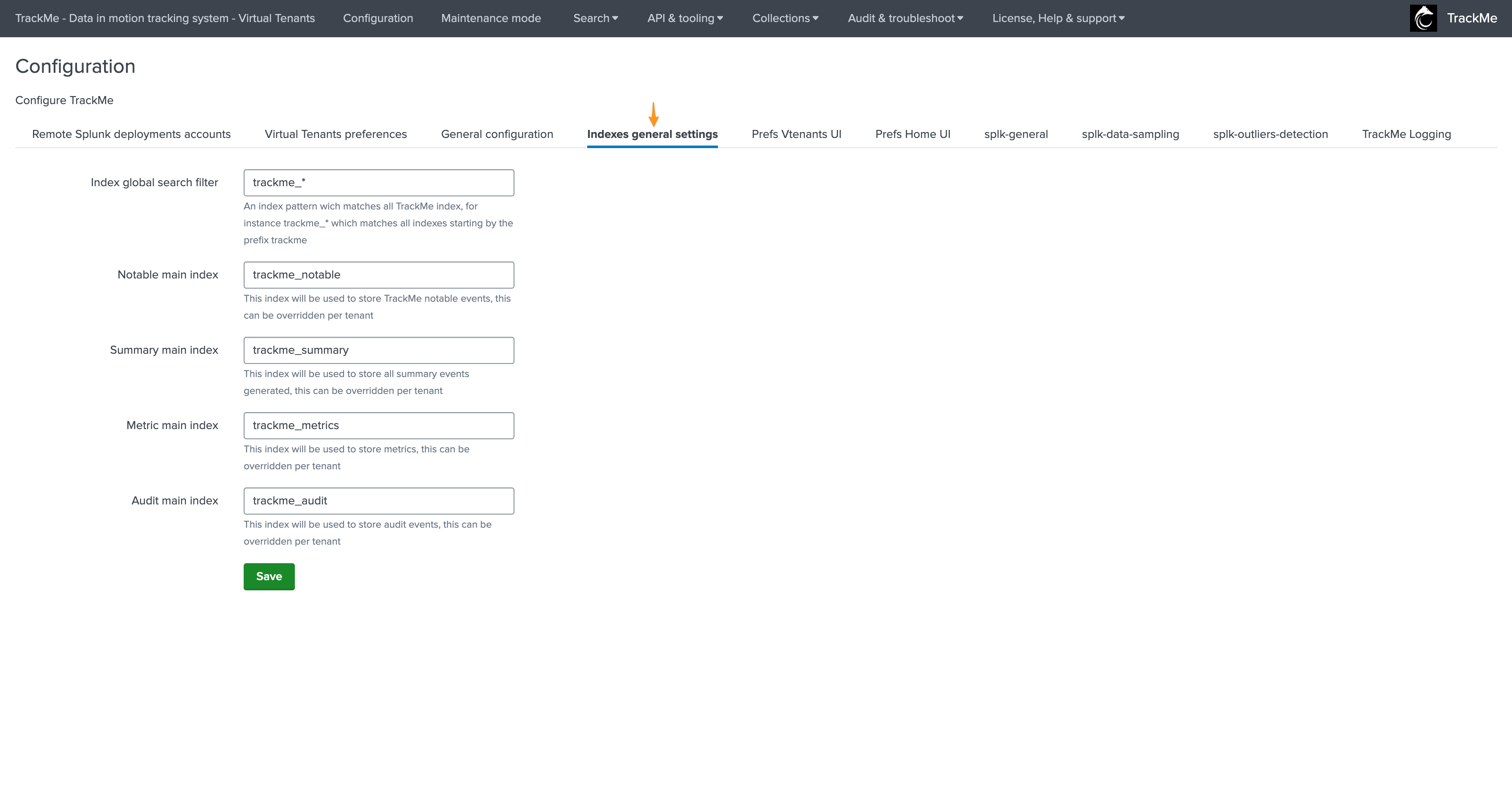
If you intend to create Virtual Tenants specific indexes, we strongly recommend using a prefix pattern as a strict convention, for instance:
trackme_<context>_<index name>
Field |
Default Value |
Description |
|---|---|---|
trackme_idx_search_filter |
trackme_* |
An index pattern which matches all TrackMe index, for instance |
trackme_notable_idx |
trackme_notable |
This index will be used to store TrackMe notable events, this can be overridden per tenant |
trackme_summary_idx |
trackme_summary |
This index will be used to store all summary events generated, this can be overridden per tenant |
trackme_metric_idx |
trackme_metrics |
This index will be used to store metrics, this can be overridden per tenant |
trackme_audit_idx |
trackme_audit |
This index will be used to store audit events, this can be overridden per tenant |
splk-general
This tab defines various options specific to Splunk:
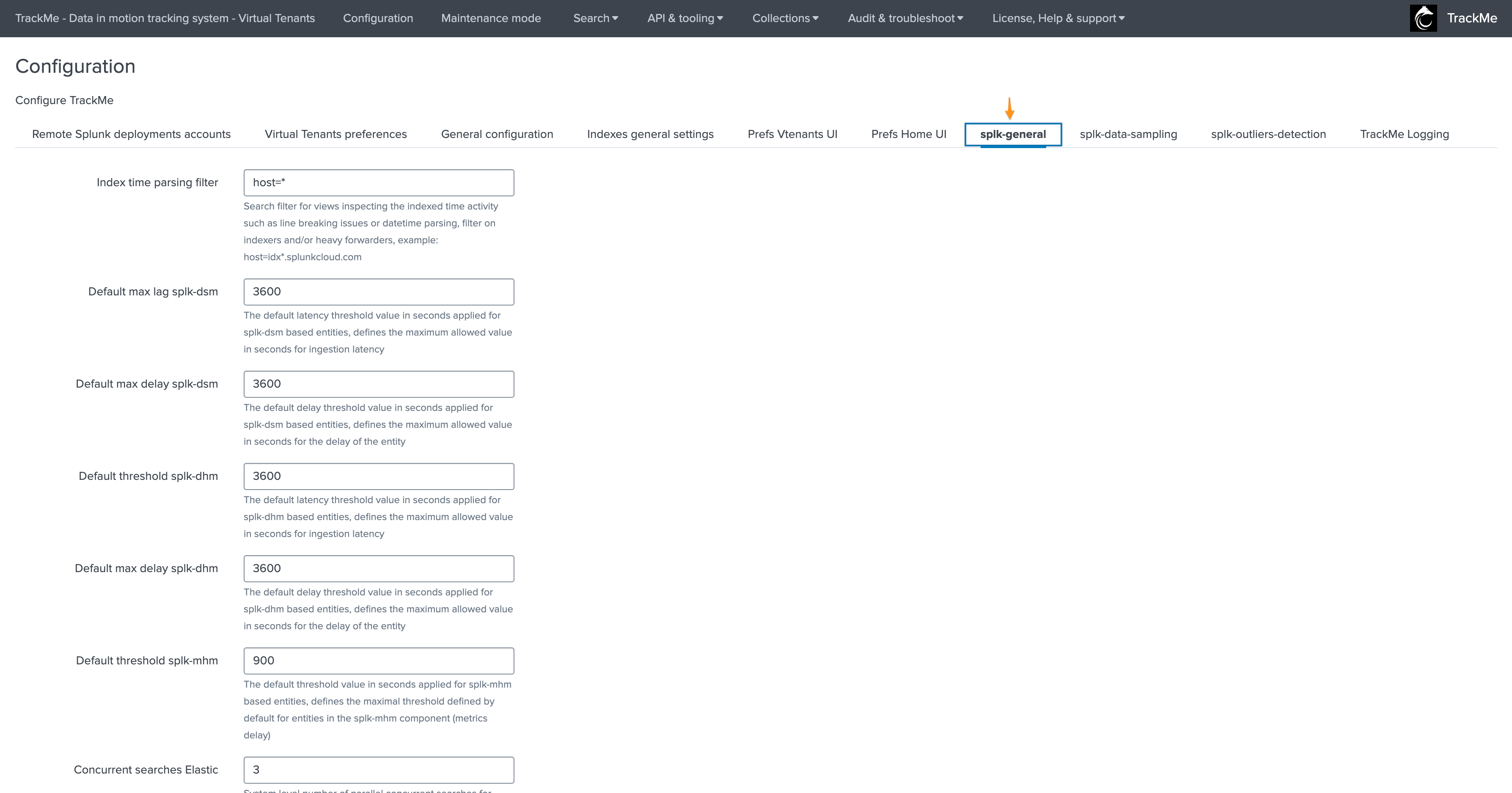
Field |
Label |
Default Value |
Description |
|---|---|---|---|
splk_general_idx_filter |
Index time parsing filter |
host=* |
Search filter for views inspecting indexed time activity such as line breaking issues or datetime parsing. Filter on indexers and/or heavy forwarders, example: host=idx*.splunkcloud.com. |
splk_general_dsm_threshold_default |
Latency default (splk-dsm) |
3600 |
The default latency threshold value in seconds applied for splk-dsm based entities. Defines the maximum allowed value for ingestion latency. |
splk_general_dsm_delay_default |
Delay default (splk-dsm) |
3600 |
The default delay threshold value in seconds for splk-dsm based entities. Defines the maximum allowed delay for entities. |
splk_general_dhm_threshold_default |
Latency default (splk-dhm) |
3600 |
The default latency threshold value in seconds applied for splk-dhm based entities. Defines the maximum allowed value for ingestion latency. |
splk_general_dhm_delay_default |
Delay default (splk-dhm) |
86400 |
The default delay threshold value in seconds for splk-dhm based entities. Defines the maximum allowed delay for entities. |
splk_general_mhm_threshold_default |
Delay default (splk-mhm) |
900 |
The default threshold value in seconds for splk-mhm based entities, defining the maximum metrics delay. |
splk_general_feeds_future_tolerance |
Future indexing tolerance (splk-dsm/splk-dhm) |
-600 |
For splk-dsm/splk-dhm only, defines the negative amount of time (in seconds) used for tolerance before data is assumed to be indexed in the future. |
splk_general_feeds_delayed_inspector_24hours_range_min_sec |
Delayed Inspector: 24 hours range min time between inspections |
14400 |
For splk-dsm/splk-dhm only, the minimum time in seconds between inspections for the 24 hours range delayed inspector. Defaults to 14400 seconds (4 hours). If set to 0, the delayed inspector will be disabled for that range. |
splk_general_feeds_delayed_inspector_7days_range_min_sec |
Delayed Inspector: 7 days range min time between inspections |
43200 |
For splk-dsm/splk-dhm only, the minimum time in seconds between inspections for the 7 days range delayed inspector. Defaults to 43200 seconds (12 hours). If set to 0, the delayed inspector will be disabled for that range. |
splk_general_feeds_delayed_inspector_until_disabled_range_min_sec |
Delayed Inspector: until disabled range min time between inspections |
172800 |
For splk-dsm/splk-dhm only, the minimum time in seconds between inspections for the until disabled range delayed inspector. Defaults to 172800 seconds (48 hours). If set to 0 or auto disablement period is set to 0d, the delayed inspector will be disabled for that range. |
splk_general_feeds_auto_disablement_period |
Auto disablement period (splk-dsm/splk-dhm/splk-mhm) |
60d |
For splk-dsm/splk-dhm/splk-mhm only, defines the period in days after which inactive entities get automatically disabled. Set to 0d to disable this feature. |
splk_general_elastic_max_concurrent |
Concurrent searches Elastic |
3 |
Defines the number of parallel concurrent searches for Shared Elastic sources at the system level. This can be overridden per tenant using max_concurrent_searches. |
splk_general_workload_version_id_keys |
Workload version_id calculation parameters keys |
search,dispatch.earliest,dispatch.latest,description,cron_schedule,disabled,is_scheduled |
For the Workload component (splk-wlk), defines the list of parameters used for the version_id hash calculation (versioning), expected as a CSV list of saved searches parameters, wildcard patterns are supported. Note that changing this value leads to the re-calculation of all known object version_id values. |
splk_general_dsm_cmdb_search |
CMDB lookup search splk-dsm |
inputlookup my_cmdb where (index="$data_index$" AND sourcetype="$data_sourcetype$")
|
Defines the CMDB lookup search for splk-dsm. You can use tokens for any field maintained in the KVstore collection. |
splk_general_dhm_cmdb_search |
CMDB lookup search splk-dhm |
inputlookup my_cmdb where (host="$alias$")
|
Defines the CMDB lookup search for splk-dhm. You can use tokens for any field maintained in the KVstore collection. |
splk_general_mhm_cmdb_search |
CMDB lookup search splk-mhm |
inputlookup my_cmdb where (host="$alias$")
|
Defines the CMDB lookup search for splk-mhm. Tokens like $tenant_id$ can make the search tenant-specific. |
splk_general_flx_cmdb_search |
CMDB lookup search splk-flx |
inputlookup my_cmdb where (object="$object$")
|
Defines the CMDB lookup search for splk-flx. Tokens like $tenant_id$ can make the search tenant-specific. |
splk_general_fqm_cmdb_search |
CMDB lookup search splk-fqm |
inputlookup my_cmdb where (object="$object$")
|
Defines the CMDB lookup search for splk-fqm. Tokens like $tenant_id$ can make the search tenant-specific. |
splk_general_wlk_cmdb_search |
CMDB lookup search splk-wlk |
inputlookup my_cmdb where (savedsearch_name="$savedsearch_name$")
|
Defines the CMDB lookup search for splk-wlk. Tokens like $tenant_id$ can make the search tenant-specific. |
splk_general_dsm_docs_note_global |
splk-dsm docs note global |
No default value |
Defines a global default documentation note per entity for splk-dsm. This can still be overridden on a per-entity basis. |
splk_general_dsm_docs_link_global |
splk-dsm docs link global |
No default value |
Defines a global default documentation link per entity for splk-dsm. This can still be overridden on a per-entity basis. |
splk-data-sampling
This tab defines various options specific to the Data Sampling feature for splk-dsm (splk-feeds):
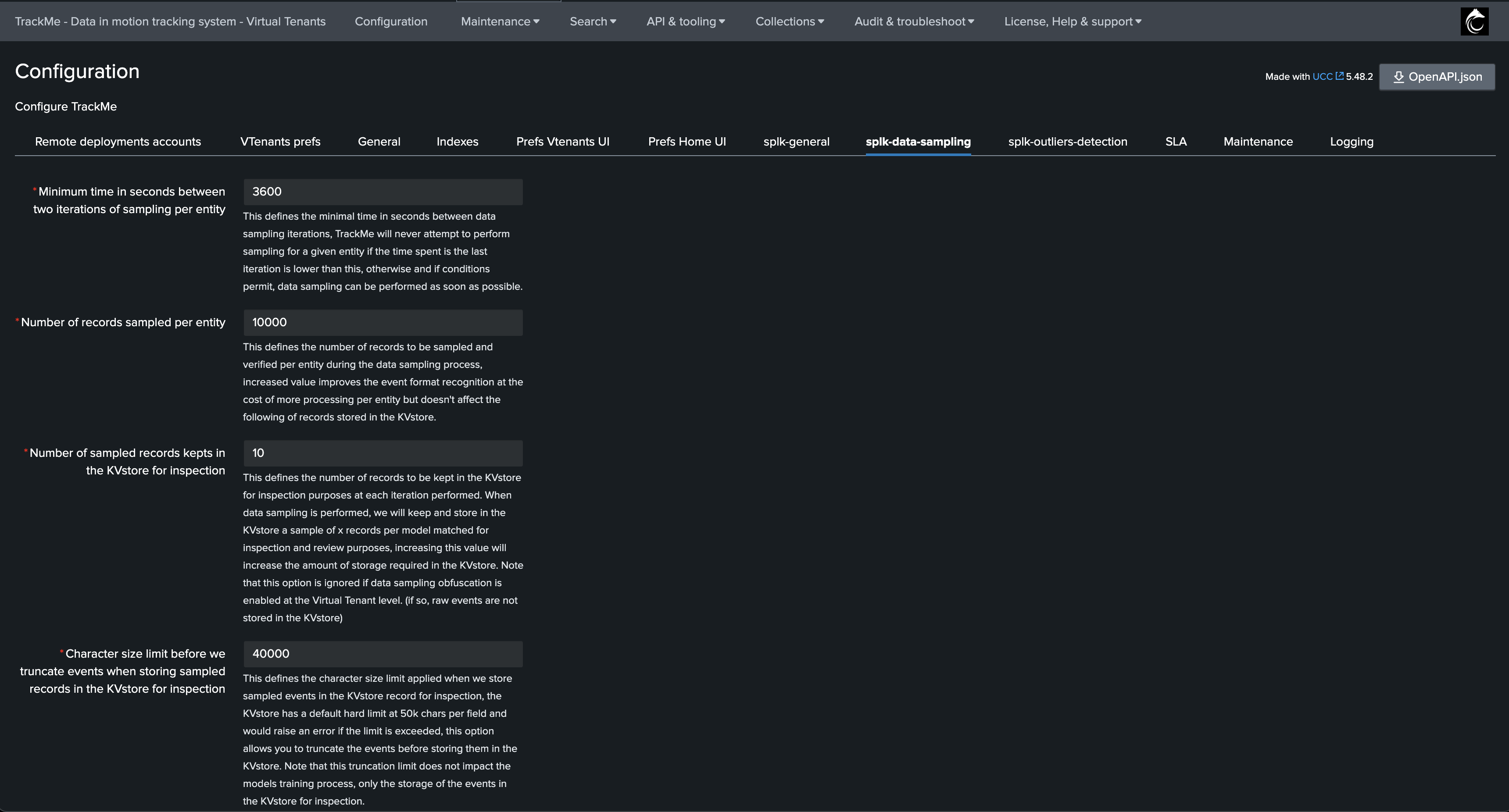
Field |
Default Value |
Description |
|---|---|---|
splk_data_sampling_min_time_btw_iterations_seconds |
3600 |
Defines the minimal time in seconds between two iterations of sampling per entity. TrackMe will not attempt to perform sampling for a given entity if the time since the last iteration is lower than this value. |
splk_data_sampling_no_records_per_entity |
10000 |
Number of records to be sampled and verified per entity during the data sampling process. Increased value improves event format recognition but requires more processing. |
splk_data_sampling_no_records_saved_kvrecord |
10 |
Defines the number of records to be stored in the KVstore for inspection purposes at each iteration. This value can be increased if more storage space is available. |
splk_data_sampling_records_kvrecord_truncate_size |
40000 |
Character size limit before truncating events when storing sampled records in the KVstore for inspection. This truncation does not impact the model training process, only storage. |
splk_data_sampling_pct_min_major_inclusive_model_match |
98 |
Minimum percentage of events that must match the major inclusive model. If the main model has less than this percentage of events matching, the entity’s state will be impacted. |
splk_data_sampling_pct_max_exclusive_model_match |
95 |
Maximum percentage of events matching an exclusive model that can be accepted. By default, no events matching an exclusive model are accepted, but this value can be increased. |
splk_data_sampling_relative_time_window_seconds |
3600 |
Size of the time window for the sampling operation, in seconds, relative to the latest event time known for the entity. This window is used to calculate the earliest time for sampling searches. |
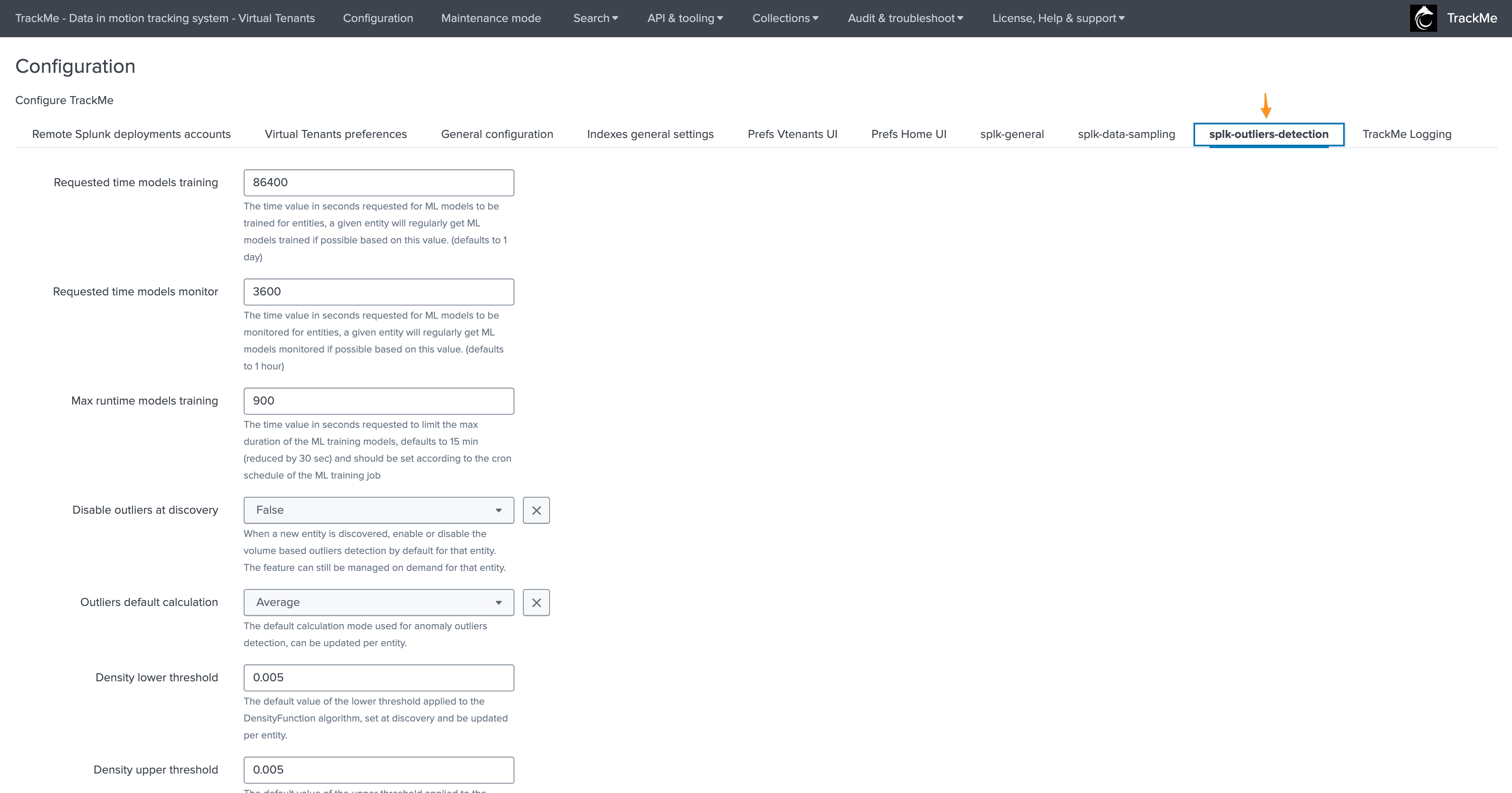
splk-outliers-detection
This tab defines various options specific to the Machine Outliers detection features:
Field |
Label |
Default Value |
Description |
|---|---|---|---|
splk_outliers_min_days_history |
Min days historical metrics for confidence |
7 |
The minimal number of days of historical metrics required to compute the confidence level of the outliers detection, defaults to 7 days. |
splk_outliers_time_train_mlmodels_default |
Requested time models training |
604800 |
The time value in seconds requested for ML models to be trained for entities; a given entity will regularly get ML models trained if possible based on this value. (defaults to 7 days) |
splk_outliers_time_monitor_mlmodels_default |
Requested time models monitor |
3600 |
The time value in seconds requested for ML models to be monitored for entities; a given entity will regularly get ML models monitored if possible based on this value. (defaults to 1 hour) |
splk_outliers_max_runtime_train_mlmodels_default |
Max runtime models training |
900 |
The time value in seconds requested to limit the max duration of the ML training models, defaults to 15 min (reduced by 30 sec) and should be set according to the cron schedule of the ML training job. |
splk_outliers_max_days_since_last_train_default |
Max time since last training |
15 |
When executing a rendering operation, TrackMe verifies the last time this model was trained. If this time exceeds the value set here, the model will be retrained automatically before rendering. (defaults to 15 days) |
splk_outliers_detection_disable_default |
Disable outliers at discovery |
0 |
When a new entity is discovered, enable or disable the volume-based outliers detection by default for that entity. The feature can still be managed on demand for that entity. |
splk_outliers_calculation_default |
Outliers default calculation |
stdev |
The default calculation mode used for anomaly outliers detection, can be updated per entity. |
splk_outliers_density_lower_threshold_default |
Density lower threshold |
0.005 |
The default value of the lower threshold applied to the DensityFunction algorithm, set at discovery and can be updated per entity. |
splk_outliers_density_upper_threshold_default |
Density upper threshold |
0.005 |
The default value of the upper threshold applied to the DensityFunction algorithm, set at discovery and can be updated per entity. |
splk_outliers_alert_lower_threshold_volume_default |
Volume lower breached |
1 |
Alert when the lower bound threshold is breached for volume-based KPIs. |
splk_outliers_alert_upper_threshold_volume_default |
Volume upper breached |
0 |
Alert when the upper bound threshold is breached for volume-based KPIs. |
splk_outliers_alert_lower_threshold_latency_default |
Latency lower breached |
0 |
Alert when the lower bound threshold is breached for latency-based KPIs. |
splk_outliers_alert_upper_threshold_latency_default |
Latency upper breached |
1 |
Alert when the upper bound threshold is breached for latency-based KPIs. |
splk_outliers_detection_period_default |
Default period for calculation |
-30d |
The relative period used by default for outliers calculations, applied during entity discovery and can be updated per entity. |
splk_outliers_detection_period_latest_default |
Default latest time quantifier for calculation |
-1d |
The relative time quantifier for the latest time used by default for outliers calculations, applied during entity discovery and can be updated per entity. Defaults to -1d and can accept Splunk relative time quantifiers such as -1h@h. |
splk_outliers_detection_timefactor_default |
Default outliers time factor |
-30d |
The default time factor applied for the outliers dynamic thresholds calculation. Can be set to time-based factors like %H (by hour), %H%M (by hour/minutes), %w%H (by week day/hour), %w%H%M (by week day/hour/minutes), %w (by week day), or “none” (no time factor). |
splk_outliers_detection_latency_kpi_metric_default |
Default latency kpi metric |
None |
The default KPI metric for latency outliers detection. Can be set to None (disables it by default), splk.feeds.avg_latency_5m, splk.feeds.latest_latency_5m, splk.feeds.perc95_latency_5m, or splk.feeds.stdev_latency_5m. |
splk_outliers_detection_volume_kpi_metric_default |
Default volume kpi metric |
splk.feeds.avg_eventcount_5m |
The default KPI metric for volume outliers detection. |
splk_outliers_auto_correct |
Default auto correct |
1 |
When defining the model, enable or disable auto_correct by default, which uses the concept of auto correction based on min lower and upper deviation. |
splk_outliers_perc_min_lowerbound_deviation_default |
Perc min lower deviation |
5.0 |
If an outlier is not deviant (LowerBound) from at least that percentage of the current KPI value, it will be considered as a false positive. |
splk_outliers_perc_min_upperbound_deviation_default |
Perc min upper deviation |
5.0 |
If an outlier is not deviant (UpperBound) from at least that percentage of the current KPI value, it will be considered as a false positive. |
splk_outliers_mltk_algorithms_list |
List of selectable MLTK algorithms |
DensityFunction |
TrackMe uses the MLTK DensityFunction algorithm. You can add custom algorithms as a comma-separated list of values. These will become selectable automatically in the different Outliers configuration screens in TrackMe. |
splk_outliers_mltk_algorithms_default |
Default MLTK algorithm |
DensityFunction |
If you have multiple algorithms, you can define here which algorithm should be used by default when TrackMe defines the ML models rules, which happens usually at the entities discovery, or when adding/resetting ML models. |
splk_outliers_fit_extra_parameters |
fit_extra_parameters |
You can optionally add extra parameters to be added to the MLTK fit command (training phase) at the time of the definition of the ML rules (generally when entities are discovered), for instance: exclude_dist=”beta” to exclude Beta distributions for the density function. See MLTK documentation for more information. Default is empty for no extra parameters. |
|
splk_outliers_apply_extra_parameters |
apply_extra_parameters |
You can optionally add extra parameters to be added to the MLTK apply command (rendering phase) at the time of the definition of the ML rules (generally when entities are discovered), for instance: sample=”True”. See MLTK documentation for more information. Default is empty for no extra parameters. |
|
splk_outliers_boundaries_extraction_macro_default |
extract_boundaries_macro |
This defines the name of the boundaries extraction macro which is used when defining ML models rules, usually at the time of the entity discovery or when defining a new model. Default is empty. |
|
splk_outliers_boundaries_extraction_macros_list |
extract_boundaries_macros_list |
This defines the list of boundaries macros. If you need to define a custom macro to extract boundaries according to a custom algorithm, you can add a comma-separated list of macros which will become automatically selectable in TrackMe Outliers management screens. Default is empty. |
|
splk_outliers_static_lower_threshold_default |
Static lowerBound Threshold |
You can define a default value for the static lowerBound threshold. If defined, this overrides the calculated lowerBound. Default is empty. |
|
splk_outliers_static_upper_threshold_default |
Static upperBound Threshold |
You can define a default value for the static upperBound threshold. If defined, this overrides the calculated upperBound. Default is empty. |
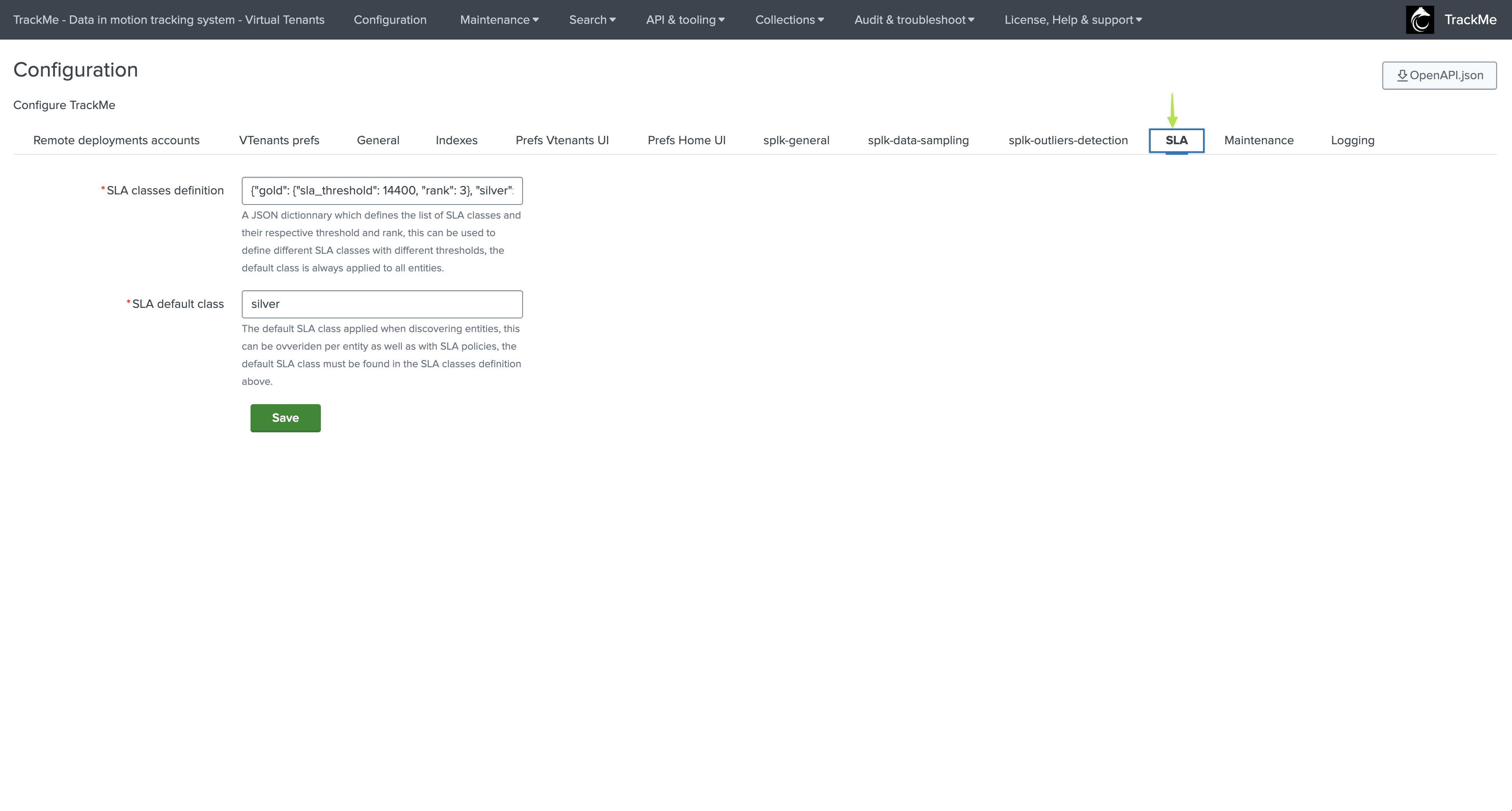
SLA configuration
This tab defines various options specific to the SLA feature:
Field |
Label |
Default Value |
Description |
|---|---|---|---|
sla_classes |
SLA classes definition |
{“gold”: {“sla_threshold”: 14400, “rank”: 3}, “silver”: {“sla_threshold”: 86400, “rank”: 2}, “platinum”: {“sla_threshold”: 172800, “rank”: 1}} |
A JSON dictionary which defines the list of SLA classes and their respective threshold and rank; this can be used to define different SLA classes with different thresholds, the default class is always applied to all entities. |
sla_default_class |
SLA default class |
silver |
The default SLA class applied when discovering entities. This can be overridden per entity as well as with SLA policies. The default SLA class must be found in the SLA classes definition above. |
sla_breaches_events_frequency |
SLA breaches gen events frequency |
604800 |
The frequency in seconds at which SLA breaches events are generated (sourcetype=trackme:sla_breaches). Default is 604800 (7 days). SLA breaches events are generated only when the SLA is breached for a given entity, and can be used for alerting purposes, notably to generate update notifications in TrackMe StateFul alerts. Set the value to 0 to disable generating SLA breaches events. |
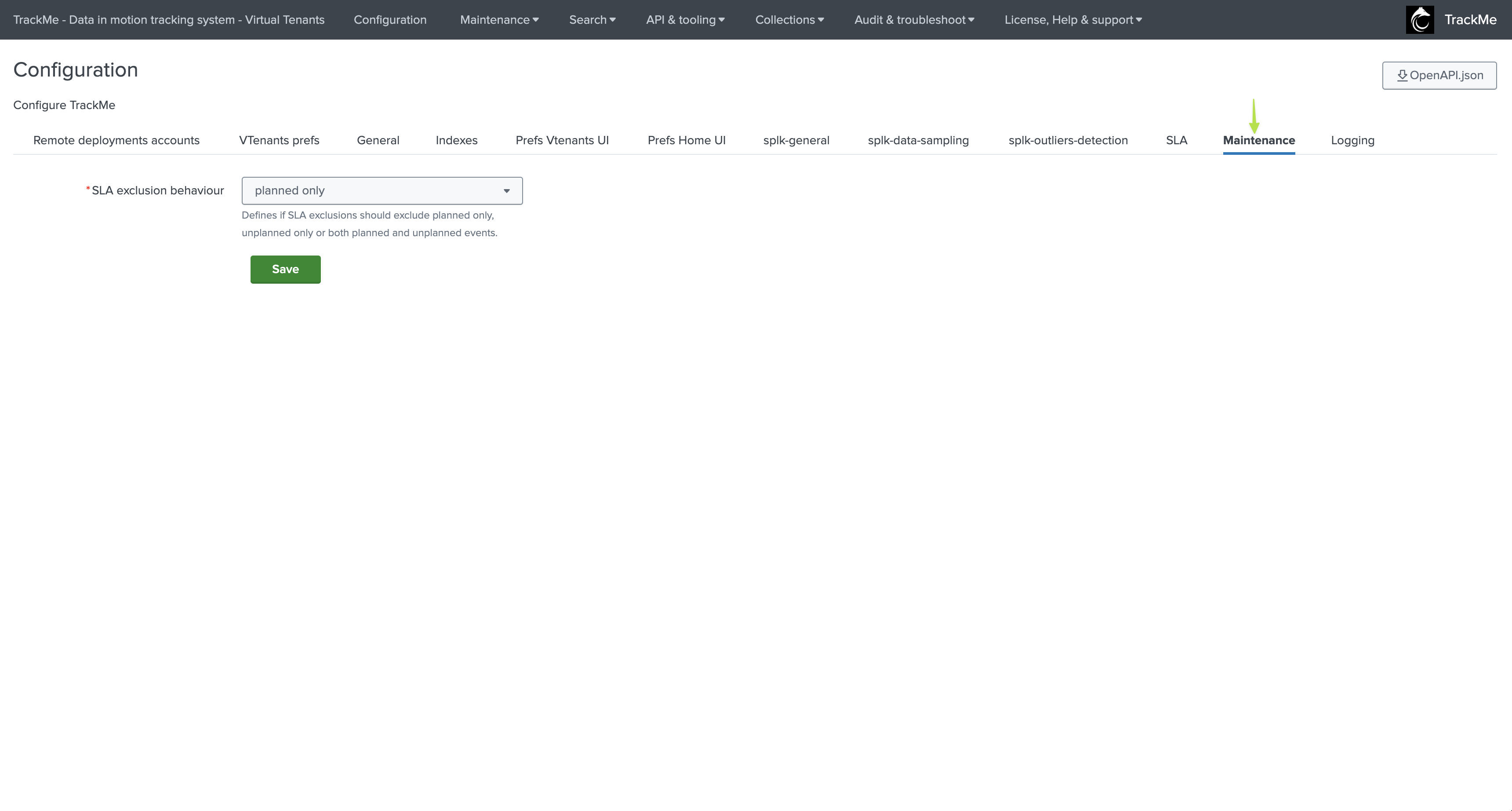
Maintenance
This tab defines various options specific to the Maintenance feature:
Field |
Label |
Default Value |
Description |
|---|---|---|---|
maintenance_kdb_exclusion_behaviour |
SLA exclusion behaviour |
planned |
Defines if SLA exclusions should exclude planned only, unplanned only, or both planned and unplanned events. Options: any (planned/unplanned), planned only, or unplanned only. |
TrackMe Logging
This tab defines the logging level for TrackMe, all custom commands, REST endpoints, and any other TrackMe components rely on this setting to define the level of logging:
It is not recommended in a Production context to set TrackMe in DEBUG mode in normal circumstances as TrackMe will be extremely chatty in debug.
A typical logging message will look like: (INFO mode in this example)
2023-01-10 17:22:04,520 INFO trackmesplkflxparse.py stream 366 tenant_id="flx-demo-dma", context="live", TrackMeSplkFlxParse has terminated successfully, turn debug mode on for more details, results_count="2"
The logging level is extracted at search time, via props.conf settings, example:
# catch all sourcetype
[(?::){0}trackme:custom_commands:*]
EXTRACT-log_level = \d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}\,\d*\s(?<log_level>\w*)\s
Therefore, you can review errors for instance with the following SPL search which would review both REST API endpoints errors and the custom commands:
(index=_internal sourcetype=trackme:rest_api log_level=ERROR) OR (index=_internal sourcetype=trackme:custom_commands:* log_level=ERROR)
We strongly believe that the truth stands in the logs; therefore, we take great care at making sure logging in TrackMe is giving you the greatest level of quality and reliability!
See the following documentation for more about logging & troubleshooting in TrackMe: