splk-feeds - Creating and Managing Hybrid Trackers
Introduction to Hybrid Trackers
Hybrid Trackers are created and managed through TrackMe. These are scheduled backend jobs that orchestrate entity discovery and management for TrackMe splk-feeds components:
Hybrid Trackers are scheduled reports that involve various TrackMe backend tools depending on the TrackMe component
A single Hybrid Tracker can discover and manage a few or many entities according to the needs
Hybrid Trackers integrate into a main application workflow, which involves concepts such as registering their execution statuses and run time performance
Hybrid Trackers can be created at any time through guided user interfaces or TrackMe REST endpoints
In the context of Splunk feeds tracking, Hybrid Trackers can also be created during the initial creation of the Virtual Tenant
When creating trackers, the related knowledge objects will be owned by the owner defined at the Virtual Tenant level
TrackMe keeps records of the knowledge objects related to the Hybrid Trackers; therefore, you need to manage their lifecycle through TrackMe
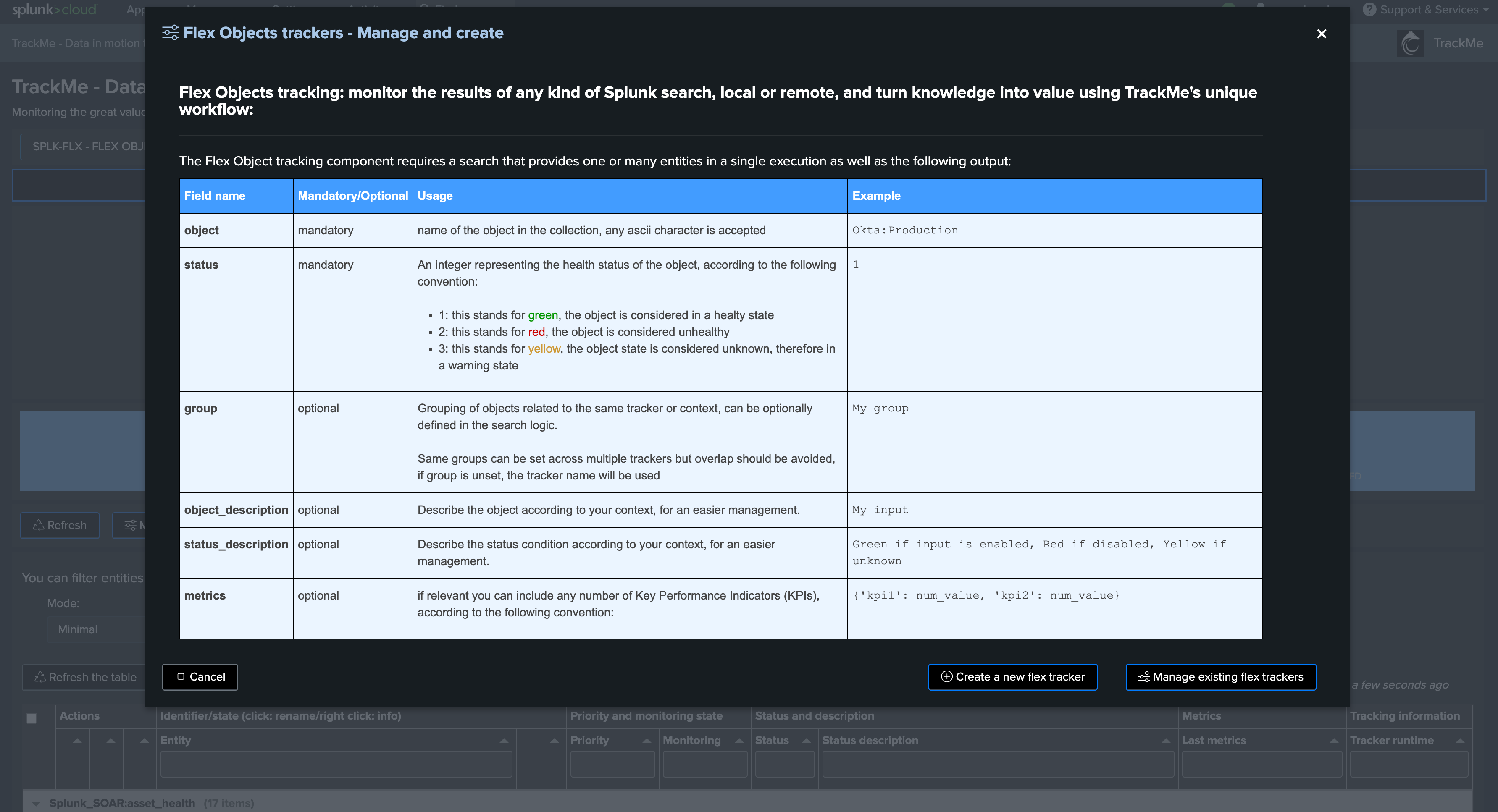
Creating an Hybrid Tracker for splk-feeds
These instructions are related to the splk-dsm component. Options for splk-dhm/splk-mhm may differ, but the underlying logic is similar.
To create a new Hybrid Tracker, access the tenant and click on “Manage: Hybrid Trackers”:
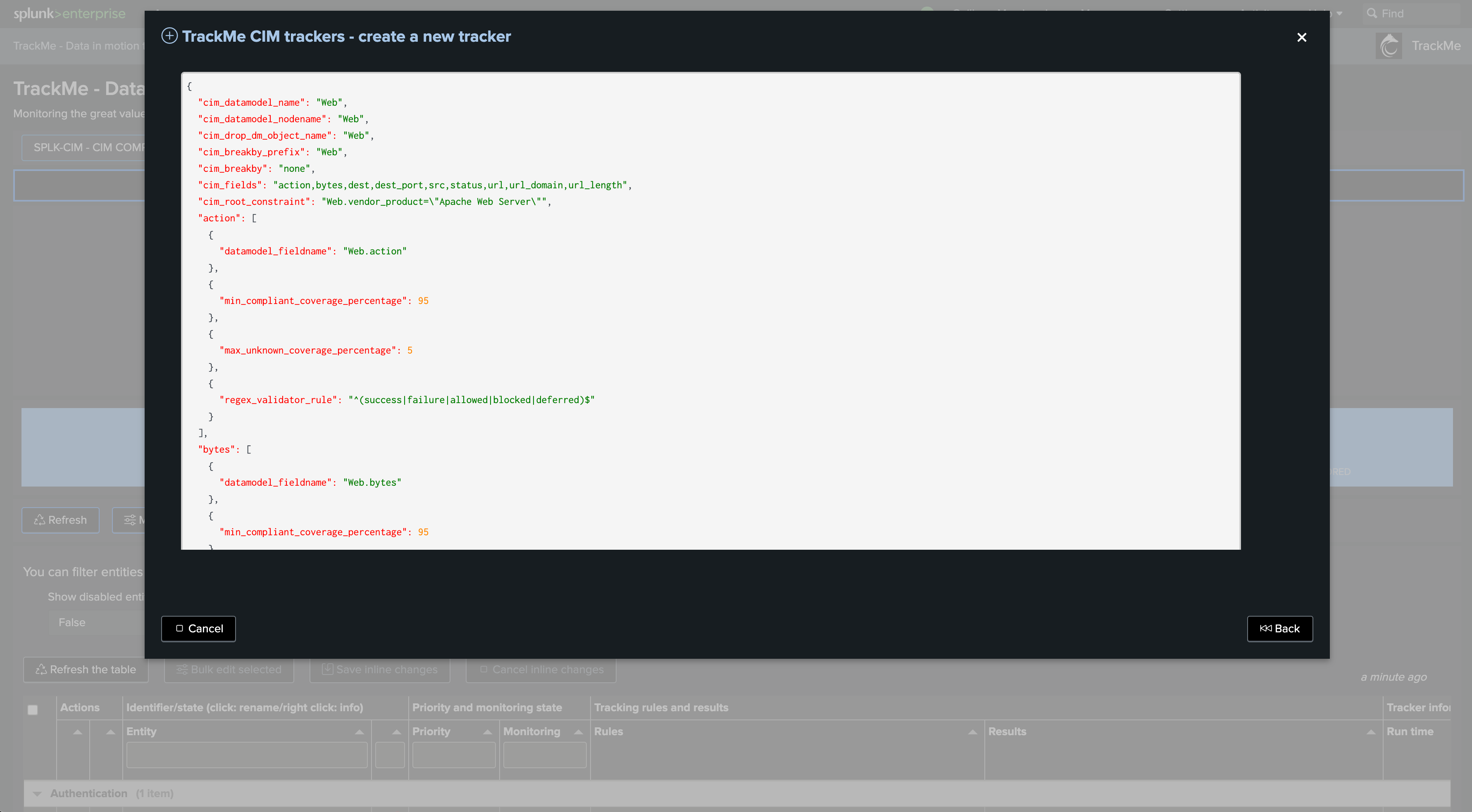
splk-dsm Hybrid Tracker creation wizard:
Once in the creation wizard, follow the guided steps:
Hybrid Tracker identifier:
Provide a name for the Hybrid Tracker. This will be included in the name of the Splunk Knowledge Objects related to this tracker
In the example below, we will name our tracker “endpoints_os_data” as it deals with events originating from Operating Systems
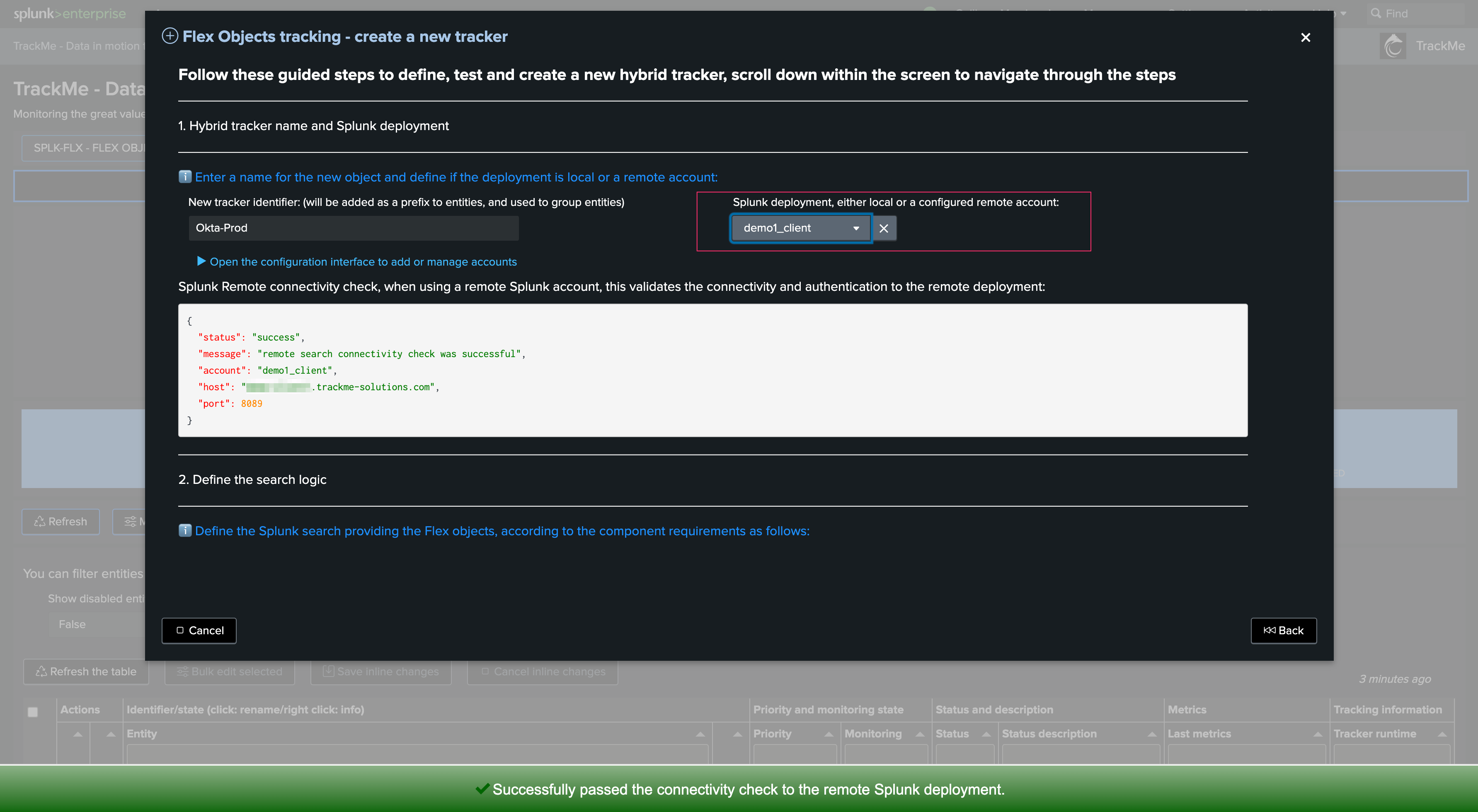
Target Splunk deployment:
Specify whether the data is searchable locally on the Splunk deployment or if the trackers deal with a remote Splunk deployment
If a remote Splunk deployment is selected, TrackMe performs a connectivity check to that environment first
Search mode and search root constraint:
tstats versus raw
Then, define the search mode. You can choose between tstats and raw
tstats is generally recommended as it provides much faster and more efficient searches relying on Splunk tsidx files
However, tstats requires all fields to be indexed fields, while a raw search can deal with search-time extracted fields
Therefore, raw search provides much more flexibility, but the cost is also much higher
Depending on your context, raw searches may be fully valid, but if a tstats search can be used equally, use tstats
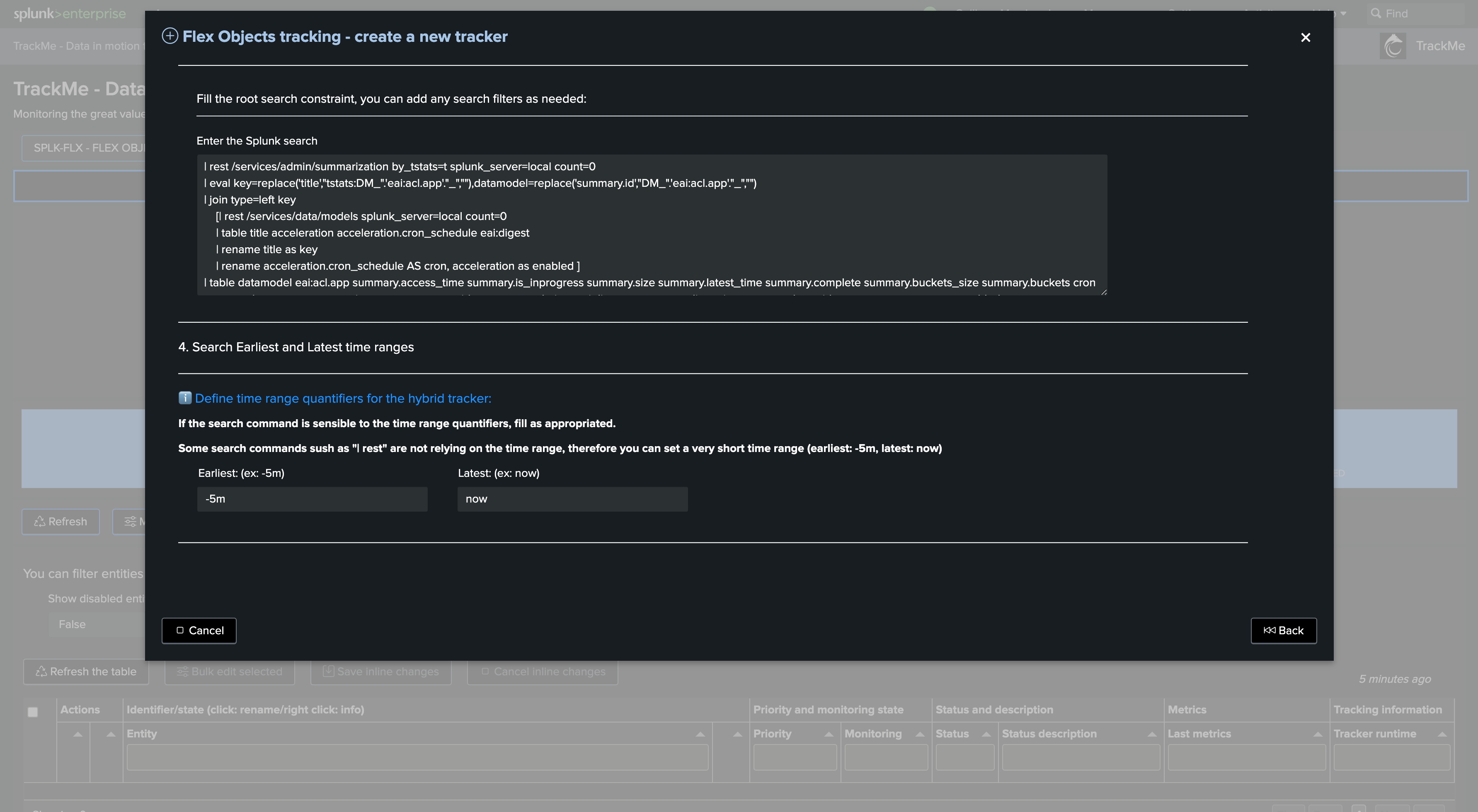
root search constraint:
Define the Splunk root search constraint. The constraint comes pre-filled with normally expected constraints which require valid data, exclude TrackMe related items, etc.
Add your own search filters according to your needs. In our example, we add an index filter “(index=linux* OR index=win*)”
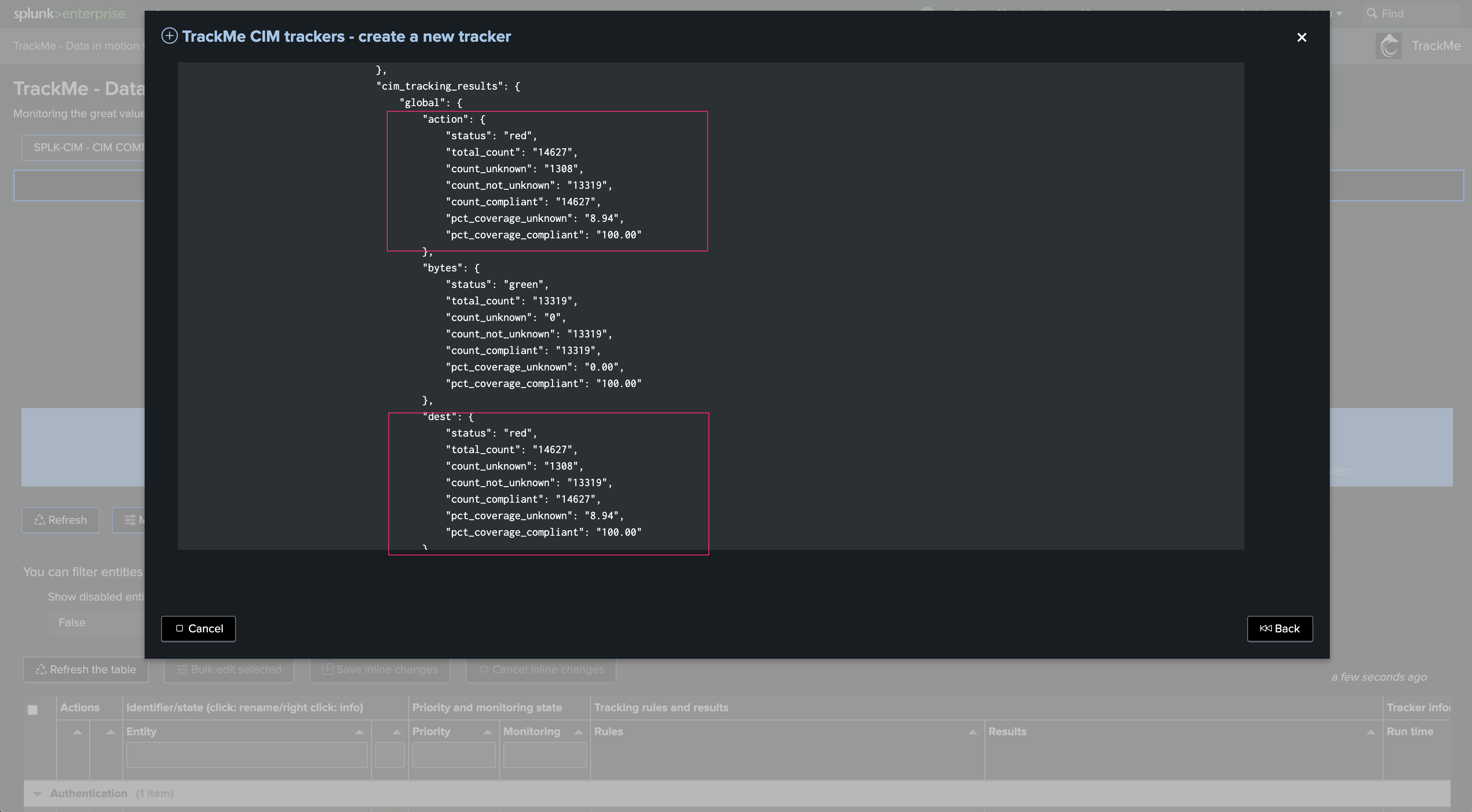
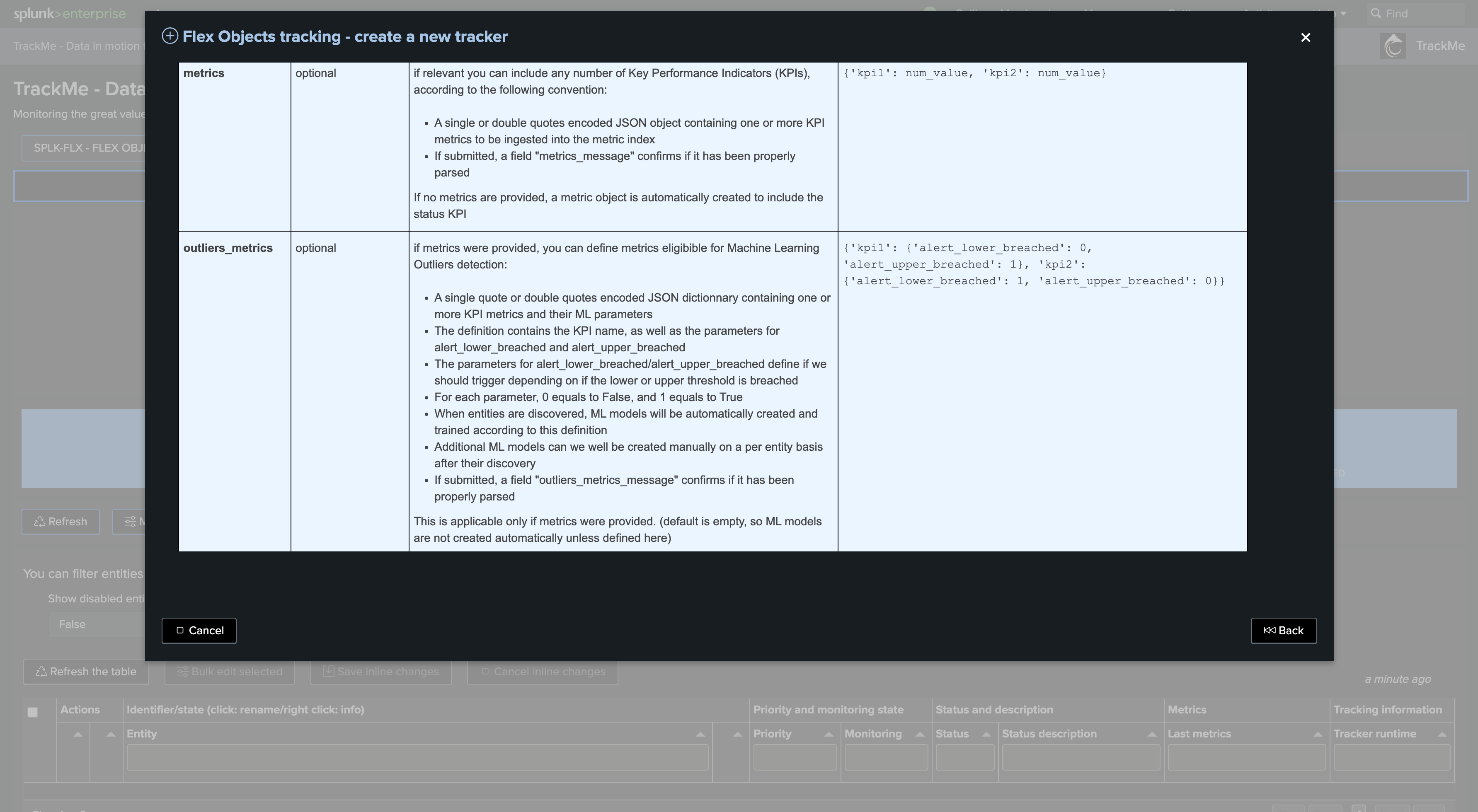
break by logic:
You can optionally add an additional break by logic field
This defaults to “none,” which means entities are going to match the combo
index + ":" + sourcetypeFor instance, if we have an indexed field
region, we can leverage it here to distinguish entities per region. Our entity creation logic becomesindex + ":" + sourcetype + ":" + region

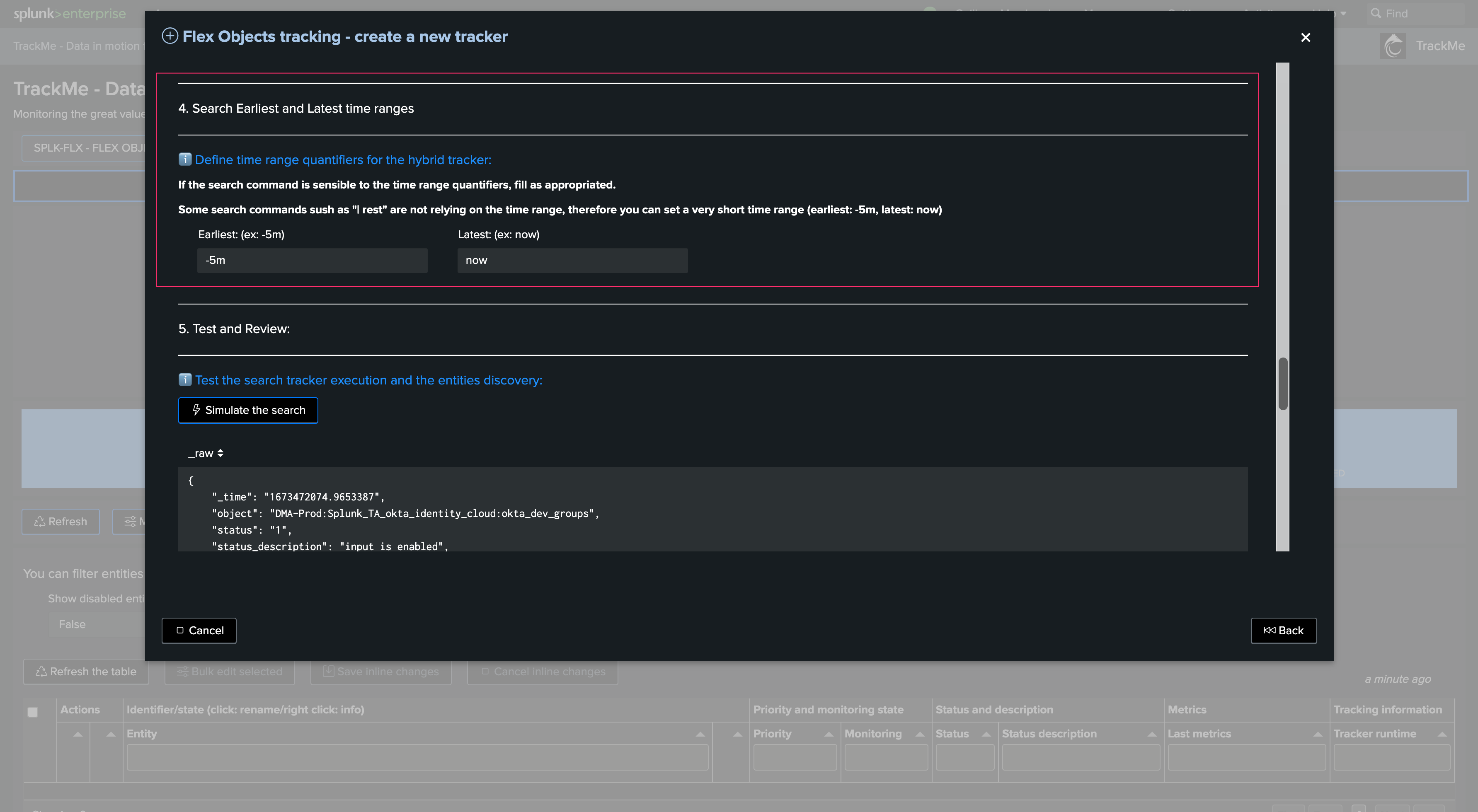
Time quantifiers:
Review and update if necessary the indexed time earliest and latest, as well as time range earliest and latest
These time quantifiers drive the period of data that the tracker is going to cover
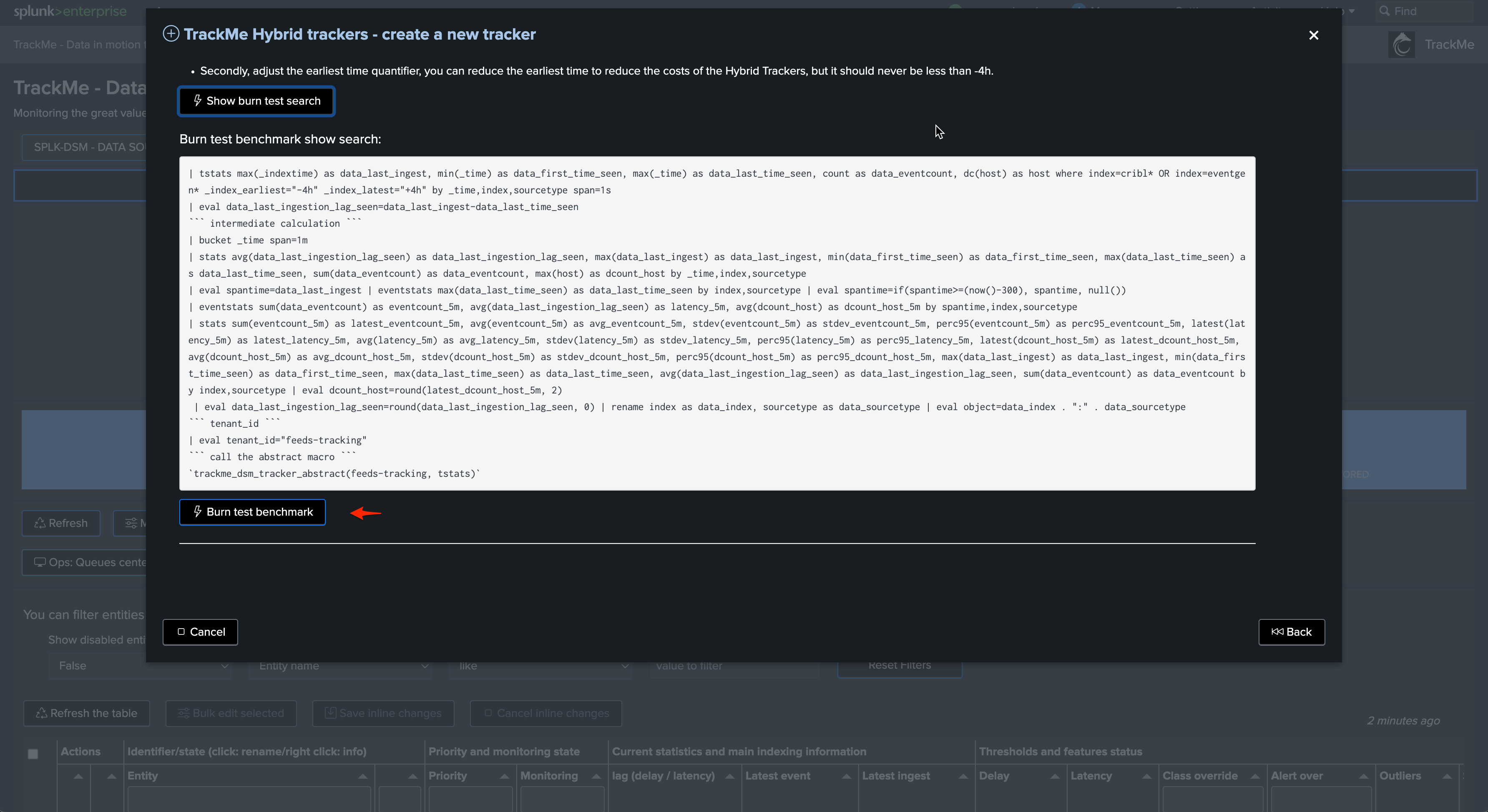
Generally, you will want to have a large event time range period to cover data with high latency, while the period for indexed time range can be more restricted for performance optimization purposes
What will work best and be the most efficient depends a lot on your context and environment. Start with these values, review and adapt if necessary
Cron schedule:
Define the cron schedule for the Hybrid Tracker
It defaults to every 5 minutes. Note that TrackMe will automatically dispatch cron schedules for optimization purposes
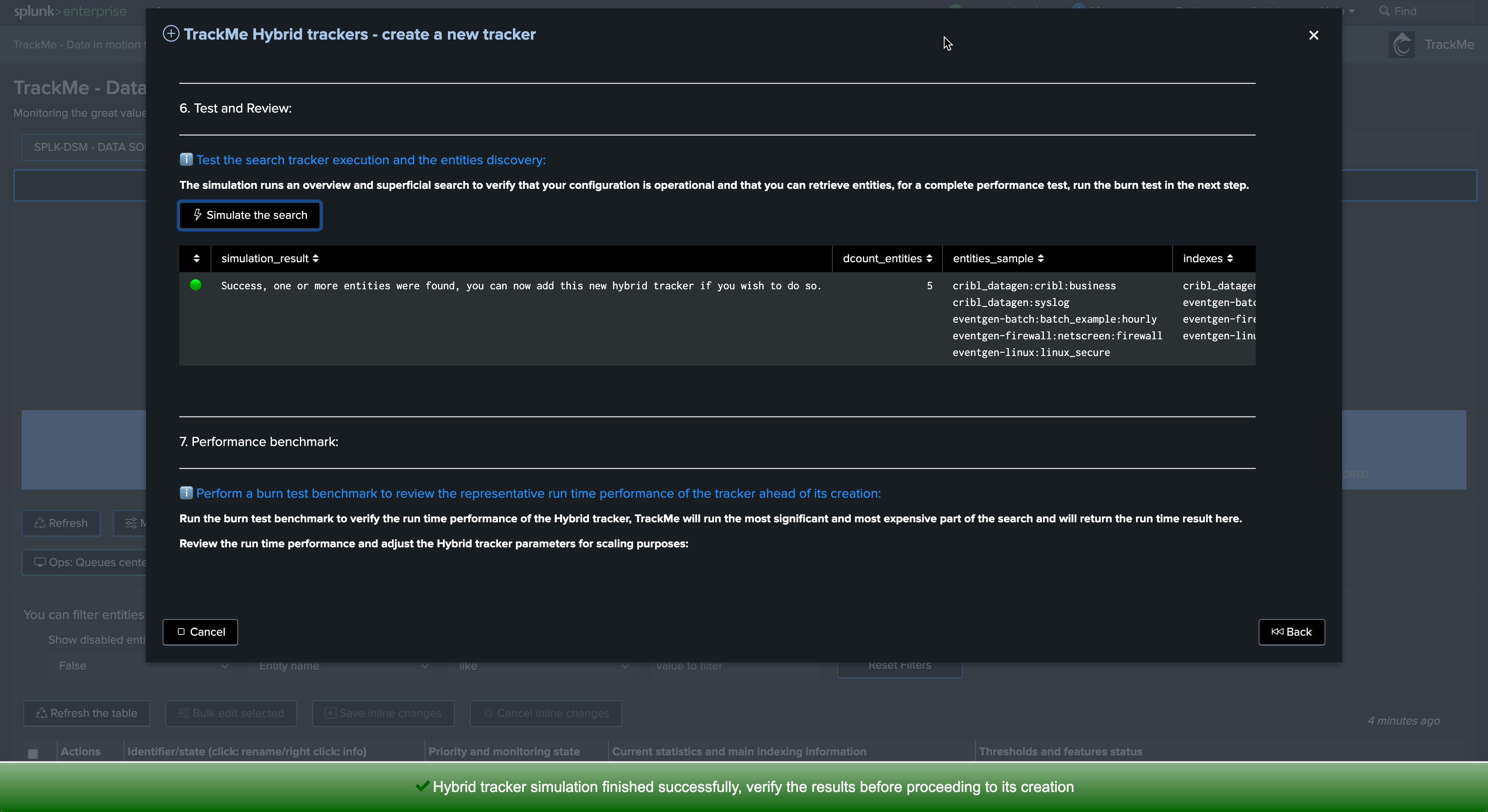
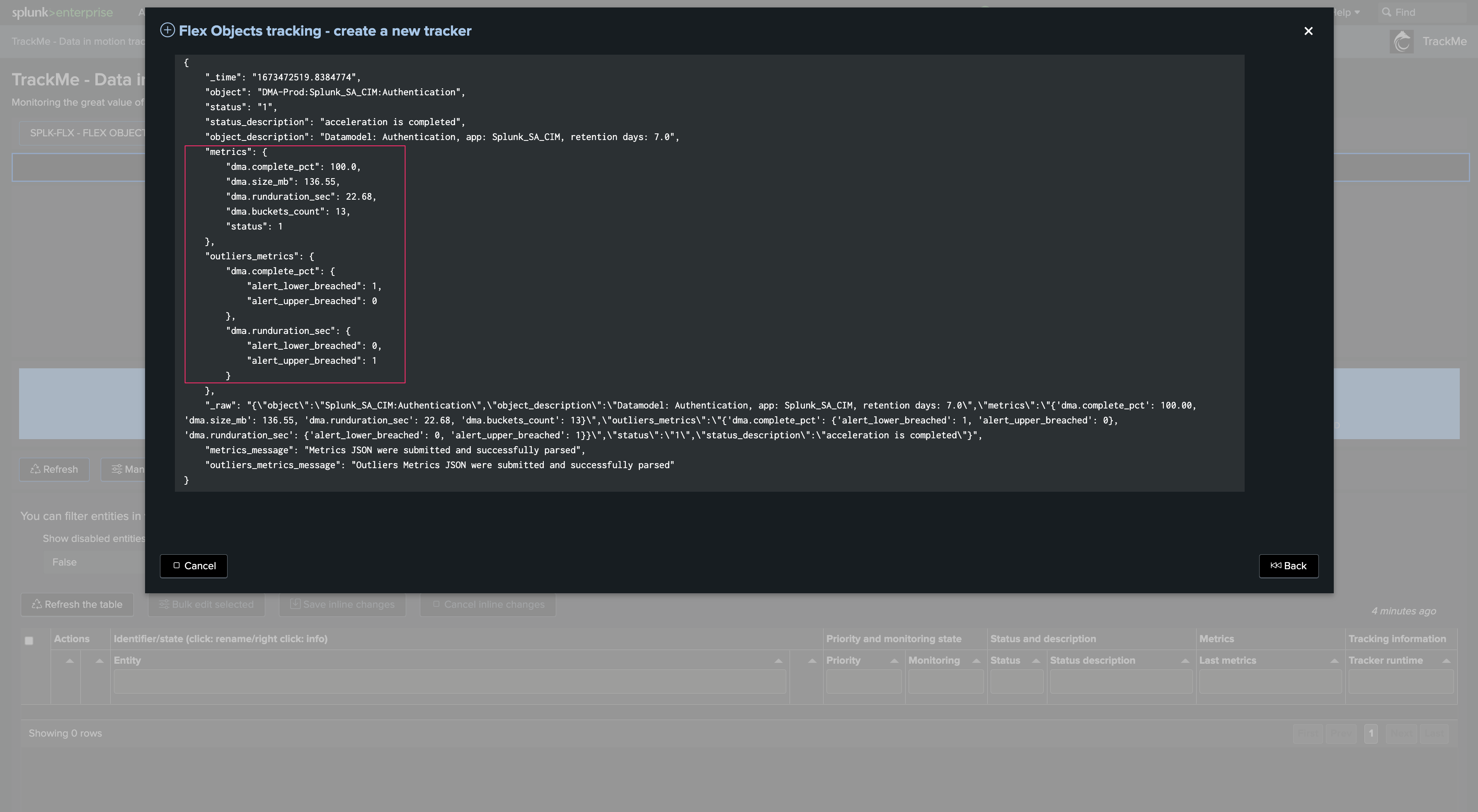
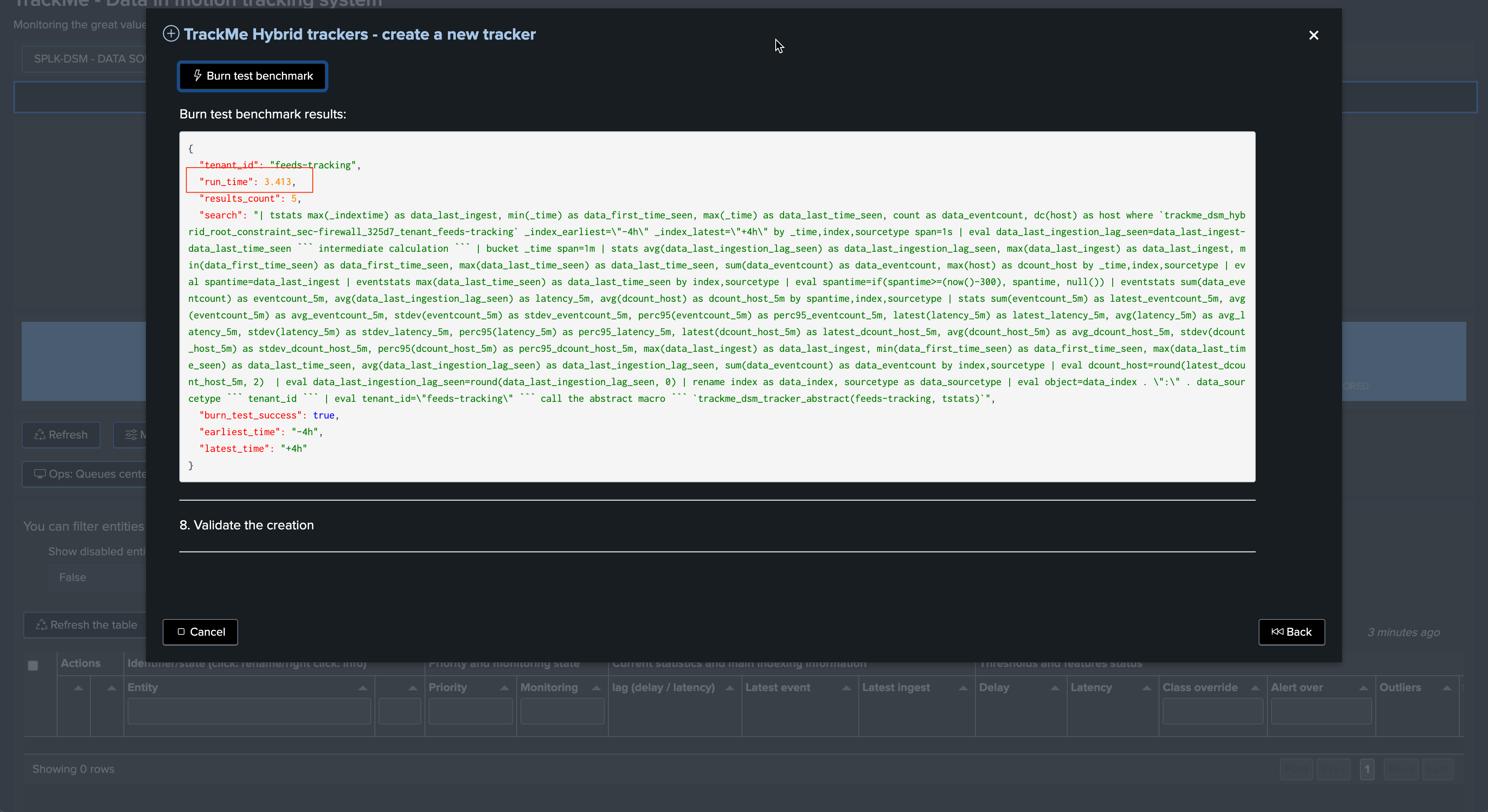
Test and review:
Click on the button to execute the Hybrid Tracker in preview
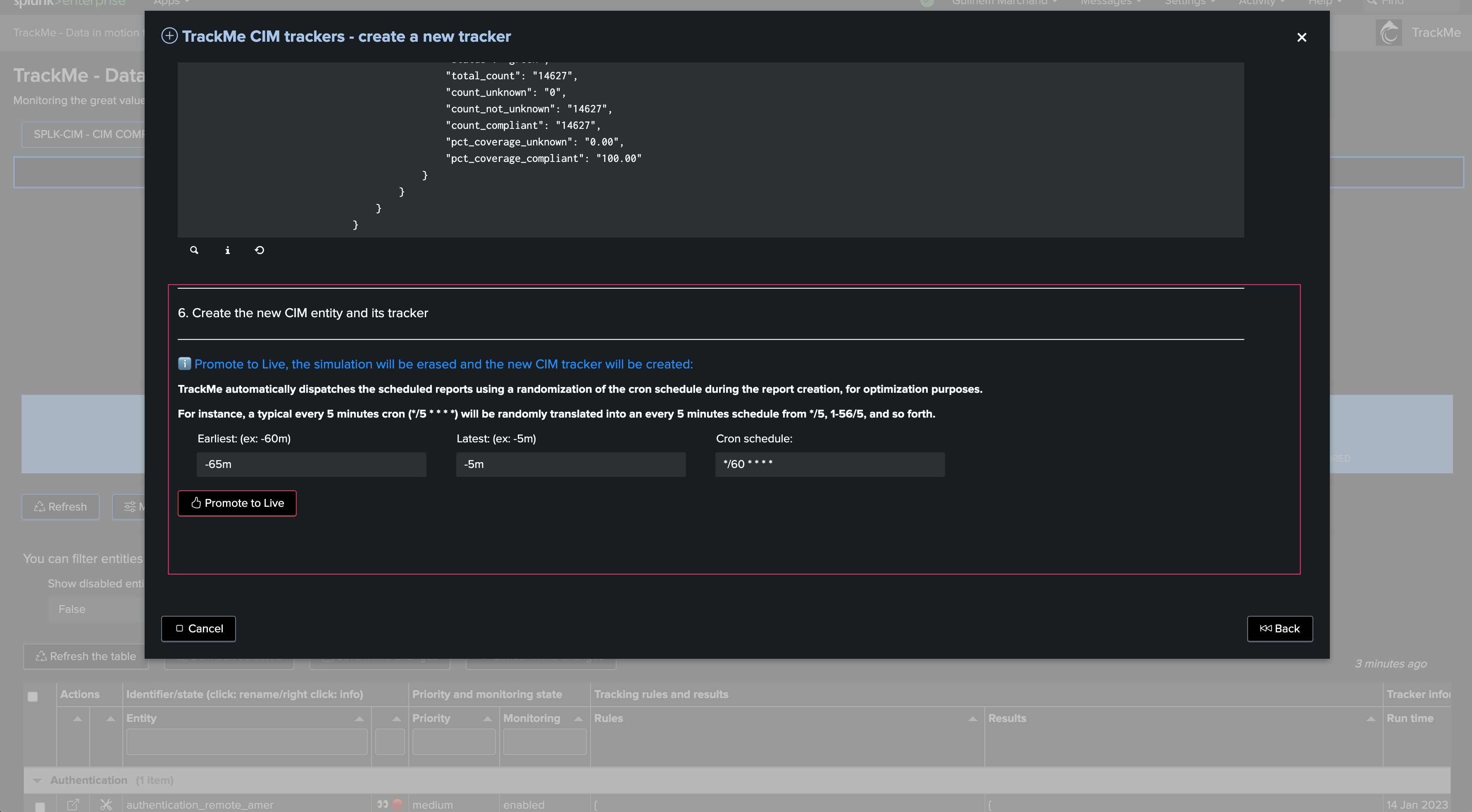
Finally, validate the Hybrid Tracker creation:
Once created, you can choose to run the Tracker immediately to discover and create entities in the Virtual Tenant:
Managing Hybrid Trackers for splk-feeds
Deleting an Hybrid Tracker through the UI
If you want to delete an existing Hybrid Tracker, this operation must be done via TrackMe.
The reason is that the application keeps track of all knowledge objects that were created for a given tenant to honor various features such as managing the lifecycle of the tenant (enabling/disabling, etc.) or the lifecycle of the tracker itself.
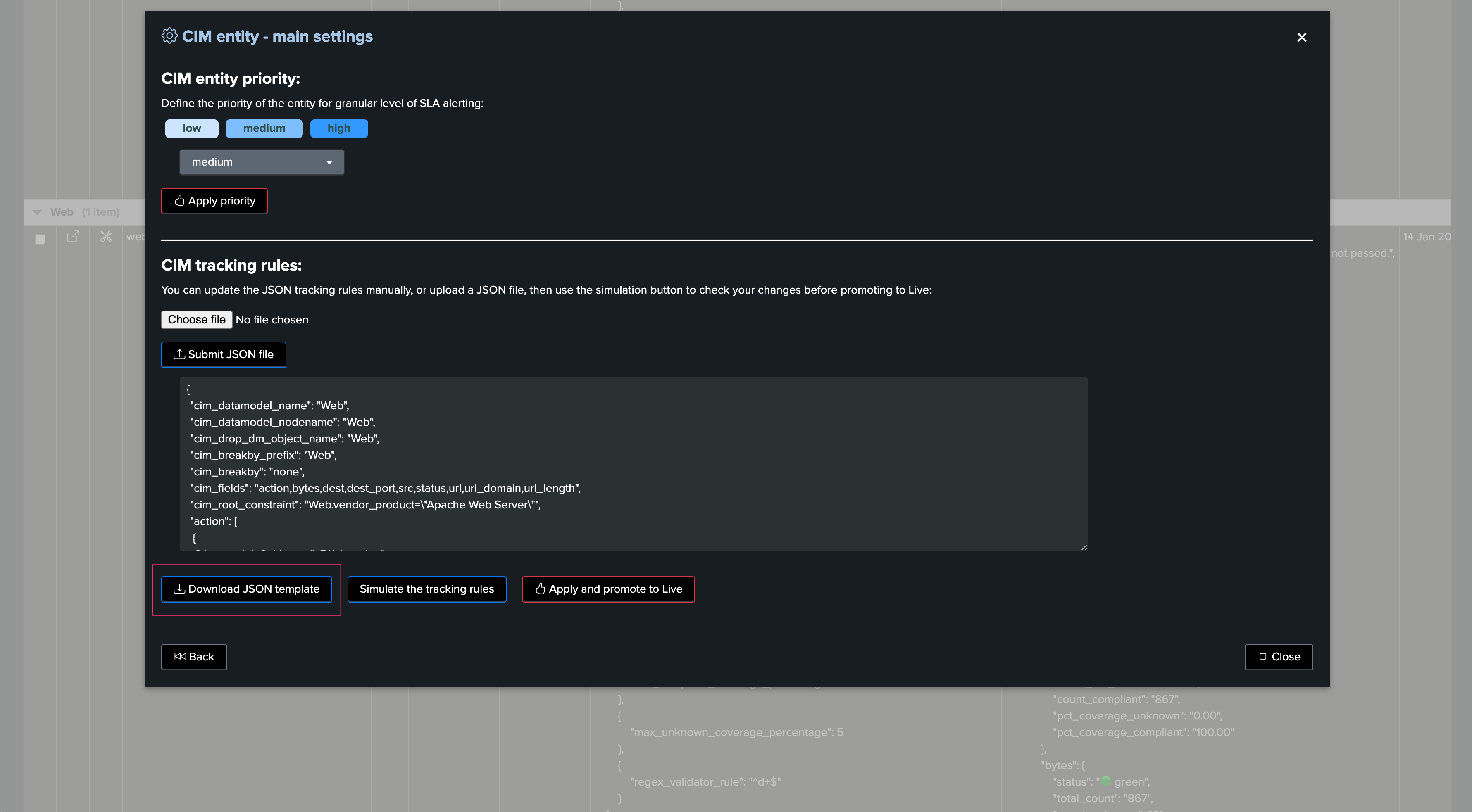
To manage Hybrid Trackers, click on:
The user interface shows available trackers and their related objects:
Select one or more trackers to be deleted:
The related knowledge objects will be deleted, and the Virtual Tenant record will be cleaned up automatically.
For splk-feeds, the entities that were created through these Hybrid Trackers will not be deleted. (However, unless another Tracker is created, these will not be maintained anymore)
Deleting an Hybrid Tracker through REST
You can delete a Tracker through the following REST endpoint, example in SPL:
| trackme mode=post url="/services/trackme/v2/splk_hybrid_trackers/admin/hybrid_tracker_delete" body="{'tenant_id': 'mytenant', 'component': 'dsm', 'hybrid_trackers_list': 'test:001,test:002'}"